文字化けに関するトラブルに強くなる【実践編】:Oracleトラブル対策の基礎知識(6)(2/4 ページ)
JavaベースのWebアプリケーションのシステム構成と変換表
Javaは、文字列の内部処理をUnicode(正確にはUTF-16と呼ばれるUnicodeの表現方法の1つ)を用いて行っています。図1では、クライアントのWebブラウザとのデータのやりとりをWindowsのシフトJIS(MS932/Windows-31J)で行っていますから、JavaはシフトJISとUnicodeのデータ変換を行う必要があります。
一方、Oracle側、すなわち図1におけるOracle JDBC Thin DriverとOracle Databaseの部分に着目してみましょう。Oracle JDBC Thin DriverはJavaのコンポーネントですから、Java VMとの間のデータのやりとりはUnicodeとなります。このため、Oracle側での文字コード変換では、UnicodeとシフトJIS(JA16SJIS)のデータ変換を行う必要があります。
これらの説明を踏まえて、文字コードの変換処理を整理すると、図3のようになります。
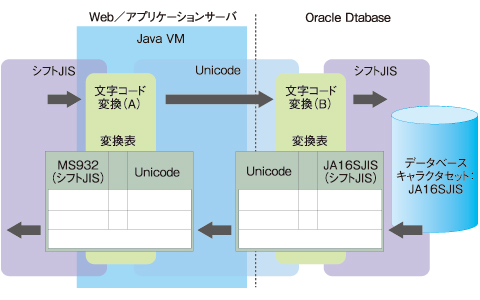 図3 JavaベースのWebアプリケーションの文字コード変換例
図3 JavaベースのWebアプリケーションの文字コード変換例図3の特徴は以下の2点です。
・クライアント環境がシフトJISであり、データベースキャラクタセットがシフトJIS(JA16SJIS)であるにもかかわらず、システム構成上の理由により文字コード変換が実行されている
・文字コード変換(A)はJava VM内で実行され、一方、文字コード変換(B)はOracleにより実行されている
「〜」文字化けのメカニズム
図3に示した文字コード変換の仕組みを踏まえて、「〜」文字の文字コード変換について内部の処理を確認してみましょう。
●データベースに文字格納されるまでの文字コード変換の流れ
早速、「〜」文字がWebブラウザからWebサーバ/アプリケーションサーバを経由してOracleに格納される際の文字コード変換について確認してみます。
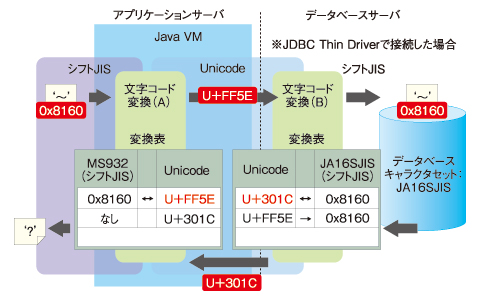 図4 チルダ文字の文字化けの仕組み
図4 チルダ文字の文字化けの仕組みまず、WebブラウザからWeb/APサーバに対して「〜」(シフトJISで0x8160)が渡されます。
次にJava VMでは、Java VMのシフトJIS(MS932)とUnicodeの対応表に基づき、「〜」(シフトJISで0x8160)をUnicodeのU+FF5Eに変換します。ここで示した「U+xxxx」とは、コードポイントと呼ばれるUnicodeにおいて文字1つずつに振られた番号です。
Oracleでは、受け取ったU+FF5EをOracleのJA16SJISとUnicodeの変換表に基づき変換します。この、Oracleによって実行される変換によって、U+FF5Eは0x8160に変換されます。
しかし、注意すべき点があります。
Oracleの変換表では、0x8160と双方向変換可能なUnicodeのコードポイントは「U+301C」として定義されています。
JA16SJISとUnicodeの変換において、Unicodeの文字データにU+FF5Eが渡されると0x8160に変換されますが、この変換はあくまでもUnicodeからJA16SJIS方向への片方向の変換においてのみ適用されます。このため、逆向きのJA16SJISからUnicode方向への変換では、JA16SJISの入力データに0x8160を与えた場合、U+FF5EではなくU+301Cに変換されてしまいます。
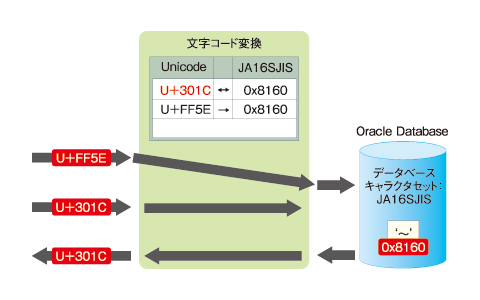 図5 Oracleにおける「〜」文字の変換(JA16SJISの場合)
図5 Oracleにおける「〜」文字の変換(JA16SJISの場合)内部でこのような変換処理が実行されるため、「〜」をOracle Databaseに格納する方向では、結果的に入力された0x8160がそのままデータベースに格納されます。
しかし、「〜」をOracle Databaseから取得する際に問題が発生します。格納した「〜」がOracleからWeb/APサーバを経由してWebブラウザから戻される際の文字コード変換について確認してみましょう。
まず、OracleからWeb/APサーバに「〜」(シフトJISで0x8160)が返されます。Java VMとOracle JDBC DriverはUnicodeでデータのやりとりを行いますから、「〜」文字に相当するシフトJIS「0x8160」はOracle側でUnicodeに変換しなくてはなりません。
この変換はOracleの変換表に基いて実行されますが、先に述べたとおり、JA16SJISからUnicode方向への変換の場合、入力データとして0x8160を与えた場合、U+FF5EではなくU+301Cに変換されてしまいます。
次にJava VMでは、Java VMのシフトJIS(MS932)とUnicodeの対応表に基づき、U+301CをシフトJISに変換しようとします。しかし、変換表にはU+301Cの変換ルールが存在しません。そのため、変換対象がない場合のデフォルト文字である「?」に変換してしまいます。このため、Webブラウザには「?」が返され、文字化けすることになります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。