ビシッと決めるチューニング:しっかり基本編:OpenLDAPによるディレクトリサーバ運用(5)(2/3 ページ)
Berkeley DBのログバッファ
先に紹介した、サンプルとして提供されるDB_CONFIG.exampleファイルには、Berkeley DBのログバッファを拡大するset_lg_bsizeディレクティブの設定も含まれています。
ログバッファとは、Berkeley DBへ更新要求があった場合に、その更新が確定する、またはそのログバッファのスペースがいっぱいになったことが原因で、トランザクションログファイルへ書き込みが行われる前までに利用されるバッファ領域です。OpenLDAPサーバに対して大きな更新が要求される場合、このディレクティブを大きく設定することで性能の向上が見込めます。
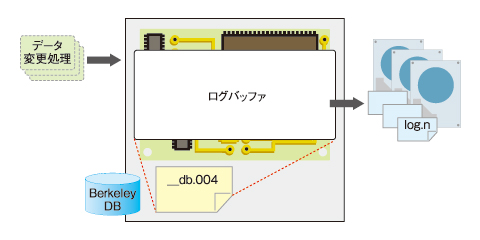 図2 ログバッファの役割
図2 ログバッファの役割set_lg_bsizeディレクティブの書式は以下のとおりです。
[書式] |
上記の設定例は、2Mbytesのログバッファを指定しています。また次のコマンド例では、Berkeley DBがログバッファ領域としてメモリマップした__db.004ファイルのサイズ(set_lg_regionmaxディレクティブで指定する、ファイル名を保持する領域を加えたサイズとなる)を表示することで、set_lg_bsizeディレクティブに設定した値が反映されていることを確認しています。
# cd /usr/local/openldap-2.4.21 |
Berkeley DBのログバッファのデフォルトサイズは32kbytesです。サンプルとして提供されるDB_CONFIG.exampleファイルには、2Mbytesが設定されています。たいていの場合は、2Mbytesもあれば更新性能が制限されることはないでしょう。
インデックスの有効性
ここからは、インデックスを利用したチューニングの有効性について説明していきます。
初めに、OpenLDAPサーバから行われるBerkeley DBへの検索について説明しておきます。OpenLDAPサーバはBerkeley DBを「Key/Valueストア」タイプのデータベースとして扱い、キーとなる値を利用して目的のデータを取得しています。リレーショナルデータベースをSQL文を用いて検索しているのではありません。
OpenLDAPサーバからインデックスを利用しない検索では、検索ベースとして指定されたエントリを起点に、検索スコープで指定された範囲のすべてのエントリに対し、dn2id.bdbファイルとid2entry.bdbファイルを検索します。これは、「DN / ID」がマッピングされたdn2id.bdbファイルと、「ID / エントリ」がマッピングされたid2entry.bdbファイルを、それぞれ「Key/Valueストア」として操作しているためです。
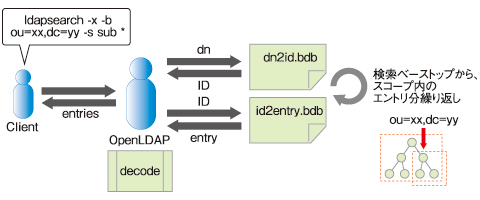 図3 Berkeley DBへの検索
図3 Berkeley DBへの検索上の図では、クライアントからの検索コマンドを「ldapsearch -x -b ou=xx,dc=yy -s sub *」としています。
このとき、なぜOpenLDAPサーバは、検索ベースとして指定されたエントリから、検索スコープで指定された範囲に含まれるすべてのエントリをBerkeley DBから取得しなければならないのか、疑問を持たれるのではないでしょうか。上記の「ldapsearch -x -b ou=xx,dc=yy -s sub *」のような検索でなく、「ldapsearch -x -b ou=xx,dc=yy -s sub uid=test1000」のようにフィルタを利用すれば、不要な検索が行われなくなると思われるかもしれません。
しかし、例えばここでの「test1000」と比較するuid属性は、OpenLDAPサーバとしては、スコープ中のすべてのエントリを繰り返し取得してみないことには、クライアントへ返すエントリがすべて正しいと判断ができないのです。より具体的には、OpenLDAPサーバは、id2entry.bdbファイルに含まれるエントリを繰り返し取り出し、デコードしてみないことには、全エントリのuid属性に対するマッチング作業が行えないのです。
ここで有効になるのがインデックスです。検索フィルタで指定された属性に検索タイプに合ったインデックスを付与することで、OpenLDAPサーバはid2entry.bdbファイルから検索スコープ中のすべてのエントリを取得せずとも、ピンポイントで必要なエントリを取得できるようになります。
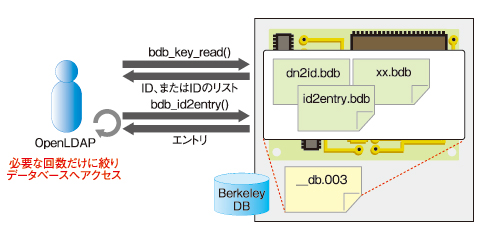 図4 インデックスの有効性
図4 インデックスの有効性Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。