パフォーマンスを意識した設計/実装テクニック:JavaのDBアクセスを極める(6)(2/3 ページ)
ディスクI/Oの削減
ディスクI/Oの回数を減らす工夫として「キャッシング」という方法があります。これは一度データベースにアクセスしたデータをメモリ上に保存しておき、再度同じデータへの問い合わせがあった際には、データベースへのアクセスは行わずにメモリ上のキャッシュからデータを取得する方法です。
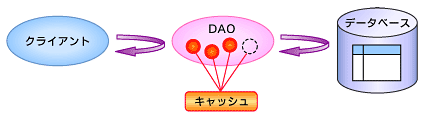 図3 データ・キャッシュの仕組み
図3 データ・キャッシュの仕組みキャッシュはクライアントからDAO(Data Access Object)へのアクセスの際に、一度問い合わされた内容についてはデータベース・アクセスを行わずに、DAO内に保持されているキャッシュから対応するデータを返します。頻繁にアクセスされるマスターデータなどに使用すれば、パフォーマンスの向上に非常に大きな効果を発揮します。
商品コードをキーにして商品マスターテーブルより商品の情報を取得するという処理を例に取って見てみましょう。ここでは第5回「デザインパターンを利用したDBアクセスの実装」で紹介したDAOクラスを拡張して、キャッシュの機能を実装してみることにします。具体的なクラス構成は以下のようになります。
- DAOBase:DAOの基本的なメソッドを定義した抽象クラス
- ItemDAOBase:商品テーブルへのアクセスを実装したクラス
- ItemDAO:呼び出し元クラスから商品テーブルへのアクセスを提供するクラス
- Item:商品クラス
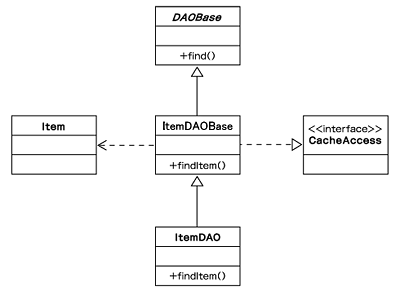 図4 商品を取得するDAOのクラス図
図4 商品を取得するDAOのクラス図データをキャッシュする機能は、図4のようにItemDAOクラスではなくItemDAOBaseに組み込んでいます。これはクライアントの商品クラスの要求があった場合に、データベース・アクセスを行った結果のデータであるのか、キャッシュより取得されたデータであるのかを意識させずに、同じ振る舞いをさせるためです。
public interface CacheAccess
{
/** 商品コードを検索キーとして商品インスタンスを取得する
* @param 商品を取得するための商品コード
* @return 商品クラスのインスタンス
**/
Item findItem (String itemCode);
}
public class ItemDAOBase
extends DAOBase implements CacheAccess {
public Hashtable cache; // key:商品コード
// value:商品インスタンス
public Item findItem(String itemCode)
{
Item item = (Item)cache.get(itemCode);
if(item == null)
{
item = (Item)this.find(itemCode);
if ( item != null )
cache.put(itemCode, item);
}
return item;
}
public Object find(String itemCode)
{
Item item = null;
//
// 商品クラス取得のデータベース・アクセス処理(省略)
//
return item;
}
}
public class Item
{
// 商品クラスのメンバ(省略)
}
(2005年7月21日にコードの一部を修正しました)
ItemDAOBaseクラスのfindItemメソッドに注目してください。まずキャッシュの中に問い合わせに該当するデータが存在するかを調べます。存在しない場合には、データベース・アクセスによりデータを取得し呼び出し元に渡します。この際に取得したデータはキャッシュに格納しますので、2度目以降の同じ商品コードでの問い合わせに対しては、データベース・アクセスを行わずキャッシュよりデータを取得できるようになります。
データベース・サーバとの通信の効率化
データベースの更新処理において、更新のコマンドを1件ずつ送信するよりも、複数の更新のコマンドをまとめて一度に送信することができれば、データベース・サーバとの通信量の削減となるため、大きなパフォーマンスの向上を期待できます。
例えば、複数の発注情報を同時にテーブルに挿入する例を考えてみます。ここでもDAOクラスを実装してみることにします。具体的なクラス構成は以下のようになります。
- OrderFacade:DAOクラスを制御するクラス
- OrderDAO:発注テーブルにアクセスするメソッドを実装したクラス
- OrderIterator:複数の発注クラスを格納するイテレータ
- Order:発注クラス
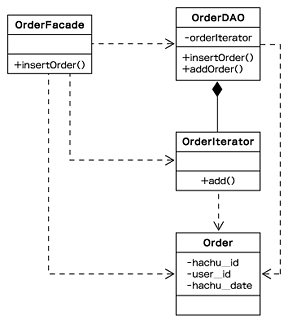 図5 発注データをテーブルに挿入するDAOのクラス図
図5 発注データをテーブルに挿入するDAOのクラス図
import java.util.*;
import java.sql.*;
public class OrderDAO {
private ArrayList alist = new ArrayList();
private ListIterator orderIterator = alist.listIterator();
private Connection conn;
public OrderDAO(Connection pCon) {
conn = pCon;
}
public int[] insertOrder()
{
int[] insertCounts = null;
try{
// 自動コミットをFALSEにしておく
conn.setAutoCommit(false);
// PareparedStatementの作成
PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO ORDER_TBL (HACHU_ID,USER_ID,HACHU_DATE) VALUES(?, ?, ?)");
orderIterator = alist.listIterator(0);
while (orderIterator.hasNext())
{
Order order = (Order) orderIterator.next();
pstmt.setInt(1, order.hachu_id); // 1つめのパラメータ
pstmt.setString(2, order.user_id); // 2つめのパラメータ
pstmt.setDate(3, order.hachu_date); // 3つめのパラメータ
pstmt.addBatch(); // バッチ処理に追加
}
insertCounts = pstmt.executeBatch();
}
catch(SQLException se)
{
System.err.println(“SQL Failed”);
se.printStackTrace();
}
catch(Exception ex)
{
ex.printStackTrace();
}
return insertCounts;
}
public void addOrder(Order order)
{ // 挿入する発注データをIteratorに追加
this.orderIterator.add(order);
}
}
(2005年7月21日にコードの一部を修正しました)
リスト2のinsertOrderメソッドは、複数の挿入対象の発注データをまとめて一度に実行しています。この処理によりデータベース・サーバへの通信の回数とSQL構文解析の時間を節約することができます。
ここでは1件以上のすべてのテーブル挿入処理を同じメソッドで実装するために、OrderIteratorというクラスを使用しています。これによりOrderFacadeから挿入用のメソッドを呼び出す際に、1件のみの挿入なのか複数件の挿入なのかを意識せずに挿入操作をすることが可能になっています。さらにPrepareStatementを使用することにより、SQL文は実行前にコンパイルされキャッシュされるので、パラメータのみが異なるSQL文について実行時のパフォーマンスを大きく向上できます。
データベース・サーバとの通信回数を減らす方法で、ストアド・プロシージャを使用するという方法もあります。ただし、この方法はビジネス・ロジックをストアド・プロシージャに持ち込む恐れもあり、またデータベースのテーブル構造などを意識してビジネス・ロジックを実装する必要があるため、メンテナンスが煩雑になる傾向にあります。(次ページへ続く)
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。