HTTP語でWebブラウザとしゃべってみよう:TCP/IPアレルギー撲滅ドリル(2)
素朴な疑問
- あなたにとってのHTTPとは
- HTTPなしに暮らせないって本当ですか?
- Webのベースになったアイデアがあるそうですが
- Webの画面を見てみると、画像もたくさんあって、複雑な処理をしてるように見えますが
- URLってどうやって書くのが正しいんですか?
- HTTPの世界に潜入してみよう
- サーバとはどんなメッセージをやりとりするんですか?
- 前回の内容と違いますよ! どっちが正しいんですか? はっきりしてください
- GETメッセージをもう少し詳しく説明してください
- Webサーバが送ってきた結果はどうやって見ればいいんですか?
- 画像の取り出しを指定したら、どんな結果が返ってくるのですか?想像がつきません
- GET以外にはどんなものがありますか?
- Webブラウザになった気分でHTTPをしゃべってみよう
- HTTPをしゃべれったって、私は日本語しかしゃべれません!
- HTMLファイルをGETする実例を見せてください
- 画像ファイルをGETするとどうなるんですか?
- HTTPの機能ってこれだけじゃないですよね?
あなたにとっての「HTTP」とは
HTTPなしに暮らせないって本当ですか?
暮らせないなんて思っている人は、あまりいないはずですが、実際にHTTPがなくなると困ってしまう方はたくさんいらっしゃることでしょう。
えっ、HTTPってナンだですって? ああ、説明が後れました。HTTPとは、「Webブラウザ」が「Webサーバ」と情報をやりとりするときに使うプロトコルのこと。平たくいえば、「ホームページへのアクセスに使うプロトコル」です。
これがなくなるということは、イコール、この世のすべてのホームページにアクセスができなくなるってことになります。毎朝読んでいる某新聞社サイトにも、ネタの応酬でストレス解消してる某巨大掲示板サイトにも、そしてもちろん@ITにも、……ほら、こう考えると、困っちゃうでしょ?
Webのベースになったアイデアがあるそうですが
普段、わたしたちはWebブラウザを使って、いろんなサイトを利用しています。リンクをたどっていって、自分が読みたい情報にたどり着き、時にはどこにいるかすら分からなくなったりもします。
このように、実際にはいろんなところに散らばっている情報を、リンクという考え方で結び付けて、まるで全体が1つであるかのように見える情報を、「ハイパーテキスト」といいます。なお、ハイパーテキストというのは1つの考え方で、実際には、より具体的な書き方が取り決められています。これが皆さんもご存じのHTMLです。
このHTMLファイルを保存し、利用者の求めに応じて送り出してくれるのがWebサーバであり、またそれを受け取って、画面上にきれいに表示するのがWebブラウザです。そしてこの2つがHTMLをやりとりするときに使うプロトコルがHTTPという関係になります(図1)。
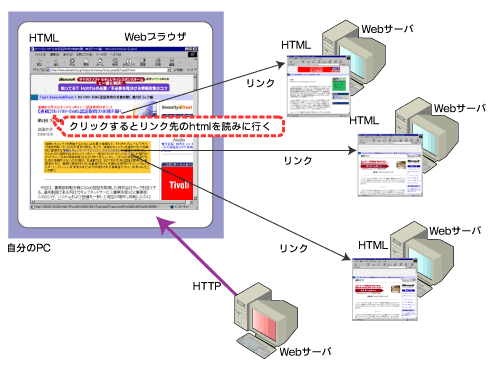 図1 WebサーバからHTTPでHTMLファイルを読み出し、Webブラウザに表示する
図1 WebサーバからHTTPでHTMLファイルを読み出し、Webブラウザに表示するどこにあっても、どんな種類の情報でも、必要なときにだれでも直接手に入れられる、これはWebの最も基本的で重要な概念です。
Webの画面を見てみると、画像もたくさんあって、複雑な処理をしてるように見えますが
複雑なデザインのホームページを見ると、どんなに複雑怪奇なことをやっているのかと想像してしまいますが、実際のところ、WebサーバとWebブラウザの間のやりとりはとても単純なものになっています。
基本になる考え方は「その情報の在りかを指定すると、その情報1つが取り出せる」というものです。もし1つの画面にたくさんの画像があるんだったら、この動作を何回も繰り返して、必要な数だけ、このやりとりを繰り返すだけです。こうやって取り出したものを、Webブラウザが画面へきれいに配置して、その結果をわたしたち利用者が見ていることになります(図2)。
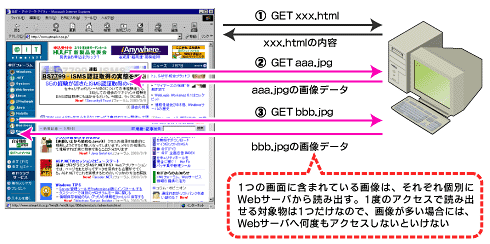 図2 画面を読み込んだ後、画面上の画像を1つ1つ読み込む
図2 画面を読み込んだ後、画面上の画像を1つ1つ読み込むこのとき大切なのは、情報の在りかをどうやってWebサーバに知らせるかです。そのために使われるのがURLという書き方です。よくホームページにアクセスするための「住所」としてURLを使いますが、もともとの意味は、ホームページの入り口に当たるHTMLファイルの在りかを表します。
URLで取り出せるのはHTMLファイルだけではありません。画面上に表示する画像や、流れる音楽にも、それぞれURLがあり、それを指定すればHTMLファイルと同じように取り出すことができます。つまり、HTMLファイルであっても、画像であっても、音楽であっても、どれも同じ手順で取り出すことができるわけです。そのおかげでHTTPはとてもシンプルなプロトコルになっています。
普通に考えれば、シンプルなことはイイことですよね? WebブラウザやWebサーバのプログラムはシンプルになるし、特別な条件の場合にだけ成り立つような例外も発生しにくい。Webがここまで使われるようになった理由の1つは、このシンプルさにあるようです。
URLってどうやって書くのが正しいんですか?
URLについては、すでにおなじみだと思います。例えば@ITのURLであれば、“http://www.atmarkit.co.jp/”ですね。これをもう少し一般的な書き方で表すと、こうなります。
http://Webサーバ名:ポート番号/パス/
“http://”は読み出すのに使うプロトコルがHTTPだということを表しています。でも、ここで頭を悩ませる必要はありませんよ。\1,000と書かれた値札を見て、\=円、円の機能は? と考える人などいませんから、それと同様にWebにアクセスするときに使うURLの呪文だと考えて構いません。また、多くのWebブラウザでは、この部分を省略したら“http://”を自動的に付け加えてくれます。
Webサーバ名はWebサーバの名前、ポート番号はWebサーバが利用しているポート番号(「telnetでWebサーバに接続してみよう」参照)です。通常、HTTPのポート番号は80番になりますが、何かの理由でそれを変えていた場合には、ここに実際のポート番号を書き込みます。パスはそのサーバ内でのファイルの配置を表した情報です。
インターネットに関していえば、このURLを指定することで、地球上のインターネットサーバに格納されているHTMLファイル、画像、音楽などを、それぞれ個別に指し示すことができます。そのおかげで、先にも触れたとおり、種類を問わず、指定した情報を取り出すという、非常にシンプルな形でよいわけです。
HTTPの世界に潜入してみよう
サーバとはどんなメッセージをやりとりするんですか?
前回、少し書いたのですが、WebブラウザとWebサーバがやりとりするHTTPの指令は、基本的に、英数字で書かれたものになっています。そのため人間が見てもすぐ理解できるのが特徴です。
中でも最も重要なのは、そう「情報の取り出し」を指令するメッセージです。その理由は、ここまでの説明を読んだ方なら、ぴんときますよね。Webブラウザが、HTTPを使ってサーバにアクセスする大部分の動作が、「情報の取り出し」だからです。
では具体的にWebブラウザがWebサーバに、どんなメッセージを送るのか見てみましょう。例えば、http://www.atmarkit.co.jp/fnetwork/accesstest/at.htmlを読み出すのであれば、www.atmarkit.co.jpのポート80番に接続した後、
GET /fnetwork/accesstest/at.html HTTP/1.1 Host: www.atmarkit.co.jp (Host以外の付加情報) (改行)
というメッセージを送出します。このメッセージを受け取ったWebサーバは、読み出し結果を知らせる情報とともに、at.htmlの内容を返します。
HTTP/1.1 200 OK (各種の付加情報) (改行) (at.htmlの内容)
これが最も基本的なHTTPのメッセージのスタイルといっていいでしょう。
前回の内容と違いますよ! どっちが正しいんですか? はっきりしてください
おっしゃるとおりです。前回登場した例と今回の内容はちょっと違っています。でも、どちらかが完全な間違いというわけでもないんです。というのも、HTTPには発表された年代によって、いくつかの種類があるからなんです。
前回紹介した例は、一番原始的なタイプで、HTTP/0.9と呼ばれるルールに沿った書き方です。まあ古いものですから機能も少なく、その分、直感的に分かりやすい書き方になっています。前回は、HTTPの勉強が目的ではなかったので、直感的なHTTP/0.9で書いてみました。ちなみに、いまどきのWebブラウザは、こんな古いスタイルのメッセージは使いませんが、Webサーバの方は、こういった書き方にもちゃんと対応してくれるものが多いようです。
今回登場したメッセージの例は、いま、広く利用されているものの中では、一番新しいタイプで、HTTP/1.1と呼ばれるルールに沿った書き方です。機能が増えた分、Webサーバに与える指令も、Webサーバから返ってくる情報も、HTTP/0.9に比べると、ちょっと複雑になっています。でもせっかくですからここでは最新のものを取り上げて学習することにしましょう。
GETメッセージをもう少し詳しく説明してください
GETメッセージは、“GET”という文字に続いて、読み出そうとするファイルのパス、さらに『"HTTP/1.1"』という文字を続けたものになっています。日本語でいえば、「接続したサーバの中の、指定したパスにあるファイルを“GET”してください。このコマンドはHTTP/1.1に沿った書き方をしています」とでもいったところでしょう。
GET指令と(改行)との間には、付加情報を指定します。これは、WebブラウザからWebサーバにメインの指令のほかにもいろんな種類の情報を送って、さらに複雑な動作をさせようというアイデアから生まれたものです。この情報は、GETメッセージの後に、
情報の種別名: 情報の内容
のような形で書きます。
付加情報の中は1つだけ必ず指定しないといけないものがあります。接続先のWebサーバ名を書くHost情報です。なぜHost情報を書かなければいけないのか、その説明は少々複雑になるので詳しくは省略しますが、簡単にいえば「読み出しを代行する特殊なサーバに接続して、そのサーバに『www.atmarkit.co.jpを読んできて』と指令する」ケースがあるからです。こんなときには、その特殊なサーバが通信の接続先になり、GETメッセージの中に「Host: www.atmarkit.co.jp」と指定してあげます。すると、その特殊なサーバがHost情報を読み出して、そこに指定されている「www.atmarkit.co.jp」に接続、結果をWebブラウザに返してくれる、というワケです。
このほかの付加情報としては、「Webブラウザの種類」を示すものがあります。利用者が使っているWebブラウザの種類が分かれば、WindowsやMacといった機種ごと、Webブラウザの種類ごとなど、よりきめ細かく対応することだってできます。
表1は使われる付加情報をピックアップしたものです。HTTP/1.1の中では、これ以外にも多くの付加情報が決められています。また、この付加情報はその働きによって何種類かに分類されているのですが、ここではこれ以上詳しくは触れないことにしましょう。
| 区分 | フィールド名 | 意味 |
|---|---|---|
| Webブラウザの基本情報 | Authorization | 認証のためのユーザー名とパスワード |
| Host | 接続先のWebサーバ名 | |
| Referer | 直前に見ていたページ | |
| User-Agent | Webブラウザの種類 | |
| 取り出し要求に関する情報 | Data | 日付情報 |
| Connection | 接続状態の管理 | |
| やりとりする内容に関する情報 | Content-Type | やりとりする情報の種類 |
| Content-Length | やりとりする情報のサイズ | |
| Last-Modified | 最終更新日 | |
| 表1 分かりやすい付加情報をピックアップ | ||
Webサーバが送ってきた結果はどうやって見ればいいんですか?
何といっても一番大切なのは1行目です。最初の“HTTP/1.1”は、Webサーバが「自分はHTTP/1.1のつもりで処理したぜ」と表明しているものです。GETメッセージに“HTTP/1.1”と書いたのなら、この部分も“HTTP/1.1”になるのが普通です。
その後に続いている“200”と“OK”が、処理の結果を表すもので、“200”は「うまくいった」ことを表す数字、また“OK”はそれを文字で表したものです。
この結果を表す数字は、100番台、200番台、300番台、400番台、500番台と、それぞれグループに分かれています。例えば、分かりやすいところでは、200番台は「うまくいった系」メッセージ、400番台は「うまく読めない系」メッセージ、500番台は「サーバ内部のエラー系」メッセージ、といった具合です。よく見かけるメッセージを表2にリストアップしてみました。
| 意味 | ステータスコード | 結果フレーズ |
|---|---|---|
| 正常 | 200 | OK |
| リクエストがおかしい | 400 | Bad Request |
| ログインに失敗した | 401 | Unauthorized |
| 読み出す権利がない | 403 | Forbidden |
| 見つからない | 404 | Not Found |
| サーバ内部にエラー発生 | 500 | Internal Server Error |
| 表2 分かりやすいステータスコードをピックアップ | ||
これらのメッセージは、Webブラウザでは、例えば次のように表示されます(画面1)。
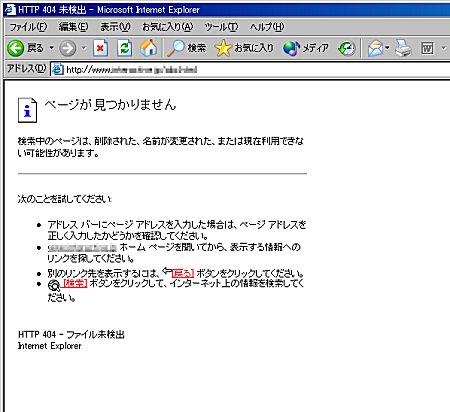 画面1 読み出そうとする対象が見つからない場合。左下にステータスコード404を表示している
画面1 読み出そうとする対象が見つからない場合。左下にステータスコード404を表示しているこの後に続いている「各種の付加情報」の部分には、「サーバのバージョン」とか「日付」などの、サーバ自身や今回の情報取り出しに関する情報が書き込まれています。その中でも特に注目に値するのは、結果として送り返したものが、HTMLなのか、画像なのか、音楽なのか、その種類を表す情報です。
例えば結果としてHTMLファイルを送り返したのであれば、この部分に
Content-type: text/html
と書いた情報が含まれます。また画像ファイル(gif形式)であれば、
Content-Type: image/gif
となるはずです。取り出した情報の種類とxxx/yyyの部分の書き方の対応は、世界的に決められているもので、Webサーバが返す結果情報の種類も、それに従っています。表3にはよく使われそうなものをピックアップしてみました。
| タイプ(xxxの部分) | サブタイプ(yyyの部分) | ファイルの種類 |
|---|---|---|
| text | html | html |
| text | plain | テキスト |
| image | gif | 画像(gif) |
| image | jpeg | 画像(jpg) |
| audio | midi | オーディオ(midi) |
| audio | x-wav | オーディオ(wav) |
| 表3 分かりやすいMIMEタイプをピックアップ | ||
画像の取り出しを指定したら、どんな結果が返ってくるのですか? 想像がつきません
もしHTMLファイルの取り出しを指定したのなら、結果はHTMLファイルの内容が文字で送られてくるはずです。じゃあ、画像を指定したときには、結果に何が送り返されてくるのでしょうか? その答えはやっぱり「画像ファイルの内容そのもの」です。HTMLの取り出しがHTMLファイルの内容をそのまま送り返したように、大部分のWebサーバは、画像ファイルの内容をそのまま送り返します。
それがどんなものかは、画像ファイルをメモ帳で開いたことがある人なら想像がつきますよね? そう、人間には読めない、ぐちゃぐちゃな内容です。それをそのまま特別な変換をせずに送り返します。
余談ですが、メールに画像ファイルを添付したときには、画像ファイルの内容を文字で表現する特別な形式に変換してから、メールと一緒に送信します。HTTPでは、画像は画像のまま送ってしまうので、変換に手間もかかりませんし、処理もシンプルなもので済みます。「シンプル」、やっぱりこれがHTTPのキーワードといえそうです。
GET以外にはどんなものがありますか?
HTTPではGETがとっても大きな役割をしているので、まずはGETから取り上げましたが、このほかにもいくつかの指令(正確にはメソッドといいます)があります。
例えば、デジカメ写真を登録して整理できる電子アルバムのようなサイトなら、自分のPCに入っている写真ファイルを、Webサーバにアップロードすることになります。こんなときには、当たり前ですがGET指令は使えません。その代わりに使うのがPOST指令です。POST指令を使うときには、(改行)の後に、アップロードするファイルの内容が続きます。このPOSTを含め、HTTP/1.1で利用できるものを、表4に示しておきます。
| メソッド | 機能 |
|---|---|
| HEAD | 情報本体ではなく概要を取り出す |
| GET | 情報をWebサーバから取り出す |
| POST | 情報をWebサーバに送り込む |
| PUT | Webサーバ上の情報を書き換える |
| DELETE | Webサーバ上の情報を削除する |
| TRACE | 動作を確認するための情報を得る |
| OPTIONS | 使用できるメソッドの一覧を得る |
| CONNECT | プロキシと呼ばれる特殊なサーバへの指示 |
| 表4 HTTP/1.1のメソッド | |
Webブラウザになった気分でHTTPをしゃべってみよう
HTTPをしゃべれったって、私は日本語しかしゃべれません!
私も日本語しかしゃべれませんのでご心配なく。これは、いわゆる業界用語の一種なんだと思いますが、例えば「HTTP/1.1に対応したWebブラウザ」のことを、「HTTP/1.1をしゃべるWebブラウザ」などと言い表すことがよくあります。これに倣って、ここの「HTTPをしゃべってみよう」は「HTTPのルールに沿ってWebサーバとやりとりしてみよう」くらいの意味で理解してください。
HTMLファイルをGETする実例を見せてください
ではまずWebサーバからHTMLファイルを取り出してみます。試す内容は前回と同じですので、面白くないといえば面白くないのですが、HTTP/1.1ならではの細かい情報がくっついてきますので、そこに注目してください。
前回と同様にtelnetを起動したら、www.atmarkit.co.jpに接続します。開いたウィンドウに次のとおりGETメッセージ入力します。前回に比べるとちょっと長いので、この記事をカット&ペーストして、ちょっと形を整えて使うことをオススメします。
GET /fnetwork/accesstest/at.html HTTP/1.1 Host: www.atmarkit.co.jp
Hostから始まる行の行末まで入力したら(またはペーストしたら)、そこで1度改行キーを押し、さらにもう1度改行キーを押します。HTTP/1.1に対応したWebサーバは、改行だけの行がきて初めて、それまで入力した複数行のメッセージの処理を始めるようにできているんですね。
結果は画面2のようになりました。「HTTP/1.1 200 OK」から下の部分がWebサーバから戻ってきた結果です。そこから下、改行だけの行があるところまで、この間の全部が「各種の付加情報」と説明したものに当たります。日付(Date)、サーバのバージョン(Server)、クッキー情報(Set-Cookie)、結果の種類(Content-Type)などは、比較的分かりやすい付加情報だと思います。
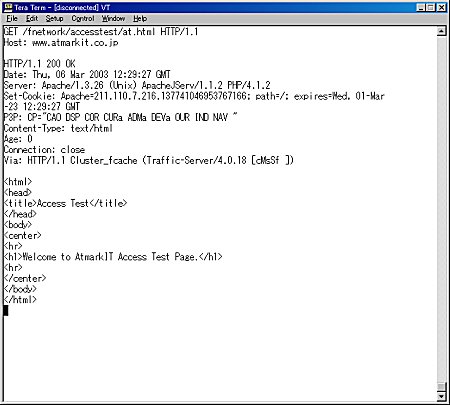 画面2 HTMLを取り出すときのメッセージと結果
画面2 HTMLを取り出すときのメッセージと結果この付加情報の後には、at.htmlの内容がそのまま現れています。Webブラウザは、付加情報の内容を使って、クッキーなどいろんな機能のコントロールをしつつ、また得られたHTMLファイルの表示を行うわけです。なお、at.htmlをWebブラウザでアクセスすると、画面3のようになります。
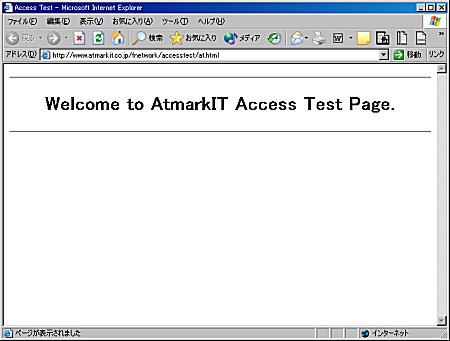 画面3 同じHTMLにWebブラウザでアクセス
画面3 同じHTMLにWebブラウザでアクセス画像ファイルをGETするとどうなるんですか?
続いて画像ファイルをGETしてみます。接続手順はHTMLファイルと同じ、GETメッセージは次のように書きます。
GET /top/mainlogo.gif HTTP/1.1 Host: www.atmarkit.co.jp
結果は画面4のようになりました。
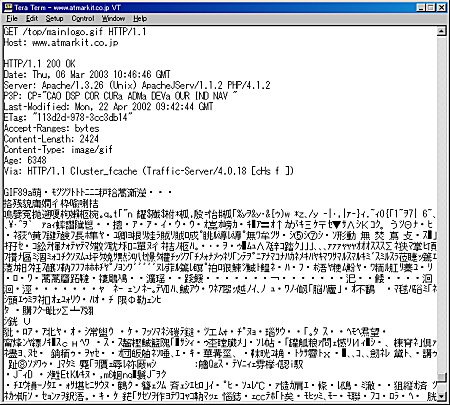 画面4 画像を取り出すときのメッセージと結果
画面4 画像を取り出すときのメッセージと結果付加情報のContent-Lengthは画像ファイルのサイズを表すものです。情報の種類を表すContent-Typeはimage/gifになりました。画像ファイルの内容は、ご覧のとおりぐちゃぐちゃです。これはGIFファイルの中身で、人間が見るようにはできていないので仕方ありません。唯一、GIFファイルであることを表す文字“GIF89a”が先頭に見えるくらいです。でも、この情報をファイルに保存してあげれば、ちゃんと普通に表示できる画像ファイルになります。
HTTPの機能ってこれだけじゃないですよね?
今回は、HTTPが持っている機能の中でも、最も使われる機会の多いGETメッセージを中心にして、HTTPの基本的な働きを見てきました。今回取り上げた範囲では、HTTPはそんなに難しいものではなかったと思います。
HTTPの主な技術のうち、今回触れなかったけれど重要なものとしては、「キャッシュ」「認証」「持続的接続」といったものがあります。これらはもう少し踏み込んで理解をしないといけないのでちょっと難しい話になりますが、ぜひHTTP理解の第2ステップとして勉強してみてください。カンタンそうでなかなか難しい、HTTPの奥深い世界を垣間見られるはずですヨ。
連載第3回「SMTPでメール送信の舞台裏をあやつる」ではHTTPと並んで多用されるメール関連のプロトコルSMTPについて説明します。telnetを使った手動接続によりメールを送信し、また受信してみましょう。
参考文献:
連載:インターネット・プロトコル詳説(1) HTTP(Hyper Text Transfer Protocol)〜前編
連載:インターネット・プロトコル詳説(2) HTTP(Hyper Text Transfer Protocol)〜後編
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。