JFSのファイル管理とジャーナリングの実装:Linuxファイルシステム技術解説(6)(2/3 ページ)
JFSのジャーナリングと障害回復
JFSのジャーナリングは、ext3およびReiserFSと同様にメタ・データを保存する。
JFSのジャーナリング処理
JFSを通したディスク操作は、「ファイル生成」「リンク」「ディレクトリ作成」「データ削除」など、複数のトランザクションに分割して処理される。これらの操作は、ディスクとログの同期も含めてジャーナルログに記録される。
ジャーナルログはまずメモリに記録され、JFSのフラッシュデーモンによってディスクへ書き込まれる。JFSのディスク復旧は、ジャーナルログを読み込んでディスク操作を再生(redo)することで行われる(redo操作はjfs.fsckコマンドに含まれている)。redoは、実際に行われた操作を時系列に沿って再実行する。ジャーナルログには、実際に行われたディスクとジャーナルログの同期情報も記録されるため、障害復旧時は同期後のログデータのみを再生することで無駄な処理が発生しないようになっている。
ジャーナルログはファイルシステムの作成時(mkfs.jfs)に、一緒に作成される。デフォルトでは、ファイルシステムの総和の0.4%、最大サイズは32Mbytesとなっている。
ジャーナルログを基にした復旧作業
障害が発生すると、JFSはジャーナルログを参照しながら最終コミット以降の復旧を試みる。具体的には、以下の順番で処理が行われる。
- スーパーブロックチェック
ジャーナルログを開いて最初にスーパーブロックを読み込み、バージョン情報や状態フィールド、マジックナンバーなどのチェックを行う。このとき、状態(state)が「LOGREDONE」(すでにジャーナルログの再生が終了している)になっている場合は、単にスーパーブロックの更新を行って終了する。それ以外の場合は以下の作業を続行する。 - ジャーナルログレコードの再生開始ポイントの検出
ジャーナルログの最後尾を探し出し、トランザクションの処理内容を調査する。
ディスクと同期を行う同期点(sync point)は、ジャーナルログレコードに「SYNCPT」と記録される。ジャーナルログにSYNCPTが記録されていれば、その時点でディスクと同期したことが分かる。
ジャーナリングシステムの障害回復という観点からいえば、このSYNCPTより前の情報はディスクとログの同期が保証されるため、復旧操作は必要ない。実際に復旧が必要なのは、まだディスクと同期が行われていないSYNCPT以降の操作である。故に、JFSはこのSYNCPT以降のトランザクションの操作を調査するために、ジャーナルログレコードの処理手順を再生(replay)する。 - ジャーナルログレコードの再生
ジャーナルログレコードの再生開始ポイントを検出したら、時系列に沿って処理を再生する。 - トランザクションのチェック
ジャーナルログを再生した後、各トランザクション処理が時系列的に矛盾のないことをチェックし、バッファをディスクにフラッシュする。 - 終了処理
iノードの割り当てマップおよびスーパーブロックを更新する。
jfs_dumpによるジャーナルログの参照
JFSが行うジャーナリングのロギングは、jfs_logdumpコマンドで取得したジャーナルログのダンプメッセージで確認できる。
以下の例は、/dev/hda3をJFSのパーティションとしたときのジャーナルログの処理内容を示している。
# jfs_logdump /dev/hda3 |
jfs_logdumpによって生成されたjfslog.dmpは、以下のようになる。
JOURNAL SUPERBLOCK: |
ジャーナルログには、
- LOG_COMMIT
- LOG_MOUNT
- LOG_SYNCPT
- LOG_REDOPAGE
- LOG_NOREDOPAGE
- LOG_NREDOINOEXT
- LOG_UPDATEMP
という7種類の情報が記録される。特に、LOG_REDOPAGEレコードにはiノードの確保/解放など、iノードマップを更新するためのメタ・データ情報が含まれている。ジャーナルログの中で、ディスク操作を再生するための最も重要な部分といえる。
また、上記のジャーナルログでも確認できるように、LOG_COMMITとLOG_REDOPAGEは対になっている。さらに、「logtid」(赤字部分)は、1組ごとに等しいIDが割り振られていることが分かる。つまり、LOG_COMMITとLOG_REDOPAGEが1つのアトミックトランザクションとして処理されているということである。
LOG_SYNCPT(同期地点)を以下に赤字で示す。このLOG_SYNCPTは、トランザクションID(logtid = d 4603)が等しい2つの操作LOG_COMMITとLOG_REDOPAGEの間で実行されている。つまり、アトミックトランザクションの間に同期が行われている。
logrec d 2550 Logaddr= x 1b9c9a8 Nextaddr= x 1b9c984 Backchain |
LOG_SYNCPT以前のデータの整合性は保証されるため、ジャーナリング処理では「logrec d 2552」のLOG_REDOPAGEは再生せず、LOG_COMMIT以降を再生する。ここまでの様子を図5に示す。
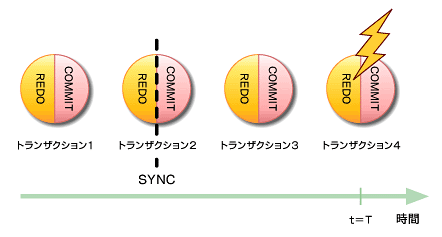 図5 トランザクションと障害発生
図5 トランザクションと障害発生時系列にコミットが行われ、それがジャーナルログに記録されているシステムにおいて、時刻Tに何らかの障害が発生した場合を考えてみよう。JFSは、記録していたジャーナルログを再生する。再生の手順としては、ジャーナルログを読み込んで、最後にSYNCPTした時点までさかのぼる。
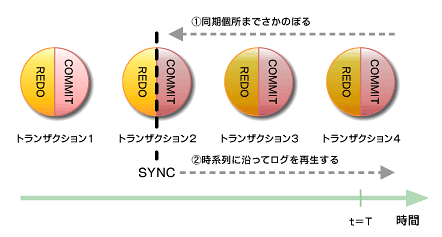 図6 ログの再生
図6 ログの再生図6は、トランザクション2の途中でSYNCPTが取られているケースである。トランザクション1は、ログに記録したトランザクション操作とディスクに記録されている操作が同期しているため、データの整合性が保証される。しかし、トランザクション2はSYNCPTが完了していないため、操作およびデータの整合性が保証されない。トランザクション2以降も同様である。この場合、JFSはコミットされたトランザクションを再生(redo)あるいはコミットされていないトランザクションをロールバック(undo)するなどして、メタ・データの復旧を試みる。
これらの操作はfsck_jfsに実装されており、起動時なども同様の手順でジャーナリング処理が行われる。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。