第99回 x86プロセッサをいっぱい並べたら何になる?:頭脳放談
Intelが数十個プロセッサを並べたGPUを発表。なぜx86ベースなのか? Pentiumライクなコアを採用しているのは? 何でGPUなのか? を解説。
最近の自分の「暮らしぶり」を客観的に見てみれば「プログラマ」じゃないかと思うくらいに「プログラミング」に費やしている時間が多いことに気付く。けれども自己規定は「あくまでハードウェアの部品屋」のつもりだ。本物のソフトウェア屋さんと異なるのは、「取りあえず」自分のハードウェアを意図どおりに動かすためのコードができさえすれば、「ソフトウェアの製造プロセス」などにはまったく無頓着であることからも分かる。本物のソフトウェア屋さんではそうはいかない。「要件の定義」などから始まって、ソフトウェア工学的な手法やプロセスの適用と品質の確保、後々の保守や再利用性までが重要であって、「個人の能力の範囲で、ただハードウェアが動けばよい」というようなゴールでコードを書いている「暮らしぶり」はあり得ない。
そんな不心得者なので、数年前まで一応ACM(Association for Computing Machinery)にも入っていたのにとっくにやめてしまっていた。ソフトウェア工学主体の立派な学会に筆者のような「不心得者」が入っているのは問題あり(当方にしたら「立派なソフトウェア工学」の論文を読むために年会費を支払う余裕もなかった)というところ。時折再入会を勧めるダイレクト・メールが来るものの黙殺していたのだが、罰は当たるものだ、と感じた次第だ。ちゃんとACMもウオッチしていなければ。
Larrabeeの正体は?
今回取り上げるのは、Intelのx86マルチコア。ただし、コアは2個、4個というレベルの「マルチ」ではなく、数十個という「メニー」コアのマシンである。その名は「Larrabee(ララビー)」である。半導体系やハードウェア系の学会ではなく、発表されたのはACMだったので、あわてて久しぶりにACMのサイトに行き、手続きをして論文を手に入れた(ACMの「Larrabeeの論文が入手可能なWebページ」)。まじめに「ソフトウェア工学」を勉強していれば、こういうドタバタはないのになぁ。
さて、そのLarrabeeである。表面的には「x86のコアを並べて、GPU(グラフィックス・プロセッサ)を作ってみました」というのが、そのコンセプトといってよいだろう。実は「最強のコンピューティング性能を持つチップ」はメインのプロセッサではなく、グラフィックスを担当するGPUになって久しい。それもメインのプロセッサとは性能のけたが違ってしまっている。そのギャップをx86側から埋めて、「最強のコンピューティング性能を持つチップ」の座をもx86で取り戻そう、という感じにも見えるのだ。
さてその道具立てと見るや、まずコアはいろいろ改造が施されている(当然64bit対応もされている)ものの基本的には「イン・オーダー(命令を記述されている順に実行)のPentium」である。ほかにアウト・オブ・オーダー(命令を記述の順番ではなく、実行可能なものから順次実行)のコアがいろいろあるのに、あえて古典的なイン・オーダーのコアを使ったのは、イン・オーダーのコアのシンプルさ、つまりチップ面積対性能比、消費電力対性能比などの良さにあろう。確かに1個のコアで比べればアウト・オブ・オーダーのコアの性能は高いが、比較的小さな性能向上、例えば50%増しのために2倍とか3倍とかの面積と電力を使っているのも確かだ。そのため、多くのコアを並べて速度を稼ごうとするLarrabeeでは「性能比の良さ」に立ち戻る必然的な選択が必要となる。
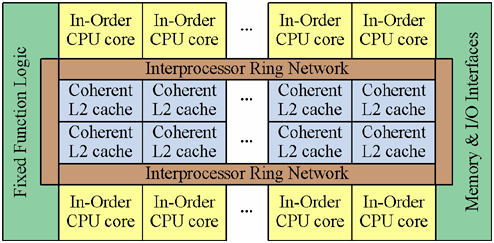 Larrabeeのプロセッサ接続構成
Larrabeeのプロセッサ接続構成論文「Larrabee: A Many-Core x86 Architecture for Visual Computing」の中で紹介されているLarrabeeのプロセッサ接続構成。「In-Order CPU core」はPentium相当のイン・オーダー・プロセッサである。それらを「Interprocessor Ring Network」で相互に接続している。
しかし、やたらとイン・オーダーのスーパースカラ・コアを数並べても、現状のGPUの「巨大な」演算性能にはなかなか届くはずがない。GPUはグラフィックス特有の並列度を生かした演算回路の塊と化しているからだ。スカラ・コアだけでなく、もっと並列性の高い演算回路が必要である。そのため、イン・オーダーのスーパースカラ・コアに対して、スカラ側と独立した16要素幅のベクトル(並列処理に適するデータ)演算処理ユニットが組み合わされている。演算性能そのものはこちらで稼ぎ出す、ということだ。現行の主力プロセッサの持つSIMD系の演算パスと比べても、数値演算性能は格段に高い、といえるだろう。これによりコアとしては、ベクトル演算処理能力自体はマルチコアの現行主力プロセッサ・ラインよりもはるかに強力だが、スカラ部分の性能は多少劣るベースが出来上がる。これにローカルな1次キャッシュと、みんなで共有されるのだがローカルにサブセットを持てるという少々変則的な2次キャッシュを組み合わせ、これを機能単位として「多数並べ」、インターコネクションとしての太いリング・ネットワークに結合することでLarrabeeが出来上がる、ということのようだ。
「多数」というのは、当然実装によりコンフィグレーション可能なようだが、例えば8プロセッサを1組として6組で合計48プロセッサ、といったレベルの「多数さ」である。個々のプロセッサのスカラ性能はマルチコアのスーパースカラ・マシンより落ちるとしても、最大4個程度のマルチコア・マシンに比べたら、48個のコアの「額面」性能は大きい。ましてや各コアの持つ強力なベクトル処理ユニットの演算能力を考えれば、現状の主力プロセッサの性能とは隔絶した能力があることは確かである。
汎用プロセッサを並べることがキモ
しかし、現状のGPUも主力プロセッサの性能とは隔絶した演算能力を持つ点では同様である。単に「並べて」「幅を広くして」演算性能を上げるという「軍拡競争」をGPUと行うのであれば、あえてLarrabeeのようなx86コアを並べる必然性はないだろう。Larrabeeが面白いのは、「汎用プロセッサ」の使いやすさのまま、GPUをしのぐ性能が得られる、という点にあるのだ。
GPUの場合、例えばOpenGLのライブラリの上でプログラミングをしている人は多いだろうが、GPUの演算パスの中にまで踏み込んでプログラミングをしている人がどれだけいるだろうか? ほとんどの人にとっては、GPUは「一皮被った」状態でプログラミングするものとなっている。強力な演算パスがあるといっても、周辺はグラフィックスに特化した専用ハードウェアが折り重なっており、「汎用」に簡単にプログラムできるものでもないだろう(筆者は「一皮被った」GPUプログラミングすらやったことがないので、偉そうなことはいえないが)。
ところが、Larrabeeは、ほとんど特殊なハードウェアを持たない。GPUでは専用回路で行っている部分も多くはソフトウェアとして実装されている。そしてそのソフトウェア自体は、普通のx86のコンパイラの吐き出すコードであっても実行可能なのだ。何せコアは「普通のPentium」と互換性がある。もちろん、新たに加えられたベクトル演算処理部を使うためには再コンパイルが必要なはずだが、少なくともIntelは、普通のx86コンパイラ用のソースからベクトル化可能な部分を抽出してベクトル演算処理部を使うようにするコンパイラを持っているようだ。ほかにスレッド処理とか、ベースになった「シンプルなPentium」が持っていなかった拡張部分についてはAPIが提供されるようなので、これを呼んでやればよい。
これはマルチコア・ベースの現行主力プロセッサでワークロードを分散するのとはまた異なり、多数ある「演算処理性能の高い」個別の各x86にソフトウェアのごくごく一部のステージだけを担当させ、それらをさらにつないで行って全体として1個の「高性能」ソフトウェアを実現できる、ということである。
つまりLarrabeeの場合、GPUのような特殊な環境にアクセスできなくても、「普通のx86」プログラマが直接、並列度の高い「メニー」コア・プロセッサの演算パスを使いまくるようなコードを書ける可能性がある、ということなのである。
もちろん、GPUとしてLarrabeeを使うのはまっとうな使い方ではあるが、裏返せばGPUとしてだけLarrabeeを使うのはもったいないということでもある。昔風にいえば「汎用のスパコン」、それも使い慣れた「x86」ベースの命令セットが走るマシンが手に入る、といったらよいだろうか。
さてそれを一体何に使うのか? ソフトウェア工学の本道を歩むACMの会員の皆さま方に提起してみた、というのが今回の発表なのかもしれない。ちゃんとソフトウェア工学を勉強しないとイケナイというわけだね。
■関連リンク
- Larrabeeの論文が入手可能なWebページ[英語](ACM)
- Larrabee: A Many-Core x86 Architecture for Visual Computing[PDF](Intel)
筆者紹介
Massa POP Izumida
日本では数少ないx86プロセッサのアーキテクト。某米国半導体メーカーで8bitと16bitの、日本のベンチャー企業でx86互換プロセッサの設計に従事する。その後、出版社の半導体事業部を経て、現在は某半導体メーカーでRISCプロセッサを中心とした開発を行っている。
「頭脳放談」
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。