第6回 Exchange Server 2003データベースの仕組み:基礎から学ぶExchange Server 2003運用管理(2/3 ページ)
Exchange Serverでは、一般的なデータベース・サーバと同様、トランザクション・ログ・ファイル(OracleではREDOログ・ファイルと呼ばれる)を使用する。トランザクション(transaction)は、直訳すると「処理」であり、データベースの世界では、データベースに対する「更新」が含まれる処理を指す。Exchange Serverでは、「メールの新規作成・送信」や「メールの移動(削除済みアイテムへの移動やフォルダ間の移動など)」「メールの削除」「パブリック・フォルダへのアイテムの投稿」など、データベース(ストア)である.edbファイルと.stmファイルへの書き込みや変更が発生する処理をトランザクションという。
トランザクション・ログ・ファイルは、これらのトランザクションを記録するためのファイルである。ログ(log)は「記録する」という意味で、このファイルの目的は次の2つである。
- 不意な電源断やソフトウェア障害時のデータ回復
- データベース・ファイル(.edbまたは.stm)破損時のデータ回復
どちらも障害が発生したときのデータ回復を目的としていて、障害が発生する直前の状態までデータ回復できるのがポイントである。これは、一般的なデータベース・サーバであれば、備えている機能である(ちなみにMicrosoft Accessにはこの機能がないため、通常はデータベース・サーバには分類しない)。以降では、データ回復の具体的な動作について、トランザクション・ログ・ファイルの使われ方を説明しながら詳しく見ていく。
■トランザクション・ログ・ファイルの使われ方
まずは、メールを新規作成したときの動作を例にトランザクション・ログ・ファイルの使われ方を説明する。
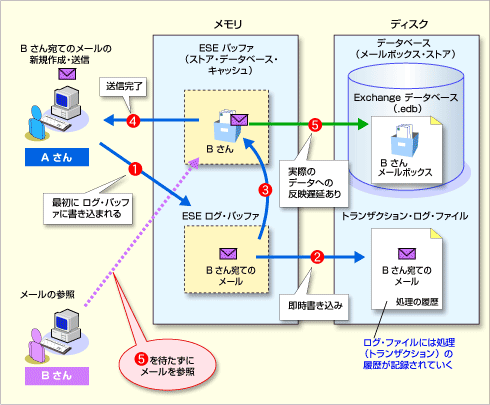 メールを新規作成するときの内部動作
メールを新規作成するときの内部動作この図は、AさんがBさんあてのメールを新規作成し、メールを送信したときの内部動作である。
(1)まず、変更(AさんがBさんあてにメールを送信したという情報)が「ESEログ・バッファ」に書き込まれる。ESEログ・バッファはトランザクション・ログ・ファイルへ変更を書き込むためのメモリ上の領域である。
(2)トランザクション・ログ・ファイルに変更が書き込まれる。このファイルは、時系列で順々(シーケンシャル)に書き込まれ、トランザクション(処理)の履歴が記録されていく。
(3)ESEバッファ上のBさんのメール・ボックスにメールが受信される。
(4)送信が完了したことがAさんに伝わる。このタイミングで、Aさんはほかのメールを作成したり、Bさんは受信したメールを確認したりできるようになる。
(5)チェックポイントというプロセスが発生したときに、ESEバッファ内の更新結果(Bさんのメール・ボックスに受信されたメール)がデータベース・ファイル(.edb)に書き込まれ、更新結果が実際のデータに反映される。
図の中でポイントとなるのは、(2)と(5)である。トランザクション・ログへの更新履歴の書き込みは即時に行われるのに対して、実際のデータベース(.edb)への反映には遅延が発生している。しかし、これは意図的なものであり、Exchange Serverは実際のデータベースへの書き込みを遅らせ、チェックポイントというタイミングでまとめて書き込みを行うことで、ディスク・アクセスを減らし、パフォーマンスの向上を図っているのだ。
【TIPS】ESEログ・バッファのサイズを調整する
以前のExchange Serverは、デフォルトのESEログ・バッファのサイズが小さく調整が必要だった。従って、以前のバージョンからExchange Server 2003へアップグレードを行っている場合は、ESEログ・バッファのサイズに注意してほしい。ESEログ・バッファのサイズは、ADSI Editツールで[ストレージ・グループ]のプロパティを開いて、msExchESEParamLogBuffersの値を変更することで調整可能だが、詳しくはマイクロソフトサポート技術情報の「非常に低く設定されたESEログ バッファは、Information Storeサービスが原因で応答を停止する」を参照してほしい。また、ESEログ・バッファを増やす場合は、その後のメモリ使用量にも注意し、ページングの発生頻度を調べることも忘れないでほしい。
■チェックポイントのタイミング
チェックポイントが発生するタイミングは、デフォルトでは次のとおりである。
- 未反映のデータが20Mbytes分あるとき(後述するプレビアス・ログ・ファイルが3つ溜まったとき)
このタイミングは、ADSI Editツールで[ストレージ・グループ]のプロパティを開いて、msExchESEParamCheckpointDepthMaxの値を変更することで調整可能である。ただし、設定を変更する際は、パフォーマンスと障害時の復旧時間(ダウンタイム)のトレード・オフに注意してほしい。例えば、msExchESEParamCheckpointDepthMaxの値を大きくすると、ディスク・アクセスを減らすことができパフォーマンスを向上させることができるが、障害が発生したときの復旧時間は長くなってしまう。また、値を小さくすれば(最小値は5Mbytes)、ディスク・アクセスが頻繁に発生することになりパフォーマンスが低下するが、障害からの復旧時間は短くなる。復旧時間は、この後説明する「ロール・フォワード」の時間である。
■不意な電源断やソフトウェア障害時のデータ回復
前掲の図では、(4)の段階でメールの送信が完了しているが、実際のデータベースへ反映される(5)の前に障害が発生する可能性もある。デフォルトでは、20Mbytesごとにチェックポイントが発生するので、例えばメールのやりとりがほとんど発生しない環境では、(4)と(5)の間は、数分以上になることもある。この間に、停電などの障害が発生した場合を考えてみる。障害が発生すれば、当然メモリ(ESEバッファ)の情報は失われ、実際のデータベースへは未反映のままとなる。この場合、障害からの復旧後に、もしExchange Serverが何もしなかったとすると、AさんからBさんへメールが送信されたという情報がなくなってしまう。
そこでExchange Serverは、(5)の前に障害が発生した場合は、障害からの復旧後の起動時に次のように動作する。
「トランザクション・ログを読み込み、障害前に実行されていた処理(トランザクション)がないか探す。見つかった場合は、トランザクション・ログに記録された更新履歴を基に処理をやり直す」
このやり直し処理は「ロール・フォワード」と呼ばれる。このようにExchange Serverは、障害が発生してもトランザクション・ログを使って障害回復できるのである。ここでは停電を例に説明したが、次のような障害時も同じようにデータ回復が可能である。
- 電源コードが抜けるなどの不意の電源断
- Exchange Serverの異常終了
- OSの異常終了(ブルー・スクリーン)
- ディスクを除くハードウェア障害
これらは、いずれもOSとExchange Serverを再起動すれば、基本的には復旧可能な障害である。4つ目の「ディスクを除くハードウェア障害」は、障害のあったハードウェアを新しいものに交換しても、OSやExchange Serverが正常に動作するハードウェアのことを指している。例えば、メモリやCPUなどの故障であれば、新しいものと交換すれば、OSやExchange Serverは正常に動作する。正常に動作すれば、トランザクション・ログを使ったデータ回復が可能なのである。
■データベース・ファイル破損時の障害発生直前までの復旧
次にデータベース・ファイル(.edb、.stm)が破損した場合を考えてみる。次の図のような状況だったとする。
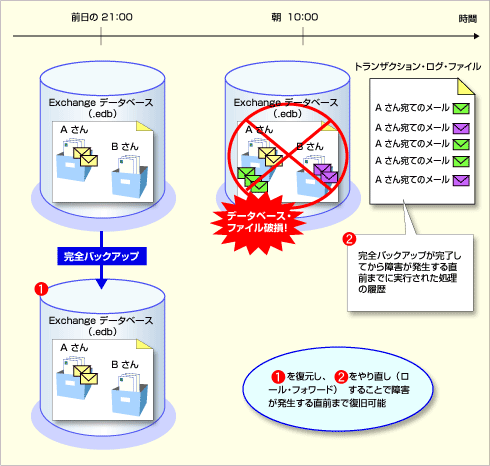 データベース・ファイル破損時の障害発生直前までの復旧
データベース・ファイル破損時の障害発生直前までの復旧この図では、前日の21:00にデータベース・ファイル(.edb)の完全バックアップを取り、翌日の朝10:00にディスク障害が発生してファイルが破損した状況を想定している。完全バックアップを復元すれば、バックアップを実行した時点まで復元できるが、トランザクション・ログには、完全バックアップが完了してから障害が発生する直前までの処理の履歴が格納されている。従って、これらの処理をやり直し(ロール・フォワード)すれば、障害が発生する直前までデータ回復できるのである。なお、詳しい復元手順については次回解説する。
このようにExchange Serverは、一般的なデータベース・サーバと同様、バックアップを実行した時点ではなく、障害が発生した直前まで復旧する機能を持つ。しかし、あくまでもデータベース・ファイル(.edbや.stm)の破損時に「トランザクション・ログ・ファイルが残っていれば」という条件が付くことに注意してほしい。もし、データベース・ファイルとトランザクション・ログ・ファイルを同じディスク上に保存したとすると、そのディスクが壊れたときに両方とも失われてしまうからである。
従って、トランザクション・ログ・ファイルは、データベース・ファイルとは異なるディスクへ配置するようにし、かつRAID 1やRAID 0+1でミラー化して、ディスク障害に備えておくとよい(コストはかかるがRAID 0+1はパフォーマンスにも優れているのでお勧めである)。また、トランザクション・ログ・ファイルへの書き込みは、シーケンシャル(順次)書き込みのみであり、一般的に書き込みのパフォーマンスで劣るRAID 5は、避けた方がよい。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。