高負荷なのに片方のサーバにだけ余裕が……なぜ?:Linuxトラブルシューティング探偵団(1)(2/4 ページ)
アクセスログの確認
このシステムでは、mod_jkによる振り分け方法として、リクエスト数に基づいて均等に振り分けるアルゴリズム(method=Request)を設定していました。この結果、2台のアプリケーションサーバには、均等にリクエストが振り分けられるはずです。
しかし、現実にCPU使用率の偏りが発生しており、前述のとおりThreadBusyのスレッド数も異なることから、単純に「設定と異なり、実際に処理しているリクエスト数が違うのではないか?」と考えました。まずこの考えを確かめるため、本当にmod_jkが均等にリクエストを振り分けているのか、アクセスログを調査して確認することにしました。
■mod_jkログを取得し、調査
mod_jkのアクセスログを取得するには、以下のような設定を行います。
* mod_jk.conf (httpd.conf)の設定 |
ログの粒度を「info」レベルにすることで、失敗した場合のリトライ状況などが分かります。また、JkRequestLogFormatでは「使用したworker名」「クライアントIPアドレス」「処理時間」および「実際に振り分けたworker名」を出力するように設定しています。実際のログは、以下のように出力されます。
* logs/mod_jk.log |
|
このログファイルを集計した結果が表2です。
mod_jkが均等に振り分けており、AP1とAP2のアクセス数はほぼ均等になっているようです。残念ながら(?)、この面での問題はなさそうです。
次に、各アプリケーションサーバに対するアクセス数を時間ごとに解析してみました(図2)
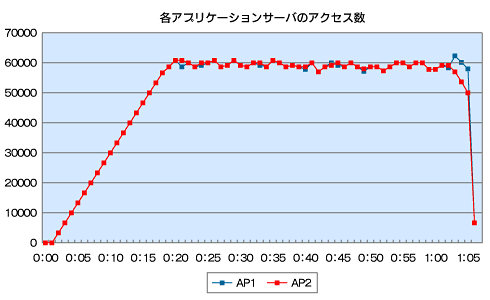 図2 各APへの時間ごとのアクセス数
図2 各APへの時間ごとのアクセス数これを見ても、mod_jkは均等にリクエストを振り分けています。しかし、各リクエストの処理時間を見ると、高負荷時にはAP1側のリクエスト処理時間が長くなっていることが分かりました。
ガベージコレクションも怪しい
一方、Tomcatに限らずJavaでのCPU使用率トラブルは、ガベージコレクション絡みのことも多いので、その状況も確認してみます。
Javaでは、動的に確保したメモリを、不要になった場合に自動的に削除します。この機能を「ガベージコレクション」(GC)といいます。
ガベージコレクションには、「MinorGC」と「MajorGC」の2タイプがあります。MinorGCは比較的若い世代のオブジェクトのみを対象に消すので、対象となるメモリ量も少なく、処理が早く終わります。その代わり、古い世代のオブジェクトは消えません。一方MajorGCは、古い世代のオブジェクトが多くなってきた場合に処理を行います。全メモリを対象に行われ、使用されていないオブジェクトはすべて削除されます。その代わり時間がかかります。
基本的に、GCの処理はすべての処理を止めて行われるため、Javaでは、2段階に分けた世代別ガベージコレクションによって、停止時間が短くなるように工夫されています。詳細はJava Solutionの記事「“Stop the World”を防ぐコンカレントGCとは?」を参照してください。
今回の検証では、jstat(コラム参照)でGCのカウントなどを定期的に収集していました。これをまとめた結果が表3です。
|
これを見ると、CPU使用率の高いAP1サーバで、MinorGCの回数が少し多い状態になっていることが分かります。ですが、そう頻繁に発生しているということもなく、差自体も少ないため、GCの動作的には問題はなさそうです。
とはいえ、実際にAP1のCPU使用率を高くしているのは、GCの差によるものが1つの原因だと判断できます。
一方、MajorGCはどちらも同じ回数発生しています。発生時間を見ても、負荷の高いAP1の方で早い時間にMajorGCが行われていますが、ほぼ同じタイミングでした。MajorGCの時間も短く、CPU使用率は常に偏っている状態ですので、一時的に発生するMajorGCとは関係なさそうです。
この結果を基に、おそらくアプリケーションサーバに残っているアクティブなスレッド数が違うため、それだけ多くのオブジェクトがヒープメモリに存在し、結果としてGC回数も増えると予想されます。
以上で、CPU使用率が高くなってしまう理由をだいたいつかむことができました。しかし、なぜスレッド数に違いが出るのかについて、まだ調査が必要です。
■DBのスロークエリログ
片方のアプリケーションサーバだけクエリの処理が遅くなるというケースも考えにくいことですが、問題の切り分けのため、下記の設定を施して、念のためデータベースのクエリの処理時間を確認しました。
クエリの処理時間取得時のMySQLの設定(my.cnf) |
ですが結果は予想どおりで、処理に1秒以上かかっているクエリは存在しませんでした。どうやらこの線もハズレのようです。
コラム jstatの使い方
jstat(http://java.sun.com/j2se/1.5.0/ja/docs/ja/tooldocs/share/jstat.html)はJDKに同梱されているツールで、下記のように動作中のJVMの状態を確認できます。
# jps |
GCの確認には、Javaの起動オプションで指定する方法もありますが、jstatの場合は基本的に、状態を確認する対象の起動オプションなどを変更する必要がありません。使い方は以下のとおりです。
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]] |
引数の意味は下記の通りとなります。
| 引数 | 内容 |
option |
表示する情報のオプション。gc以外にもあります。 |
lines |
情報のヘッダーを表示する間隔(行数)。 |
-t |
タイムスタンプの表示。JVMが起動してからの経過秒数が表示されます。 |
vmid |
対象のJVMのID(jpsで調べられます)。 |
interval |
秒(s)かミリ秒(ms)で表示の間隔を指定します。 |
count |
表示する回数。 |
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。