Rによるオープン・データの可視化(2):実践! Rで学ぶ統計解析の基礎(4)(2/3 ページ)
世界銀行のData Catalog
先月の報道によると、中国が日本のGDPを抜いて世界第2位の経済大国になったそうです。Bloombergの報道によれば、ドル換算の名目値で2010年の第2四半期までの速報値で、日本が1.288兆ドルに対して、中国が1.338兆ドルだそうです。
これは何年も前から予想されたことですから、あまり驚くべきことでもありませんが、オープン・データを利用して確かめてみることにしましょう。ただし、生憎のこと、信頼できるGDPのデータは2008年までのものしかないので、2008年までの傾向をみるだけになることをお断りしておきます。
GDPのデータとして各国のデータが網羅的にまとまっていて、信頼できるものは、世界銀行にあるものか、OECDにあるものか、IMFにあるものかだと思います。
- The World Bank Data Catalog
- Gross Domestic Product (GDP) for OECD member countries
- IMF World Economic Outlook Database
いずれのサイトについてもデータをWebインターフェイスから「ドリルダウン」する形にてデータを入手することができます。GDPデータについては、いずれのサイトも2008年までのデータがストアされています。この中で一番簡単に取り扱えて、一番モダンな問い合わせ実装が行われているのが世界銀行のものです。そこで、今回は世界銀行にあるGDPデータを利用します。
世界銀行の“Data Catalog”は、WDI("the World Development Indicators")というインジケーターをクエリに含めることで、検索を行うデータベースです。WDIはいわばRDBの「テーブル」や「ビュー」に当たります。このWDIには2000を超えるインジケーターが存在します(http://data.worldbank.org/indicator)。そして、世界銀行の“Data Catalog”はモダンなWebサービスであるRESTインターフェイスとしても実装されていることが、データ利用の敷居を極端に下げていると言ってよいでしょう。つまり、HTTPプロトコルを利用でき、RESTを解釈できるシステムなら、誰もが簡単にこのData Catalogを利用できるのです。
Rでこの世界銀行のData CatalogをREST経由で利用するには、WDIパッケージを利用します。
WDI: Search and download data from the World Bank's World Development Indicators http://cran.r-project.org/web/packages/WDI/index.html
WDIパッケージはCRANの標準パッケージですので、次のコマンドで簡単にインストールすることができます。
install.packages("WDI")
さて、実際にこのWDIを用いて、世界銀行の“Data Catalog”にアクセスし、GDPの米ドルでの名目値、1人当たりのGDPの米ドルでの値、そしてGDPの成長率について、米国、日本、中国、韓国に関する時系列データの比較をしてみたいと思います。以下のコードがそれを実行したものです。
> library(WDI)
> library(ggplot2)
> gdp <- WDI(country = c("US", "JP", "CN", "KR"), indicator = "NY.GDP.MKTP.CD", start = 1960, end = 2008)
> gdppercapita <- WDI(country=c("US", "JP", "CN", "KR"), indicator = "NY.GDP.PCAP.CD", start = 1960, end = 2008)
> gdpgrowth <- WDI(country=c("US", "JP", "CN", "KR"), indicator ="NY.GDP.MKTP.KD.ZG", start = 1960, end = 2008)
> ggplot(gdp, aes(year, NY.GDP.MKTP.CD, color=country))+geom_line(stat="identity") + xlab("Year") + opts(title="GDP (current US$)") + ylab("")
> ggsave(file = 'gdp.png', scale = 0.8)
> ggplot(gdppercapita, aes(year, NY.GDP.PCAP.CD, color=country))+geom_line(stat="identity") + xlab("Year") + opts(title = "GDP per capita (current US$)") + ylab("")
> ggsave(file = 'gdppercapita.png', scale = 0.8)
> ggplot(gdpgrowth, aes(year, NY.GDP.MKTP.KD.ZG, color=country)) + geom_line(stat="identity") + xlab("Year") + opts(title="GDP growth (annual %)")+ylab("")
> ggsave(file = 'gdpgrowth.png', scale = 0.8)
最初に、WDIとグラフ描画用のggplot2を読み込みます。次に、RESTインターフェイス経由で世界銀行のData Bankにアクセスするために、WDIパッケージを利用します。WDIパッケージの使い方は非常に簡単です。単にWDI関数を利用し、その引数としてcountry、 indicator、そしてstartおよびendを指定するだけです。countryにはデータを入手したい国名をリストで指定し、 indicatorにはWDIのインジケータを指定し、startおよびendに検索対象の開始年と終了年を指定します。ここで、 indicatorに指定するインジケータを探すには、Data Bankのインジケーター検索画面(http://data.worldbank.org/indicator/)を利用して一度検索を行ってから、その表示されるURLの最後の部分に見ればよいでしょう。

今回のGDPの米ドルでの名目値、1人当たりのGDPの米ドルでの値、そしてGDPの成長率に当たるインジケーターは、NY.GDP.MKTP.CD、NY.GDP.PCAP.CD、NY.GDP.MKTP.KD.ZGになります。WDIによって入手できたデータは、例えば名目GDPなら以下のようなレイアウトになっています。
> head(gdp)
country NY.GDP.MKTP.CD year iso2c
1 United States 1.40933e+13 2008 US
2 United States 1.37416e+13 2007 US
3 United States 1.31165e+13 2006 US
4 United States 1.23641e+13 2005 US
5 United States 1.16309e+13 2004 US
6 United States 1.09080e+13 2003 US
countryのカラムは国を表し、NY.GDP.MKTP.CDはドル換算にした名目GDP値を表し、yearが年を表しています。これらを見ると分かるように、これ以上まったくデータの加工をすることなしに、そのままRで利用できます。これがRESTインターフェイスから直接読み込むことの最大のメリットです。
これらのWDIからのデータをggplotで描画して、グラフを保存しているのが、最後の部分のコードです。線グラフを書きたいので、 geom_lineを利用しました。ここで1点注意するのは、ggplot関数の引数で入力されている、aesの引数です。ここではx軸にyearを指定し、y軸にNY.GDP.MKTP.CDなどのインジケーターから取得きる値を指定してプロットするという指示を書いていますが、それと同時に、color引数にcountryカラムを指定しています。これは、countryで指定される国ごとに違う色のプロットをしろという指定です。ここで、名目値でみたドル換算でのGDPのグラフを見てみましょう。

これを見ると分かりますように、color = country で指定したように、国別に違う色の系列の線グラフとなり、右にレジェンドが自動的に描かれています。このグラフ描画の高度な自動化と簡便さが、まさにggplot2を使う最大のメリットの1つといっていいでしょう。
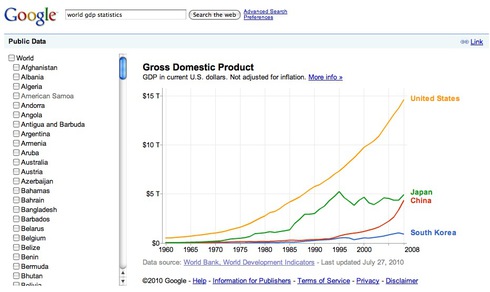
さてグラフの方ですが、1960年から2008年まで一貫して米国が高い名目GDP値を取っていることが分かります。日本は1995年まではでこぼこながらも強く成長している様が分かります。しかし、1995年から失速して、その後の状態は読者の皆様のご承知の通りです。一方で、中国は1994年以来、力強い成長をしていて、2008年にはもう一息で日本の名目GDP水準を抜かす状態にあった、ということが見て取れると思います。そして、先ほどの報道にあるように2010の第2四半期で、日本を名目水準値としては追い抜いたということです。
それでは次に、1人当たりのGDP値をみてみましょう。

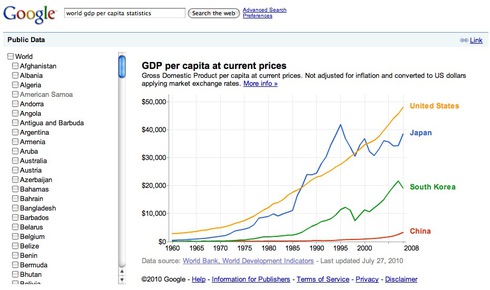
1980年代後半に1人当たりのGDP値は、日本が米国を抜いていることが分かります。これが「日本の奇跡」だとか「ジャパン・アズ・ナンバーワン」と言われた現象です(ただし、社会学者エズラ・ヴォーゲルの『ジャパン・アズ・ナンバーワン』の出版は1979年)。しかし、2000年に入って失速してしまい、米国に抜かされていることも分かります。一方で、中国をみますと、1人当たりのGDPに引き直すと韓国よりもまだまだ低い水準に留まっているということが分かります。これは次のコードで入手した各国の人口を見てみれば当然です。
> library(ggplot2)
> library(WDI)
> pop <- WDI(country = c("US", "JP", "CN", "KR"), indicator = "SP.POP.TOTL", start = 1960, end = 2008)
> ggplot(pop, aes(year, SP.POP.TOTL, color=country)) + geom_line(stat="identity") + xlab("Year") + opts(title="Population") + ylab("")
> ggsave(file = 'population.png', scale = 0.8)

中国は13億人という膨大な人数の人間をかかえているのです。日本と同じだけの1人当たりのGDPを目指そうと思ったら、今の10倍の水準が必要です。
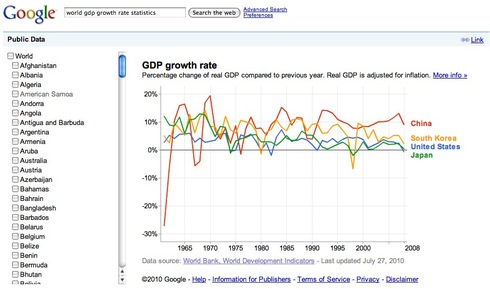
最後は、参考までに、GDPの成長率についてのグラフを提示します。

以上のように、RESTインターフェイスを実装されているオープン・データは簡単にデータを入手でき、データを加工する手間も必要なく、Rでスムーズに利用できることが分かったと思います。
と、ここまで議論してきて、1点申し上げたいことがあります。ここであげた世界銀行のデータを表示するくらいならば、実はRでプロットするまでもなく、グーグルのpublicdata APIを用いて、すぐに表示することができるということです。publicdata APIも世界銀行のWebサービスインターフェイスを利用していますので、基本的には同じことをやっていることになります。
(例1)
(例2)
(例3)
しかし、Rでデータの図示・可視化を行うメリットは2つあります。1つは、もちろんWebサービスAPIを公開していないデータソースを利用できることです。そしてそれ以上に、データ解析、統計解析ができるという点があります。その例を次に示したいと思います。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。