基幹系システムでCloud SQLは使えるか試してみた:Google Cloud SQLは基幹系で使えるのか(後編)(4/4 ページ)
コラム 部品・在庫関係のテーブル構成
CREATE TABLE `item_master` ( `p_item` varchar(8) default NULL, `c_item` varchar(8) default NULL, `final` char(2) default NULL, `make` char(2) default NULL, `stock` int(11) default NULL, `vendor` varchar(20) default NULL );
リスト5は、ここで使用したDBテーブルのスキーマです。このスキーマはサンプル用に簡略化されたもので、実際に生産管理システムで使用されるものとは、かなり違っています。実際の生産管理システムで使用されるテーブル類がどのような構成になるのか、一般的な例で紹介します。
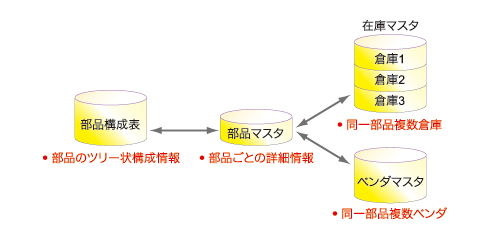 図7 生産管理システムで使用される一般的な部品・在庫関係テーブル
図7 生産管理システムで使用される一般的な部品・在庫関係テーブル 図7は、この例に関係するようなテーブル類の関連図です。ここでの例のように部品構成が参照されてからの処理は次のようになります。
部品構成表には通常部品番号で親子関係のみが登録されており、それ以外の部品の詳細情報は含まれないのが普通です、従って、ある親部品からの子部品構成をツリー状に展開して表示する場合、親子関係の部品番号は表示できますが、それ以外の情報は表示できません。
ここで、おのおのの部品に関する情報を表示する場合は、一般には部品マスタ(アイテムマスタ)からの情報を表示します。在庫情報やその部品の購入先であるベンダマスタの情報などには、さらに別テーブルが使用されます(ただし、主倉庫や代表ベンダを部品マスタに含む場合はあります)。
例えば、在庫に関しては同一部品が複数の倉庫(製造現場の払い出し在庫や、主倉庫など)に在庫されている場合も多く、それぞれどの場所の倉庫に何個あるのかを在庫場所単位で把握します。部品の購入ベンダに関しても、1つの購入部品に対して一般に複数登録されます。これは、その時々での部品調達条件が異なる場合があるからです。
つまり、納期は早いが購入単価の高いベンダ、逆に、納期は遅いが購入単価の安いベンダ、そのほか、品質やまとめ買いでの値引き率などのベンダ特性と、そのときの部品調達条件例えば高くとも緊急に調達しなければならないなどの状況を加味してベンダの選定を行う場合も多くなります。
このように、サーバ側でのDBテーブル構成やデータのアクセス方法などは、ここでのサンプルとかなり違ったものです。処理の違いは、すべてサーバ側でのものです。つまり、クライアント側ではサーバ側処理をブラックボックスと考え部品番号を非同期でサーバに送った後は、サーバ側処理の結果を受け取って動的に表示するだけなので、Ajaxクライアント側での処理内容は、上記のような実際的なテーブル構成の場合でも、ほとんど変わりません。
参照処理時間の測定結果
今回のサンプルでは、Cloud SQLのパフォーマンステストを行っています。テスト内容は、図3の画面で「A0002」をクリックしてから図4の画面表示が完了するまでの時間を測定するものです。この間に、28個の子部品情報(部品番号と在庫数量)表示を行っています。
| 1 | 2 | 3 | 平均 | |
|---|---|---|---|---|
| Cloud SQL 参照(クラウド) | 7939 | 7558 | 7352 | 7616.3 |
| Cloud SQL 参照(ローカルCI) | 19161 | 15011 | 14186 | 16119.3 |
| Cloud SQL 参照(ローカルMI) | 484 | 455 | 397 | 445.3 |
| 表 参照処理時間の測定結果(単位ミリ秒) ※CIはCloud SQL Instance、MIはMySQL Instance(Connector/J使用) | ||||
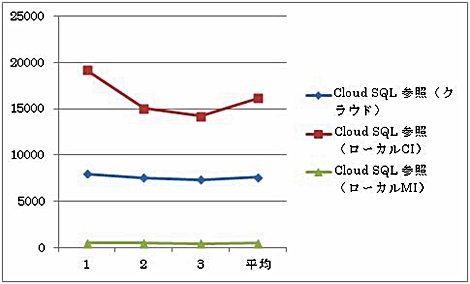 図7 再帰呼び出し参照の表示スピード
図7 再帰呼び出し参照の表示スピード測定は表のようにクラウドとローカル(Eclipse)環境での表示時間を測定しています。ローカル環境では、Cloud SQLインスタンス(CI)を使用した場合とMySQLインスタンスを使用した場合(MI)の2種類で測定を行っています。
ローカル環境でCloud SQLインスタンスを使用した場合は、GAEクラウド上のMySQLをアクセスしています。従って、ネットワークレイテンシが大きくなり最も遅い測定結果となっています。これは実際の運用では存在しないパターンなので除外して考えても良いでしょう。
実際の運用と類似しているパターンは、ローカルMI(MySQLインスタンス)とクラウドのパターンです。この2つの比較でも、ローカルMIの方が相当良いパフォーマンスであることが示されています。
前にも触れたように、業務系・基幹系でCloud SQLを使用する場合は、すでに運用されているオンプレミスからの移行パターンが多いと想像されます。この場合、ローカルMIでの参照パターンが最も、このケースに近いと考えられます。
ただし、クラウド上でのMySQLアクセスでは、クラウド分散システム上のアクセスであることからネットワークレイテンシがパフォーマンスに影響していると考えられます。
またMySQLを使用したローカルアクセス(ローカルMI)では、今回の測定では同じPC上のMySQLをEclipseからアクセスする形になっていますが、実際のオンプレミス環境では、もう少しネットワークレイテンシによるオーバーヘッドは大きくなると推定されます。
Cloud SQL、パフォーマンスは今後に期待
Cloud SQLについて、2回に分けて特に業務システム利用の視点から見てきましたが、いかがでしたでしょうか。
PaaS型クラウドのGAEでは、アプリケーション作成のためのインフラはすべて用意されており、NoSQLのBigtableと併用して使えることや、GAEの各種サービス機能と組み合わせて使用できるというのも魅力です。
ただ、今回行ったパフォーマンステストに関しては、Cloud SQLは予想したよりもパフォーマンスが思わしくなかったというのが正直な感想です。MySQLインスタンスを使用したローカル環境でのパフォーマンスはクラウド環境でのCloud SQLよりもはるかに良い結果を出しています。これは、オンプレミスでのMySQL使用とGAEクラウドでのMySQL使用の対比と見ることもできます。
測定結果はネットワークレイテンシによってパフォーマンスの差が拡大傾向にあったのは確かでしょうが、それを考慮しても差は大きかったように思えます。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。