進化するCPUをパワー全開で走らせるテクニック:Dr. K's SQL Serverチューニング研修(8)(2/3 ページ)
マルチプロセッサ構成を前提に設計された
SQL Serverのアーキテクチャ
これまでの連載でもお話ししたように、SQL Serverのハードウェアを選ぶ場合には、メモリが非常に大事です。またI/Oも、複数のドライブレターがOSから見えないと負荷分散できません。それと同じように、SQL ServerはCPUも1つでは足りないという話をしましょう。
まず、OracleとSQL Serverの考え方の違いを見ておきます。SQL Serverは、IA32bit版であれば、カーネル=OSの共通領域である4Gbytesの仮想メモリ空間があり、その下位にSQL Serverのエンジン部分があって、さらに複数のスレッドがある……という構造になっています。こうした構造には、いちいち自分の仮想メモリ空間の外に出ないで、エンジンとスレッド間のやりとりができるという特徴があります。1プロセスの中に、n個のスレッドを立てるというやり方ですね。これは、SQL Serverのとても良いところです。
一方、Oracleはエンジンの内部に複数のユーザープロセスが立ち上がっていて、各プロセスの仮想メモリ空間を超えて連動しなくてはならないことがあります。SQL Serverは単一メモリ空間の中で複数のスレッドを動かして、スレッドとSQL Serverエンジンとのやりとりのオーバーヘッドを最小化する設計になっています。データベースサーバが使用する共有メモリ領域があって、複数の処理単位が協調動作する場合、アドレス空間をまたがないというのは、パフォーマンスを確保するうえで非常に大事なのです。
そのため理想的にいえば、スレッドの数だけCPUが存在すればいいわけです。いうまでもなく、たくさんのCPUがあった方が並列処理がスムーズに動くからです。そういう意味では、SQL ServerのエンジンはSMP(Symmetric Multi-Processor)と呼ばれるプロセッサ構成を前提にアーキテクチャが作られているといってよいでしょう。
CPUを増やすと突き当たるバスクロックのボトルネック
ではCPUというのは、いったいいくつあればいいのでしょうか。私は普段から「そこそこのトランザクション量の場合、最低でも4つの物理ソケットを持つマシンが必要」といっています。4つの物理ソケットを持って、8Gbytesぐらいのメモリを積んで、ファイバチャネルのストレージを持ったサーバマシンなら、だいたい500万〜1000万円くらいで買えます。これくらいのマシンは最低でも用意してほしいものです。
とはいえ4CPUのユーザーだと、まだ中規模くらいのトランザクション量です。もっと大規模なデータベースではどうでしょうか。実際に私が手掛けているユーザーには、もっと大規模なケースも多いわけです。
あるメディア系のマネーサイトでは、証券取引所から株価データが、1日に百数十万件来ます。それも取引所が開いている4時間半の間に集中します。一方で、そのデータを参照しに来るインターネット経由のクライアントが、1日に600万ページビューぐらいあります。こうなると、4CPUの数百万円クラスのマシンでは耐え切れません。
従来であれば、こうした大規模システムをSQL Server 2000で構築するなら、Itanium 2を16個ないし32個搭載した数億円規模のサーバを買わないといけませんでした。その理由は、ハードウェアの構造的限界です。従来のアーキテクチャでは、CPUを複数搭載しても、CPUとメモリを結ぶFSB(フロントサイドバス)の動作速度に限界があったのです。FSBのクロック数は、いまだに600MHzくらいで、GHzに達していません。このためCPUをどんどん増やしていくと、ここの部分がボトルネックになってしまうのです(図3)。
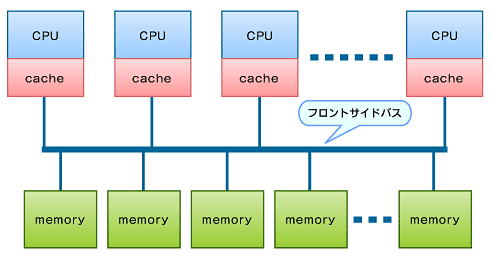 図3 FSB(フロントサイドバス)
図3 FSB(フロントサイドバス)トランザクション処理の過程で、CPUのキャッシュの中にデータを取り込んで、データを更新しますが、更新したらメモリに書き込まなくてはなりません。そのためにはメモリに対して、排他制御しなくてはいけません。この排他制御の待ちが、積み重なってオーバーヘッドになっていってしまうのです。
この結果、例えばCPUが4つあって、1つのCPUパワーを100としたら、合計400の能力が出るかというと、出ません。だいたい8掛けくらいになってしまいます。だから、4つの物理コアを乗せても320、つまり3.2倍くらいしか能力が出せません。CPU同士の排他制御によるオーバーヘッドと、なおかつバスのクロックがCPUに比べると非常に遅いものですから、パフォーマンスが抑えられてしまうわけです。
CMPからNUMAへと進化を遂げてきた
CPUのアーキテクチャ技術
FSBのボトルネック問題を打開するために開発されたのが、CMP(Cellular MultiProcessor)です。このアーキテクチャを搭載したのは、Unisys製のES7000です。ES7000の考え方は、CPUを4つくらいまとめたものを「セル」と呼び、その向こう側に「クロスバースイッチ」を入れて、その向こう側にメモリのモジュールの塊を置き、どのCPUでもすべてのMSU(メインメモリ)にアクセスできるような形にしているのが特徴です。

通常は、この間の仕組みのことを「バックプレーン」と呼びます。この部分を作るために、かなりのノウハウとコストがかかるため、こういう構造を持ったマシンとなると、通常、数億円単位の価格になってしまいます。ES7000は、ちょうどWindows 2000がリリースされた2000年くらいに出てきた最初のアーキテクチャでした。ところがこれも、基本的にはクロスバーを介してメモリにアクセスしているだけで、メモリに対する排他制御のメカニズムは従来のマシンとあまり変わりません。
そこで次の世代に出てきたのが、「NUMA(Non-Uniform Memory Architecture)」です。これはもともと1994年ごろ、Windows NT 3.1の時代にシーケントという会社があり、32bitのCPUを256個くらいつなげたモンスターマシンを作るテクノロジを持っていました。その後この会社はIBMに買収され、そこで開発されたのがNUMAだったのです。このアーキテクチャを使っている代表格は、HPの「Integrity Superdome」やIBMの「xSeries」です。ほかにもSilicon Graphics、NEC、富士通など、最近のモンスターマシンは軒並みNUMAのアーキテクチャを使っています。
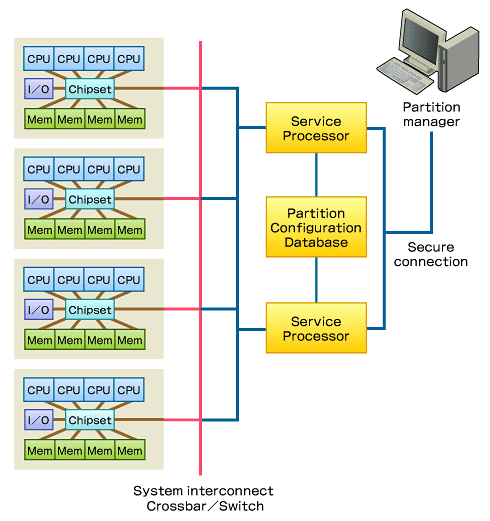 図5 NUMA(Non-Uniform Memory Architecture)
図5 NUMA(Non-Uniform Memory Architecture)では先ほどのES7000のアーキテクチャと比較して、NUMAにはどういった特徴があるのかというと、こちらもセルという単位で1つのユニットの中に複数のCPUを持っています。ところが、このセルの中にはメモリも入っています。これは、「CLM(セルローカルメモリ)」と呼ばれます。
ここに込められた考え方というのは「なるべく自分のセルの外に出ないで、プログラムを実行してしまおう」ということです。そうすれば、余計な排他制御がいらなくなるからです。そういう概念を持っているNUMAという新しいアーキテクチャは、今後間違いなく主流となっていくでしょう。というのも、当初何億円という価格でしか買えなかったNUMAのアーキテクチャが、いまでは1000万円台で買えるようになってきたからです。
図5を見るとパーティションマネージャと各CPUを結ぶ部分が赤色の線になっています。これがクロスバースイッチです。自分のローカルメモリでヒットしなかった場合は、隣のセルにメモリをもらいにいくというアーキテクチャなのです。もう1つのすごいところは、セル単位にそれぞれ「ネットワークを制御するセル」や「I/Oを制御するセル」といった個別の特徴を備えている点です。セル単位にI/Oに特化したり、ネットワークに特化したりといった形で役割を分担しているのです。
またAMDのCPU回路図を2006年の1月に目にして、ショックを受けました。AMDは非常に進んだアーキテクチャを持っています。何が進んでいるのかというと、フロントサイドバス経由ではなく、CPUそのものがローカルメモリを制御できるアーキテクチャを持っているのです。これが現在、AMDの人気が高い理由です。実はこれはNUMAのアーキテクチャを、クロスバースイッチなどまで含めてハードウェアに内蔵してしまったのです。そういう、非常に新しいアーキテクチャが盛り込まれている点に注目してください。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。