排他制御の落とし穴を避けるインデックス設計:Dr. K's SQL Serverチューニング研修(5)(3/3 ページ)
最小限の非クラスタ化インデックスを付与する。
それが更新効率アップのツボ
あるお客さまの例で、「何でこんなに多くの排他がかかるのか?」というので原因を調査したときのことです。このお客さまは受注処理のデータベースとしてSQL Server 2000を使っていました。
SQL Server 2000は、1つのテーブルに対してクラスタ化インデックス1つと、非クラスタ化インデックスを249まで持てるようになっています。お客さまにしてみれば、検索を早くしたい。そこで検索性を上げるなら、いろんなカラムに対して非クラスタ化インデックスをたくさん張ればいいと考えたようです。しかし、データベースのINSERT/UPDATEから見ると、複数の非クラスタ化インデックスというのは、インデックス情報の保守コストの観点からは邪魔でしょうがないわけです。可能ならクラスタ化インデックスだけにしたいくらいです。
受注管理システムでありがちな失敗例
例えば受注伝票のヘッダに、1つの受注ごとにユニークな値として「受注番号」、そしてどこの部門が受注したのかを示す「部署コード」があるとしましょう。こういった業務システムでは、部門ごとに受注を集計するような検索を頻繁に行うことになるでしょう。
そこでデータベースを図5のように設計したとします。ここでは、「受注ヘッダ表」と「部署コード表」を作成しています。「受注ヘッダ表」の「受注番号」列はPKとしてクラスタ化インデックスを設定し、Identity属性の自動採番でユニークな値を取得しています。「部署コード」列はFKとして「部署コード表」と関連付け、部署ごとの受注の検索性能を高めるために非クラスタ化インデックスを設定しました。
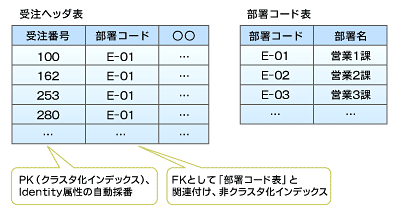 図5 チューニング前の受注ヘッダ表
図5 チューニング前の受注ヘッダ表問題なのは「部署コード」の非クラスタ化インデックスです。非クラスタ化インデックスは、クラスタ化インデックスと同様にBツリー構造になっていますが、リーフノードはデータページで構成されていません。代わりに、行ロケータとしてクラスタ化インデックスのキーを格納しています。例えば部署コードが「E-01」であれば、その配下に受注番号として「100」「162」「253」「280」といったキーがぶら下がっているのです。普通の組織であれば部署コードの数など大して多くはありません。これに対して受注番号は大量に積み上がっていきます。つまり、1つの部署コードに対して受注番号は、1対Nの関係になるのです(図6)。
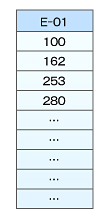 図6 非クラスタ化インデックスの構造
図6 非クラスタ化インデックスの構造ここで新たに受注番号「302」を挿入するとしましょう。クラスタ化インデックスである「受注番号」はインデックス情報の参照によってどの位置に挿入されるか決定されます。一方、「部署コード」は図6のように、1つの部署に対してインデッス情報がひと固まりの排他の単位になります。キーに対して1対Nの関係になるわけですから、かなり大きな排他の固まりになってしまう可能性があります。これで大きくパフォーマンスが落ちていたのです。
そこで受注ヘッダテーブルのインデックス構造を変更し、PK(クラスタ化インデックス)を「部署コード+受注番号(部署単位に自動採番処理)」の複合キーに変更しました(図7)。PK内に部署コードを持つために、従来のFK用非クラスタ化インデックスは不要となりました。これで更新処理で発生していたロックの数を大幅に削減できたのです。これはデータデザインによるチューニングといえますが、非常に難しいノウハウなのです。
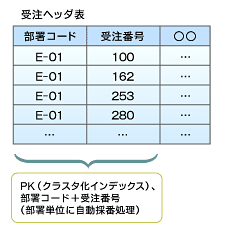 図7 チューニング後の受注ヘッダ表
図7 チューニング後の受注ヘッダ表動かしてから必死で解決法を探るのではなく、
最初から「正解」を求めて頑張ろう
さて、いろいろと「現象から原因を探る」話をしてきましたが、最も効果的なパフォーマンス・チューニングというのは、実はこうした「動かしてからクエリチューニングにより解決策を探る」ことではないと私は思っています。もちろん開発段階ですべての問題がクリアにできれば苦労はないと、誰もが思っているでしょう。しかし思っていながら、ついついスケジュールに流されていってしまいがちです。
数年前、ある大規模でしかも非常に短期間での開発を要求されるプロジェクトがありました。私はここでデータベースのデザインレビューを担当したのですが、全開発チームの設計したアプリケーションすべてに対して念入りにレビューを加えた結果、開発が1カ月止まりました。大急ぎの案件を1カ月も止めたのですから、当然ものすごい非難を浴びましたが、いざプロジェクトが再始動してみたら、カットオーバーの2カ月前には、ありがちな整合トラブルなども起こらず、もう何もすることがなくなってしまったのです。
別に私の手柄自慢をする気はありません。しかしデータベース設計は、1つ間違えたらもう取り返しがつかないということをよく知ってほしいと思います。それを慌ててやってしまって、稼働してからクエリヒント句やインデックスチューニングウィザードなどを用いた安易な方法でごまかしながら、その日の帳尻を合わせているケースが少なくありません。基本設計さえきちんとしていれば、ある程度のことはSQL Server 2000のオプティマイザーが最適化をしてくれるのに、いびつに作ってしまったのを必死で補っている。そんなのは、私にいわせればとてもチューニングとは呼べません。
チューニングはとにかく経験がものをいう世界です。それだけに、経験の浅い人はwait事象が発生していることに気付いてすらいないことも多いのです。大事なのは知っていることではなくて、いつも障害や問題を示してくれるパラメータに、素直に目を向けていま何が起こっているのかを知ろうとする姿勢です。今回お話ししたことの大方は、sysperfinfoを見れば分かることです(前回の2ページ目、図3を参照)。
排他制御だってちゃんと確認する方法があります。sp_lockというストアドプロシージャを使えば、プロセスがどういう大きさのどういう排他制御をかけているのかが見られます。
時間が世間の何倍もの速さで流れているITの世界ですが、自分の経験を大事に積み重ねて、なおかつ正しい知識をもってツボに当たれば、必ずパフォーマンスは上がります。頑張ってください!(次回へ続く)
監修者プロフィール
株式会社CSK Winテクノロジ 執行役員 兼 技術推進担当。
熊澤 幸生(くまざわ・ゆきお)
メインフレーム環境で20年近くデータベース関連のITプロジェクトを数多く経験。また1979年から1983年まで米国に駐在し、データ主導型システム設計を実プロジェクトで学ぶ。1994年、アスキーNT(現、CSK Winテクノロジ)設立に参加し、SQL Server Ver 4.2からSQL Server 2000までシステム構築、教育にかかわってきた。現在同社執行役員 Chief Technology Officer。また、SQL Serverユーザー会「PASSJ」の理事として活動中。
- キャッシュを無駄遣いしないようにクエリを書く
- 64ビット時代の「バランスド・システム」
- DB管理者がいますぐ確認すべき3つの設定
- 内部動作を知らずしてチューニングは語れない
- CAT秘伝、バランスド・システムの考え方
- パフォーマンスを語るために歴史を語ろう
- チューニングに大変革をもたらす動的管理ビュー
- SQL Server 2005でガラッと変わった個所とは?
- チューニングとは……スレッドとの格闘に尽きる
- 進化するCPUをパワー全開で走らせるテクニック
- I/Oボトルネックの病巣はこれで究明できる
- I/Oチューニングを成功させる必修ポイント
- 排他制御の落とし穴を避けるインデックス設計
- 排他制御メカニズムから“待ち”原因を究明する
- パフォーマンスを満たす物理メモリ量を算出する
- 誰も知らないメモリ・チューニングの極意を教えよう
- SQL Serverというブラックボックスを開いてみる
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。