第6章 変数と値型・参照型:連載 改訂版 C#入門(3/3 ページ)
6-7 第6行目の出力の答え
22: int testInt1,testInt2;
・・・
39: testClass2a = testClass1a;
・・・
56: object testObject1,testObject2;
57: testObject1 = 123;
58: testObject2 = testObject1;
59: testObject1 = 456;
60: Console.WriteLine( "Answer6 testObject1={0}, testObject2={1}", testObject1, testObject2 );
さて、前章で紹介したボックス化機能を使ったのが「第6行目の出力」である。「第6行目の出力」は、56〜60行目の処理によって出力される。
「第6行目の出力」は「第1行目の出力」とそっくりである。変数名の違いは、例によって機能には関係ない。本質的な相違は、「第1行目の出力」のほうが22行目でint型の変数を宣言しているのに対して、「第6行目の出力」のほうでは56行目でobject型の変数を宣言していることにある。object型は、すでに述べたとおりSystem.Objectの別名で、すべてのクラスのスーパークラスとなる究極の基本クラスである。つまり、object型は参照型である。
ここまで読んできた読者であれば、ここでピンとくると思う。object型は参照型であり、int型は値型なので、「第1行目の出力」と「第6行目の出力」では、表面的に似ていても挙動は違うはずである。まさにそのとおりで、表面的にソース・コードが似ているだけで、処理される内容はまったく似ても似つかない。
次にピンとくるのは、「参照型なのにnewがない」ということだろう。このソース・コードが実行可能だとすれば、インスタンスを作成するための機能がどこかになければならないはずだ。newキーワードなしで動作しているとすれば、56〜60行目のどこかにnewに相当する機能が隠れているはずである。問題は、それが何個かということだ。1個なら「第3行目の出力」に相当する結果になるだろうし、2個なら「第2行目の出力」に相当する結果になるのではないか、と予測することができる。
では、実際に何が起きているのかを順番に見てみよう。ボックス化は暗黙のうちに実行される処理が多いので1行ずつ見ていきたいと思う。まず、57行目では、int型整数の「123」という値をobject型の変数に入れようとしている。このような値型を参照型として使おうとする状況があると、コンパイラはボックス化処理を自動的に挿入する。その結果、整数型の変数を包み込むクラスが見えないところで準備され、そのインスタンスが自動的に作成され、ここでは「123」という値が書き込まれる。そして、そのインスタンスへの参照が変数testObject1に代入されるのである。つまり、57行目でnew相当の機能が1回実行されたのである。さて、次の58行目で行われている代入は、参照型と参照型の代入であり、ボックス化のような機能は入らない。つまり、「第3行目の出力」の39行目とまったく同じ機能である。この代入が行われた時点で、testObject1とtestObject2は同じインスタンスを指し示していることになる。このまま終われば、「第3行目の出力」と同じ結果になるのだが、まだまだ逆転の可能性がある。
「第6行目の出力」を理解するうえで最大のポイントは59行目である。もちろん、59行目に書かれた内容は57行目と数値の値以外は同じであり、まったく同じことが行われる。こう書くと簡単だが、これによって大逆転が起こるのである。つまり、「第3行目の出力」とは同じ結果にならないのである。59行目では、「456」という整数値をボックス化して、整数値を包み込むクラスのインスタンスを作成する。つまり、newに相当する機能が実行されるのである。その結果、インスタンスは2つに増え、それぞれが別々の値を保持することになる。そして、2つの変数がそれぞれ別々のインスタンスを参照しているので、出力結果の数値は、「456」と「123」となる。結果だけ見ると、第1〜2、第4〜5行目の出力と同じに見えるが挙動はまったく異なっていることに注意が必要だ。
以上で終わりである。表面的には「第3行目の出力」以外はすべて同じに見えるが、内部的な動作はまったく異なっている。最終的に「456」と「123」という値に落ち着くにせよ、落ち着くまでのプロセスが異なっているのである。本章のプログラムは分かりやすさを尊重するため、きわめてシンプルに仕上げたので、これぐらいなら何となく書いても問題ないと思われたかもしれない。しかし、実際に開発の現場で書かれるプログラムは、複雑に込み入ったものにならざるをえない。そこで発生するトラブルを解析して、問題点を突き止めるには、本章で述べたような内部での正確なデータの挙動を知っている必要がある。そして何より、値型と参照型の区別を正しく扱えるようになれば、より少ないメモリでより素早く実行するプログラムが作成できるのである。
念のために、実際に実行した結果をFig.6-1に示す。
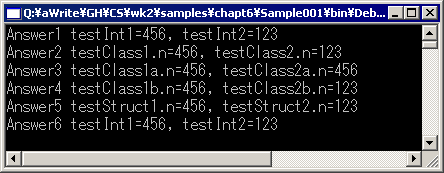 Fig.6-1
Fig.6-1Column - メソッド引数のref、outキーワード -
メソッドの引数には、refおよびoutというキーワードを付加することができる。それぞれ、参照引数、出力引数を意味する。何もせず、通常の方法で引数を記述すると、引数は参照ではなく値を渡す。参照型の変数であっても、参照型の変数への参照が渡されるわけではなく、変数に格納された参照情報の値が渡されるだけである。その結果、引数に変数名を書いたとしても、その変数の値を書き換えることはない。つまり、「object a = A; instance.method( a );」のようにソースを書いたとき、インスタンスAへの参照が渡るだけであり、変数aへの参照は渡らないということである。その結果、変数aを書き換えるようなメソッド「method」は記述できない。しかし、refやoutキーワードを用いれば、引数に記述された変数を書き換えるようなメソッドを記述することが可能となる。
以下は、ref、outキーワードを用いたメソッドを記述した例である。主要なエラーや警告が出る行はコメントアウトしてある。
1: using System;
2:
3: namespace Sample002
4: {
5: class Class1
6: {
7: private static void sample1( int x )
8: {
9: x ++;
10: }
11: private static void sample2( ref int x )
12: {
13: x ++;
14: }
15: private static void sample3( out int x )
16: {
17: // x ++;
// 未割り当てのローカル変数 'x' が使用されました。
18: x = 123;
19: }
20: [STAThread]
21: static void Main(string[] args)
22: {
23: int a = 0, b;
24: sample1(a);
25: // sample1(b);
// 未割り当てのローカル変数 'b' が使用されました。
26: sample1(1);
27: Console.WriteLine(a);
28: // Console.WriteLine(b);
// 未割り当てのローカル変数 'b' が使用されました。
29:
30: int c = 0, d;
31: sample2(ref c);
32: // sample2(ref d);
// 未割り当てのローカル変数 'd' が使用されました。
33: // sample2(ref 1);
// ref または out 引数は左辺値でなければなりません。
34: Console.WriteLine(c);
35: // Console.WriteLine(d);
// 未割り当てのローカル変数 'd' が使用されました。
36:
37: int e = 0, f;
38: sample3(out e);
39: sample3(out f);
40: // sample3(out 1);
// ref または out 引数は左辺値でなければなりません。
41: Console.WriteLine(e);
42: Console.WriteLine(f);
43: }
44: }
45: }
これを実行すると以下のようになる。
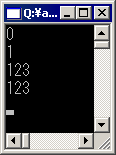
7〜10行目のメソッドは、通常の引数を用いたメソッドである。11〜14行目は、refキーワードを用いた引数を持つメソッドである。15〜19行目はoutキーワードを用いた引数を持つメソッドである。それぞれ、引数のデータ型(int)の手前に、refやoutキーワードが付加されていることが分かるだろう。
さて、Mainメソッドの中で、23〜28行目の挙動についてはあらためて説明する必要はないだろう。9行目で引数に1を足しているが、その計算はいっさいMainメソッドの変数には反映されていない。問題は、30行目以降の挙動だ。31行目では、refキーワードを用いたメソッドに、変数cを渡している。実行画面を見ると分かるとおり、34行目で出力されている値は「1」であり、13行目で1を足した結果が変数cにも反映されていることが分かるだろう。13行目でxとなっている部分は、実際には変数cへの参照が格納されており、これに1を足すということは、変数cに1を足すことになるのである。注目すべき点が、ほかに2つある。1つは、32行目のように、初期化していない変数を渡そうとすると警告されることである。つまり、refキーワードは、何かの値の入った変数を渡すための機能なのである。もう1つは、33行目のように、変数ではなく数値を渡そうとするとエラーになることである。変数には具体的な格納場所が存在するので参照することができるが、定数値にはそのような特定の場所がないので、参照することはできない。なお、Visual Basicでは、ByRefキーワードがC#のrefキーワードと似た効能を持つが、ByRefキーワードの付いた引数で定数値を渡すことができる。この点で動作が異なるので、Visual Basicプログラマーは注意しよう。
次はoutキーワードの例である。17行目のように、引数の値を利用することはできない。引数には代入することはできるが、もともと何かの値が入っていると期待して処理することはできない。それは、37行目以降を見ても明らかだろう。ほかの例では、初期化していない変数を渡すことはできないが、outキーワードを使った場合に限っては、何の値も入れていない変数を渡しても問題はない。つまり、outキーワードはrefキーワードと似ているが、メソッドにより変数に何かの値を入れてもらう用途専用だといえる。この点で、outキーワードとrefキーワードは挙動が異なり、よく理解して使い分けなければならない。
最後に補足するが、refキーワードとoutキーワードを積極的に使うべきかというと、必ずしもそうではない。例えば、座標計算などを行うメソッドを作成していると、2つの値を返すメソッドが作りたくなる場合もあるだろう。しかし、座標値ならSystem.Drawing.Pointという構造体があり、これを戻り値にすれば、結果的に2つの値を1つの戻り値で返すことができる。このような相互に関連性が深い値は、クラスや構造体などにまとめて、戻り値で戻すことができるので、refキーワードやoutキーワードの出番はそれほど多くないかもしれない。逆にいえば、意味のあるデータの集まりをクラスや構造体などにまとめて扱うことは、ソースを分かりやすくするうえでも効果があるので、refキーワードやoutキーワードを使う前に、クラスや構造体を作ることで回避できないか検討してみる価値があるだろうということである。

『新プログラミング環境 C#がわかる+使える』
本記事は、(株)技術評論社が発行する書籍『新プログラミング環境 C#がわかる+使える』から許可を得て一部分を転載したものです。
【本連載と書籍の関係について 】
この書籍は、本フォーラムで連載した「C#入門」を大幅に加筆修正し、発行されたものです。連載時はベータ版のVS.NETをベースとしていましたが、書籍ではVS.NET製品版を使ってプログラムの検証などが実施されています。技術評論社、および著者である川俣晶氏のご好意により、書籍の内容を本フォーラムの連載記事として掲載させていただけることになりました。
→技術評論社の解説ページ
ご注文はこちらから
更新履歴
【2003/02/14】本ページのリストList 6-1内の60行目およびFig.6-1で、testObject1、testObject2となるべき個所が、testInt1、testInt2となっておりました。お詫びして訂正させていただきます。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。