XSL/XSLTを利用したデータの変換と整列:VBScriptでXMLプログラミング(3)(2/4 ページ)
XSLTを利用するメリットとは?
前章で解説したように、XSLTを利用したデータ変換にはさまざまなメリットが存在します。スキーマの相違やデータモデルの変更に対しての耐性を強化することもできますし、複雑なコードによるミスをロジックの分離を行っていくことで実現することもできます。
例えば、これまで紹介してきたDOMの利用によるデータの変換を考えていくことにしましょう。
単純なXML文書の形式を変更したいと思ったとき、どのようなコードを書くことになるのでしょうか。リスト1とリスト2は、そのようなときに記述されるであろうコードの例(一部)です。
<?xml version="1.0"?> |
| リスト1 XML文書の例 |
import org.w3c.org.*; |
| リスト2 DOMを利用したデータ変換のためのコード(一部) (この例では、言語にJavaを利用しています) |
この例からも分かるように、ドキュメントを取得し、データの内容に応じて値を取得し、新しいドキュメントに対して書き出しを行うという作業になります。このようなコードがアプリケーションのビジネスロジックに含まれているということは、データモデルの変更に対して柔軟に対応を行うことが難しくなります。つまり、変更が行われるたびに何度もこのロジックを修正しなければならなくなり、また、それによるミスが起こる可能性も出てきます。
そこで、利用を検討したいのがXSLTです。
XSLTは、端的にいうと与えられたXML文書に対しての変換ロジックを記述しておくことができる標準仕様です。このXSLTを処理できるプロセッサ(パーサ)に実行を任せることによって、上記のような長いコードを記述しなくともドキュメントの変換を実現することができます。
このXSLTを利用して処理を実行するような形式で設計しておくと、XSLTファイルの交換によっていかようにでもXML文書の変換を行うことができます。図1は、この様子をイメージ化したものです。
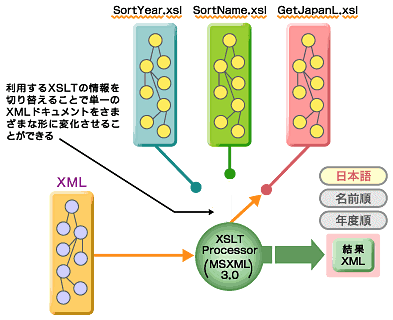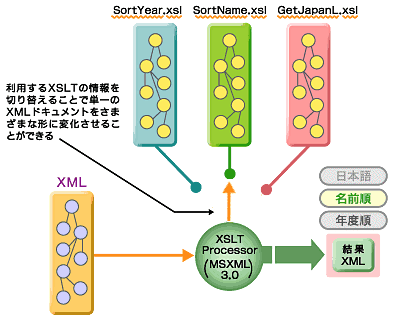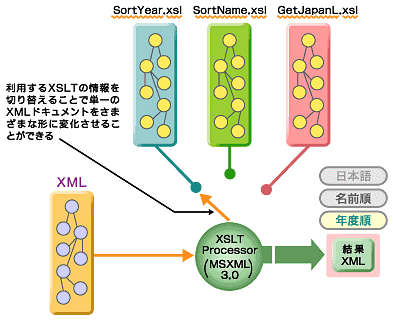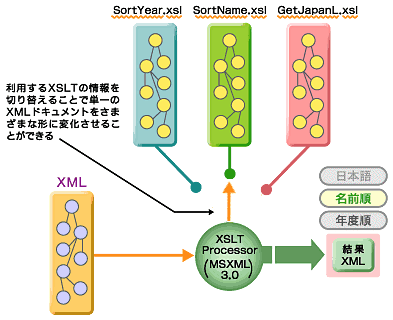 図1 XSLTを利用したXML文書変換のイメージ
図1 XSLTを利用したXML文書変換のイメージ単一のXML文書から、幾つかの形式に変換できるため、さまざまな形での再利用を行うことも考えられるでしょう。
では、実際にこのような方法を用いたXML文書の変換を考えていくことにしましょう。なお、Microsoft XML Parser 3.0では、W3Cで勧告されたXSLT 1.0の仕様に準拠した実装がなされています。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。