標準ライブラリで提供される時間・エラー処理に関する便利な機能:目指せ! Cプログラマ(15)
前回に引き続き標準ライブラリについて理解を深めましょう。今回は標準ライブラリで提供される便利な機能のうち、時間に関係するもの、エラー処理に関係するものを中心に解説をします。見出しのカッコ内に関係するヘッダーファイルを示してあります。
時刻(time.h)
今回はまず、時刻について説明します。
時刻を表現する型(time_t、struct tm)
時刻を表現するための型として、time_t、struct tmと、後ほど説明するclock_tの3つが用意されています。
time_tは暦時刻の内部表現で、現在時刻の取得や演算を行います。struct tmは、年月日や時分秒といった要素ごとにメンバーを持っていて、それらを単独で扱うときや、文字列などにして出力する場合に使います。
struct tmが持っているメンバーは次のようになります。
- int tm_sec; // 秒(0から60、うるう秒を考慮)
- int tm_min; // 分(0から59)
- int tm_hour; // 時(0から23)
- int tm_mday; // 日(1から31)
- int tm_mon; // 1月からの月数(0から11)
- int tm_year; // 1900年からの年数
- int tm_wday; // 日曜日からの日数(0から6)
- int tm_yday; // 1月1日からの日数(0から365)
- int tm_isdst; // 夏時間(夏時間の場合は正、そうでなければ0、不明の場合は負の値)
夏時間は、1年間のうちのある期間だけ時刻を進める制度です。日本やアジア諸国ではあまり馴染みのない制度ですが、欧米ではよく採用されています。
暦時刻の取得と変換(time、gmtime、localtime、mktime、difftime)
現在の時刻はtime関数で取得できます。
time_t time ( time_t * timer );
この関数は時刻を戻り値で受け取ることも、引数で受け取ることもできるようになっています。戻り値だけで受け取るときは引数にNULLを渡します。
time_tをstruct tmへ変換するには2つの方法があります。
// 世界協定時(UTC)で取得 struct tm * gmtime ( const time_t * timer ); // 地方標準時で取得 struct tm * localtime ( const time_t * timer );
localtimeがどの地方標準時を返すのかは実行環境のタイムゾーンの設定によります。タイムゾーンが日本になっていれば、日本の地方標準時(日本標準時;JST)は世界協定時と比べて9時間進んでいますので、gmtimeとlocaltimeの結果を比べると9時間進んだ結果が得られるはずです。なお、いずれの関数もエラーの場合はNULLを返します。
struct tmをtime_tへ変換するにはmktime関数を使います。
time_t mktime ( struct tm * timeptr );
また、time_t型のオブジェクト同士で差を求める関数も用意されています。
double difftime ( time_t time1,
time_t time0 );
結果は秒単位となります。
なお、gmtimeとlocaltimeには、C11からセキュリティ強化版が用意されていますので、こちらも検討してみて下さい。ただし、Visual C++では引数の順番が異なりますので注意が必要です。
struct tm * gmtime_s ( const time_t * restrict timer,
struct tm * restrict result );
struct tm * localtime_s ( const time_t * restrict timer,
struct tm * restrict result );
時刻を文字列に変換する(strftime)
プログラムで時刻を表現するにはtime_tとstruct tmがありますが、time_tは内部表現となるのでターゲットによって表現が違っている可能性があります。互換性・移植性の高いプログラムを作成することを考えると、通常はstruct tmを使います。変換の関数は3つあります。
char * asctime ( const struct tm * timeptr );
char * ctime ( const time_t * timer );
size_t strftime ( char * restrict s,
size_t maxsize,
const char * restrict format,
const struct tm * restrict timeptr );
asctime関数は引数が1つしかなく、結果が文字列で返りますのでお手軽ですが、書式は固定で変更できません。ctimeはtime_t型のオブジェクトを引数に取り、内部ではlocaltimeでstruct tmに変換したあと、asctimeを呼び出しています。
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
int main ( void ) {
time_t now_t = time(NULL);
// 同じ形式で時刻を2回表示する。
// asctime がセキュリティーチェックでエラーになる場合は
// 代わりに asctime_s を使う。(後述)
printf("%s", asctime(localtime(&now_t)));
printf("%s", ctime(&now_t));
return EXIT_SUCCESS;
}
出力文字列の書式を指定するには、strftimeの3つ目の引数に書式文字列を渡します。1つ目の引数は結果を受け取る配列、2つ目の引数はその配列のサイズを指定します。配列に収まらない場合には戻り値が0になり、配列には結果が入りません。配列に収まる場合は、その文字数が返ります。結果は文字列となるので'\0'で終端されます。'\0'も含めて配列に収まるか収まらないかの判定がされる点に注意してください。
書式文字列に変換指示子を含めると、指定の内容に置き換わります。変換指示子の種類は多くすべては載せられませんので、代表的なものを次に挙げます。一部の変換指示子はC99からの機能ですので、開発環境の仕様を確認して下さい。
- 年
- %Y、%y : 西暦年、西暦年の下2桁
- 月
- %m : 月
- %b : 簡略化された月の名前
- %B : 簡略化されていない月の名前
- 週
- %U : 年の週の数(00から53)、最初の日曜日を第1週の最初の日とした場合
- %W : 年の週の数(00から53)、最初の月曜日を第1週の最初の日とした場合
- 日
- %d、%e : 日(桁揃えなし、あり)
- %j : 年の日(1から366)
- 曜日
- %a : 簡略化された曜日の名前
- %A : 簡略化されていない曜日の名前
- 時
- %H、%I、%r : 時間(24時間制、12時間制、ロケールの12時間制表現)
- %p : 午前または午後
- 分、秒
- %M : 分(00から59)
- %S : 秒(00から60)
- その他
- %z、%Z : UTCからの時差、時間帯の名前
- %x、%X : ロケールの適切な日付表現、時刻表現
- %c : ロケールの適切な日付及び時刻表現
- %r : ロケールの12時間制での時刻表現
- %F : "%Y-%m-%d"
- %D : "%m/%d/%y"
- %R、%T : "%H:%M"、"%H:%M:%S"
- %n、%t、%% : 改行、水平タブ、'%'
例えば次のように使います。
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
int main ( void ) {
// 現在時刻を取得する。
// localtime がセキュリティーチェックでエラーになる場合は
// 代わりに localtime_s を使う。(前述)
time_t now_t = time(NULL);
struct tm * now = localtime(&now_t);
char buf[256];
// 日付、時刻、タイムゾーンを表示
// 結果例)now is 03/03/13 12:00:00 東京(標準時)
size_t result = strftime(buf, sizeof(buf),
"%x %X %z",
now);
if (result != 0) {
printf("now is %s\n", buf);
}
return EXIT_SUCCESS;
}
このサンプルプログラムをPleiadesで実行すると、コンソールウィンドウで日本語部分が文字化けする場合があります。MinGWが提供するstrftimeはMS932(シフトJIS)でエンコードされた文字列を返しますが、Pleiadesのデフォルトの設定がUTF-8になっているからです。これを直すには、Pleiadesのメニューから「実行」-「実行構成」を選び、表示されたダイアログボックスの左側にある実行構成のリストから、実行に使う構成を選びます。次に、右側のタブから「共通」を選び、エンコードの設定を「デフォルト - 継承 (UTF-8)」から「MS932」に変更します。
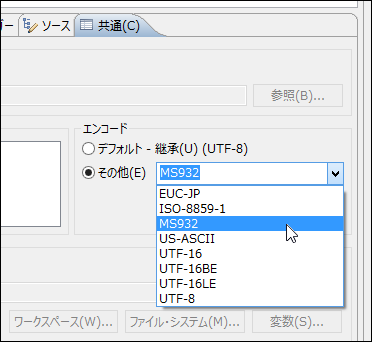 エンコードの設定
エンコードの設定なお、asctimeとctimeには、C11からセキュリティ強化版が用意されています。Visual C++でもほぼ同じ形で使えますので、こちらも検討してみて下さい。
errno_t asctime_s ( char * s,
rsize_t maxsize,
const struct tm * timeptr );
errno_t ctime_s ( char * s,
rsize_t maxsize,
const time_t * timer );
時間を計測する(clock_t、clock、difftime)
プログラム内である処理にかかる時間を測定するにはclock関数を使います。
clock_t clock ( void );
clock関数はclock_t型のオブジェクトを返します。これはプロセッサ時間という内部時間を表していて、CLOCKS_PER_SECで割ることで秒単位の値が得られます。このclock関数を2回呼び出し、その差をCLOCKS_PER_SECで割って経過した秒を求めると、その間の処理にかかった時間が分かります。
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
#include <limits.h>
int main ( int argc, char *argv[] ) {
if (argc < 1) {
printf("Argument error.\n");
return EXIT_FAILURE;
}
// 開始時刻
clock_t c1 = clock();
// 時間のかかる処理
for (int i = 0; i < 1000000; i++) {
printf("");
}
// 終了時刻
clock_t c2 = clock();
double s = ((double) c2 - c1) / CLOCKS_PER_SEC;
printf("%f sec.\n", s);
return EXIT_SUCCESS;
}
結果が0 sec.になってしまう場合は、PCの速度が速いために測定精度以下の時間で処理が終わってしまっている可能性があります。ループの回数を増やすなどしてみて下さい。処理時間や測定の精度は環境ごとに異なります。
ジャンプ(setjmp.h)
setjmp.hで提供されるジャンプ機能では、setjmpを呼び出した場所へlongjmpにより実行を移すことができます。このジャンプは、gotoのように関数の中だけではなく、別の関数へ移動することもできます。
int setjmp ( jmp_buf env ); void longjmp ( jmp_buf env , int val );
setjmpを呼び出すと、実行している環境からジャンプに必要な情報をenvへ保存します。longjmpを呼び出すとsetjmpを呼び出した場所へ実行が移動し、あたかもsetjmpの呼び出しから戻ってきたかのようにジャンプすることができます。
setjmpは情報を保存する処理を実行したときと、longjmpの呼び出しによりジャンプしてきたときで戻り値が変わります。前者は0、後者はlongjmpの仮引数valの値になります。ただしvalに0を渡すとsetjmpの戻り値は1になります。longjmpの呼び出しによりジャンプしてきたことを判別できるようにするために、このように決まっています。
#include <setjmp.h>
#include <stdlib.h>
#include <stdio.h>
jmp_buf env;
void func ( void ) {
printf("func\n"); // 2
longjmp(env, 1);
}
int main ( void ) {
if (setjmp(env) == 0) {
printf("setjmp\n"); // 1
func();
} else {
printf("returned\n"); // 3
}
return EXIT_SUCCESS;
}
printfの呼び出しは1→2→3の順で行われ、結果は、
setjmp func returned
になります。
setjmpの呼び出しでは、戻り値が0かどうか確認します。0ならばlongjmpの呼び出しでないことが分かります。ここで戻り値をif文の中で確認していますが、setjmpの呼び出しは非常に特殊で、基本的にこの例ような方法でないといけないというルールがあります。厳密には次のようなケースだけが許されます。
- if、switch、while、do while、forの制御式(条件式)にsetjmpだけがある。
- if、switch、while、do while、forの制御式(条件式)でsetjmpの値と整数定数とを、関係演算子(>や>=など)または等価演算子(==)で比較している。
- setjmpが文全体である。つまりsetjmp(env);が単独で現れる。
このほか、longjmpの呼び出しでオブジェクトの解放がされない場合があることや、実行環境によって動作が変わるものがあるため、回復の見込めないエラーの処理のみに使うなど、用途を限定して使うのが良いでしょう。
エラー処理(errno.h、fenv.h)
errno.h
いくつかのライブラリ関数は、エラーが発生した時に、エラーの詳細を示す値をerrnoへ設定します。Cで規定されているエラーの種類は次の3つです。
- EDOM : 定義域(ドメイン)エラー
- ERANGE : 範囲エラー
- EILSEQ : エンコーディングエラー (illegal byte sequence)
EDOMは数学関数に定義されていない演算をさせた時に発生します。例えば自然対数を計算するlog関数に負の値を渡したり、平方根を求めるsqrt関数に負の値を渡すと発生します。また、結果が戻り値の型で表現できない場合、例えばlog関数に0.0を渡した場合などにはERANGEになります。ERANGEは文字列と数値を変換する関数でも発生します。また、EILSQはマルチバイト文字やワイド文字を扱う関数で、渡した文字列の符号化(エンコーディング)が正しくないことを表します。
この3つ以外に、環境ごとにエラーが用意されていることがありますので確認してみて下さい。
errnoはint型のオブジェクトとして参照できます。プログラム開始時には0になっており、ライブラリがエラーを検出するとerrnoにエラーを設定します。自動的に0にクリアされることはありませんので、必要であればプログラムで設定します。
また、stdio.hで提供されているperror関数や、string.hで提供されているstderror関数を使うと、errnoが示すエラーを適切なメッセージに変換できます。perrorはerrnoの値を見て「<仮引数sが指す文字列>: <errnoに相当する文字列>」という形式で標準出力にメッセージを出力します。strerrorは、指定したエラー番号に相当する文字列へのポインターを返します。
#include <stdio.h> void perror ( const char * s ); #include <string.h> char * strerror ( int errornum );
次の例で使い方を確認して下さい。
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
int main ( void ) {
printf("errno=%d\n", errno);
log(0.0); // ERANGE
printf("errno=%d\n%s\n", errno, strerror(errno));
perror("MESSAGE");
return EXIT_SUCCESS;
}
エラーの番号やstrerrorで得られるメッセージは環境によって異なります。Visual C++ 2008では次のように表示されました。
errno=0 errno=34 Result too large MESSAGE: Result too large
strerrorには、C11からセキュリティ強化版が用意されています。Visual C++でもほぼ同じ形で使えますので、こちらも検討してみて下さい。
errno_t strerror_s ( char *s,
rsize_t maxsize,
errno_t errnum );
fenv.h
math.hで提供される数学関数を呼び出すにあたって、呼び出し中にEDOMやERANGEが発生しないようにするためには、引数の値をチェックする必要があります。EDOMではそれも可能ですが、ERANGEの場合にはエラーが発生しない条件を求めるのが難しい関数もあります。したがってすべてのケースでエラーが発生しないようにすることを考えるよりも、場合によってはエラーが発生した時に正しく対処できるようにしましょう。
しかし環境によっては、エラーが発生した時にerrnoを設定するのではなく、例外を発生させる場合があります。つまり移植性を考えた場合、errnoだけで数学関数のエラーに対処することはできません。そこで、fenv.hで提供されている浮動小数点環境を設定・取得する機能を利用します。
int feclearexcept ( int excepts ); int fetestexcept ( int excepts );
数学関数の呼び出しで例外が発生すると、内部の例外フラグが変化します。そこで、数学関数の呼び出し前にフラグをクリア(feclearexcept)し、呼び出したあとにフラグをチェック(fetestexcept)します。この際、あわせてerrnoもチェックします。
// errno と例外フラグをクリアする
errno = 0;
feclearexcept(FE_ALL_EXCEPT);
// 数学関数の呼び出し...
// エラーチェック
int raised = fetestexcept(<例外>);
if (errno != 0 || raised != 0) {
// エラー
printf("errno=%d, raised=%d\n", errno, raised);
} else {
// 成功
printf("Success.");
}
サンプルプログラム中の<例外>に入る例外の種類は次のとおりです。
- FE_DIVBYZERO : ゼロ除算
- FE_INEXACT : 丸め誤差により結果が不正確
- FE_INVALID : 演算結果が未定義
- FE_OVERFLOW : オーバーフロー
- FE_UNDERFLOW : アンダーフロー
- FE_ALL_EXCEPT : 処理系で定義されているすべての例外
この他に、処理系ごとの例外が定義されている場合もあります。例外の中からチェックしたい例外の論理和(例えばFE_DIVBYZERO | FE_INVALID)を指定します。
この他、例外を操作するための関数(feraiseexceptなど)、演算結果の丸め方法を取得・変更する関数(fegetround、fesetround)、浮動小数点環境を取得・変更する関数(fegetenvなど)があります。
デバッグ(assert.h)
assert.hでは、プログラム中で条件の診断を行うことができるassertマクロが提供されています。
これを使うと、プログラムが正しく動作しない際に、正しく関数を呼び出しているが結果が正しく出ていないのか、間違った関数呼び出しをしているために結果が正しく出ていないのか、簡単に判別ができるようになります。前者であれば関数のバグですし、後者であれば呼び出す方のバグだということがわかります。この結果、デバッグをする際に効率よく作業ができます。
例えば、テストの成績を管理するプログラムで、新たなテスト結果を登録する関数があったとします。それは次のようなものであったとしましょう。
void add_test_result ( int score ) {
// テスト結果の追加処理
}
テスト結果が0点から100点であったとすれば、この関数を呼び出すときに負や101以上の点数が渡された場合はプログラムのバグである可能性があります。関数が呼ばれた時にassertでチェックします。
void add_test_result ( int score ) {
assert(0 <= score && score <= 100);
// テスト結果の追加処理
}
試しに、この関数を呼び出してみましょう。なお、assertマクロは、NDEBUGというマクロを確認し、定義されていればチェックを行いません。したがって、assertを確実に有効にしたい場合は#include <assert.h>より前に、NDEBUGマクロを未定義に設定します(マクロの詳しい使い方については今後の記事で解説します)。
// NDEBUG マクロを未定義にする場合は下記のコメントを解除
// #undef NDEBUG
// NDEBUG マクロを定義する場合は下記のコメントを解除
// #define NDEBUG
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
void add_test_result ( int score ) {
assert(0 <= score && score <= 100);
printf("add_test_result(%d)\n", score);
}
int main ( void ) {
add_test_result(50); // OK
add_test_result(-1); // NG
return EXIT_SUCCESS;
}
結果は環境によって異なりますが、おおよそ次のような出力になるはずです。出力されない場合は、NDEBUGマクロを未定義にするために「#undef NDEBUG」の行をコメント解除して実行してください。
add_test_result(50) Assertion failed: 0 <= score && score <= 100, file <ファイル名>, line 11
Visual C++では同時に、ほぼ同じ内容のメッセージを含むダイアログボックスが表示されます。
NDEBUGマクロの定義は、開発環境のビルド構成によって変更できます。
Pleiadesではデフォルトの設定でプロジェクトを作っただけでは、NDEBUGマクロが定義されません。自分でリリース版の設定をします。プロジェクトをマウスで右クリックしてメニューを表示し「プロパティ」を指定します。「C/C++ビルド」-「設定」で表示される画面で、構成を「Release」として、「ツール設定」-「GCC C Compiler」-「シンボル」を選択します。「定義済みシンボル」へ「NDEBUG」を追加します。「適用」をクリックしてから「OK」をクリックすると設定できます。
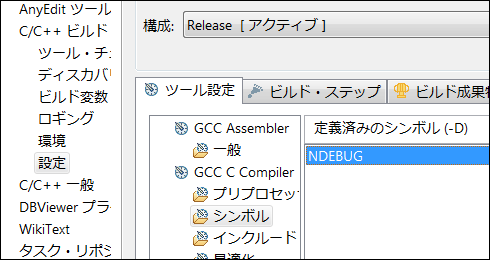 NDEBUGの設定
NDEBUGの設定Pleiadesのメニューから「プロジェクト」-「すべてビルド」を選ぶとリリース版もビルドされて実行できるようになります。Pleiadesのメニューから「実行」-「実行」とすると、デバッグ版とリリース版のどちらを実行するか選択をする画面が表示されるので、リリース版を実行するには修飾子が「Release」の方を、デバッグ版を実行するには修飾子が「Debug」の方を選択して「OK」をクリックします。リリース版を実行すると、次のような出力になり、assertが無効になっていることがわかります。
add_test_result(50) add_test_result(-1)
Visual C++ではデフォルトの設定でソリューションを作ると、ソリューション構成をDebugにしたときにはNDEBUGマクロが定義されず、Releaseにすると定義されるという設定になります。この場合は自分で#undef NDEBUGや#define NDEBUGする必要はありません。
このように、プログラムの開発中はNDEBUGを定義しないでおき、試験環境ではassertによってプログラムミスを検出するようにします。そしてプログラムをリリースするときにNDEBUGを定義すると、余計な処理が行われなくなります。
なお、NDEBUGが定義されているとき、すなわちassertマクロが何もしないときは、assertマクロのカッコ内の式はまったく(本当にまったく)評価されませんので注意して下さい。assert内で副作用のある処理、例えばファイルをオープンしようとしたり、変数の値を変更したりしていると、NDEBUGが定義されたときのその処理がまったく行われず、悩むことになります。
// ファイルを読み込むプログラム
FILE *f;
// NDEBUG が定義されているときにファイルがオープンされない!
assert(f = fopen("config.txt", "r"));
ここで、なぜif文を使った通常の引数チェックをせずにassertマクロを使うのか考えてみましょう。
例で示したような「関数が前提とする引数が渡されているかのチェック」は、呼び出すプログラムでするよりも関数でした方が良いと思うかもしれません。しかし、この関数が呼び出される回数が多く、いろいろなところから呼び出されるようなものだった場合に、余計な引数のチェックは性能の問題がでてくることがあります。
性能問題を解決するために「関数を呼び出すときには必ず正しい引数を指定する」という前提で関数を用意するというのは1つの方法なので、そうすることがあります。このとき、「関数を呼び出すときには必ず正しい引数を指定する」というのが意外と難しいものです。ですから、関数と関数を呼び出すプログラムのどちらも完成していないプログラムの開発中において、プログラムが正しく動作しない場合はどちらのバグなのかがすぐにはわかりません。
どちらにバグがあるかを簡単に判別するために、やはり関数で引数チェックをしたくなります。最初に戻ってしまったように見えますが、ちょっと違います。ここでやりたいことは「開発中は関数で引数のチェックができて、リリース時は関数の引数チェックはなかったことにする」ということなのです。
この特別な要求に応える機能がassertマクロになります。これを使うと、プログラムの変更をせずにNDEBUGというマクロの定義の有無だけで、開発版とリリース版での動作を変更できます。
以上のことから、assertマクロはプログラムの実行時に発生するエラーを処理するためには使えないことがわかります。あくまでもプログラムの開発時に利用するものです。
今回学んだこと
- time.hで提供されている機能を使って、時刻の取得や、時刻の文字列への変換、時間計測ができます。
- errno.hで提供されている機能を使って、エラーの詳細を取得したり、メッセージを取得したりできます。
- 数学関数のエラーは、fenv.hで提供されている例外処理と組み合わせて対応します。
- assert.hで提供されているassertマクロを使うとデバッグが効率的に行えます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。