“動物図鑑”で知るCouchDBの特徴:ゆったリラックス! CouchDBがあるところ(1)(1/3 ページ)
ドキュメントを手軽にWebで公開したいとき、リレーショナルデータベースで実装することに違和感を覚えることはありませんか? CouchDBはそのようなニーズに合った、新しいデータベース管理システムです。CouchDBを知り、リラックスしながら実装をしていきましょう(編集部)
CouchDBとは?
CouchDB(カウチDB)はドキュメントをデータとして管理し、Webで公開することに最適化されたデータベース管理システムです。CouchDBの“ドキュメント”は報告書、仕様書、議事録といった文書や、名刺、プロフィールといったデータの集合のことを指しています。また、JavaScriptのソースコードをドキュメントの一部として配置することも可能です。
OSSとして一般へのリリースが始まったのは2007年後半ころからになります。その後、2009年3月にApache Software Foudationの正式なプロジェクトとして最初のリリースがありました。現在も継続して開発が続けられています。CouchDBは主にErlangというプログラミング言語で実装されています。
CouchDBのコミュニティによるWebサイトやMLには、「Relax(リラックス)」という言葉がよく登場します。データベースの設計・構築・操作について、開発者に極力リラックスできるデータベース環境を提供するというコンセプトが、CouchDBの各仕様に込められているように筆者は感じています。筆者はこの「リラックス」というコンセプトがとても気に入っています。そしてリラックスとうたいながらも、実際にふたを開けてみると従来のデータベースマネジメントシステムにはなかった、さまざまな新しい試みが実装されており、データベースが好きな開発者にとって刺激的な要素が多く盛り込まれている点も魅力の1つです。
この連載ではCouchDBの機能や用途を解説していき、最終的にはその内部構造まで迫る予定です。連載第1回目の今回は、CouchDBの主な特徴と用途、実際にCouchDBをインストールするところまでを説明していきたいと思います。
特徴1:JSON形式による柔軟なデータ構造
CouchDBは、JSON形式という書式を介してデータの入出力を行います。JSON形式は各ドキュメントの相違に対して、柔軟に対応することができるという利点があります。
例えば、ある動物園のWebサイトで動物図鑑を公開する場合を考えてみましょう。動物図鑑の1ページを1つのドキュメントに見立て、データ構造を設計します。図1を見てください。データ構造をリレーショナルデータベース(以下、RDB)向けに設計した場合と、CouchDBのドキュメントとして設計した場合を示しています。
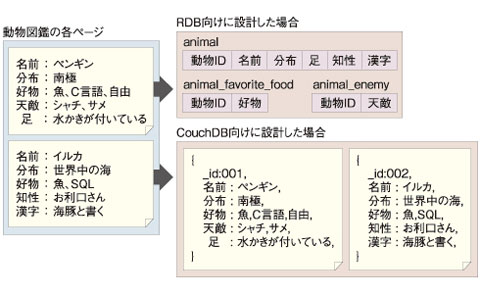 図1 RDBとCouchDB、設計思想の違い
図1 RDBとCouchDB、設計思想の違い例を見ると、「ペンギン」と「イルカ」のページでは図鑑に掲載する項目が異なります。RDB向けに設計するとその動物固有の項目も共通のカラムとしてテーブルへ定義しなければなりません。図1の中では「ペンギン」のページに「足」という項目がありますが、「イルカ」には不要な項目です。複数の動物への対応を考慮すると、テーブルの構造が複雑で冗長になります。ある動物では使用しない項目にNULLが入ることになり、図鑑をブラウザで表示するときにアプリケーション側での対応が増えるでしょう。
また、RDBの場合は新しい項目を含むデータをすぐに追加・更新することができません。テーブルの構造を前もって再定義しておく必要があり、これには時間がかかります。一方、CouchDBはJSON形式を用いて、スキーマレスなデータの定義方法を提供し、RDBで発生する上記のような課題を解決しています。ドキュメントの構造はドキュメントごとに定義するため、「ペンギン」と「イルカ」で取り扱う項目にどれほど相違があっても気にする必要はありません。また、データの追加・更新と同時にデータの構造が決定することから、未知のデータ構造を持つデータであっても即座にDBに取り込むことができます。
例の中でもう1つ注目したいことがあります。「好物」の項目に設定されている値の数が動物ごとに異なる点です。RDBでは「繰り返し項目」になりますから、正規化によるテーブルの分割を検討することになるでしょう。CouchDBの場合は繰り返し項目を「配列」として1つの項目の中に含めることができます。
どちらの方法が優れているかを決めることはできませんが、ドキュメントのように複数の項目を、強いまとまりとしてのみ参照するような場合は、無駄な結合処理を必要としないCouchDBの方が使いやすいと思います。
特徴2:URIによるドキュメントマッピング
CouchDBは、各ドキュメントに対して一意なURIを割り当てます。ドキュメントをネットワーク上に公開するにあたって、CouchDBへ特別な設定を施す必要はありません。インターネット上で公開する場合も同じです。
図2は、CouchDBが管理するURIの構造を示しています。CouchDBでは複数のドキュメントを取りまとめるために“データベース”という単位を使います。URIは“CouchDBのサーバ名”→“データーベース名”→“ドキュメント名”と順にたどっていくように構成されています。
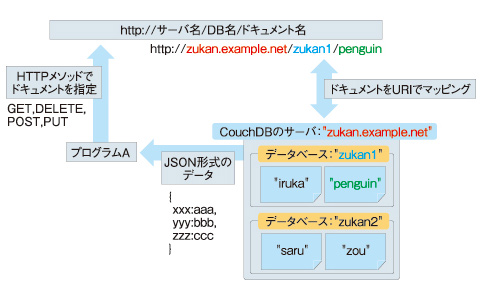 図2 CouchDBが管理するURIの構造
図2 CouchDBが管理するURIの構造URIを持ったドキュメントを操作するには、HTTPメソッドを使用します。ドキュメントを取得するならGET、更新するならPUTを使う、といった具合です。HTTPメソッドが使えるプログラミング言語であれば、CouchDBを利用するプログラムを作成することができます。単にドキュメントを操作するだけなら、WebブラウザやOSのコマンドでも問題ありません。
CouchDBを使ってドキュメントのみを公開することは、ドキュメントを“利用する側”で、目的に応じたアプリケーションの自由な作成を促していることになります。従来は、ドキュメントを“提供する側”が、ドキュメントを利用するためのアプリケーションまで一括して提供することが一般的であったと思います。しかし、ドキュメントの扱い方を利用する側に委ねたほうが適切な場合もあるでしょう。
特徴1で登場した動物図鑑の例で再び考えてみましょう。各地の動物園がCouchDBで動物図鑑を公開していたとします。ペンギン同好会は各動物図鑑のペンギンのページにある画像データだけを参照し、同好会のサイトにペンギンの写真集を編集して公開することができるようになります。ほかにも、スマートフォン向けに利便性を考慮した、ガジェットのような動物図鑑のアプリケーションを作成し、動物のデータはWeb上にあるCouchDBから取得するというのも面白いと思います。
特徴3:レプリケーションによる分散ドキュメント管理
CouchDBにはレプリケーションの機能が標準で組み込まれています。レプリケーションは、特徴2で説明した“データベース”の単位で実行されます。
RDBMSのレプリケーションと異なるのは、データの同期を取るタイミングです。一般的なレプリケーションでは、データの一貫性を確保するために、レプリケーション元でデータの更新が発生する都度、更新内容がレプリケーション先へすぐに反映されます。一方、CouchDBでは、利用者の任意のタイミングでレプリケーションを実行します。ドキュメントを作成して管理するという目的からすると、任意によるレプリケーションの方が有益な場合があります。
動物図鑑の例をもう一度、登場させてみましょう。新しい動物園が開園したとします。同時にWebサイトも立ち上げたのですが、動物図鑑をはじめから書き始めるのは非常に労力がかかってしまいます。そこで、ほかの動物園が持っている図鑑からレプリケーショを実行してドキュメントを取得します(著作権など、事前の交渉は必要ですが)。
そのあと、動物園はレプリケーションで取得した図鑑をベースにして、独自の情報を図鑑に追記していきます。これはとても効率がよいドキュメントの書き方です。CouchDB上にあるアプリケーションもレプリケーションの対象になりますから、図鑑に関連するアプリケーションの移行も簡単に実行することができます。
あるとき、動物園による動物図鑑のブームに気付いたとある出版社が、動物図鑑を書籍として編集しようと企画を立案します。出版社は各動物園のドキュメントをレプリケーションで収集し、簡単に動物図鑑を統合して出版することができます(こちらも事前に交渉が必要ですね)。CouchDBの場合、レプリケーションにはデータの複製を作ることに留まらず、ドキュメントの発展を促進させる働きがあります。
これは、近ごろよく話題になるソースコードの分散バージョン管理システムで、オリジナルからブランチを作成して独自の変更を加えていく感覚に似ていると思います。CouchDB同士なら、レプリケーションを実行するために前もって特別な設定を施す必要はありません。CouchDBでは、必要になった時点ですぐにレプリケーションを実行することができます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。