Webブラウザーだけで学ぶ機械学習の「お作法」:Webブラウザーでできる機械学習Azure ML入門(2)(2/4 ページ)
お作法2:データの整形
続いて「お作法2:データの整形」を見ていきます。
元のデータがあらかじめ機械学習を目的に作られたデータであれば良いですが、大抵の場合は、何らかの別の目的で作られたログデータや、POSから送られてくるデータなどでしょう。これらは、特定の目的で実施する機械学習のために作られたデータではないはずです。ですから、機械学習に適した形にするために、データを整形していきます。この作業のことをデータクレンジング(データクリーニング)などと言ったりもします。
この作業は外部のツール(例えばExcelなど)で行うこともできますが、Azure MLではAzureのクラウドストレージに保存されたデータをそのまま使うこともできるようになっています。シンプルな機械学習の部分だけを提供するのではなく、データクレンジング機能にも踏み込んでサービスを提供しているのは、こうしたデータの利用方法を念頭に置いているからでしょう。
それでは、今回のサンプルフローに戻りましょう。上から二段目を見ていきます。

「Restaurant ratings」は「Split」という機能につながっています。「Restaurant customer data」と「Restaurant feature data」はそれぞれ「Project Columns」という機能に接続されています。「Split」と「Project Columns」は、ML Studio左ペインの「Data Transformation」という大カテゴリに含まれている、データ加工をするための機能です。この二つのうちのまずはSplitから見ていきます。
左の箱:Split
ML Studioのサンプルを見ると分かるように、「Restaurant ratings」のデータを Splitという機能に渡しています。Splitにデータを渡すことで、データを二つに分割します。Splitにはいくつかのモードがあり、このサンプルの場合は「Recommender Split」というモードを使ってデータを分割しています。
このモードでは「Recommender Split」と呼ばれる、レコメンドエンジンのための機械学習に適した分割をします。Spilitにはこの他にも、正規表現による分割や単純に行単位で割合を決めて分割するモードがあります。
下図は、Spilitの箱をクリックして出現するコンテキストメニューから「Propertes」をクリックしたときの表示です。使っているモードや、パラメーター類の値が確認できます。

「Recommender Split」では、一部を学習のために使用し、別の一部を評価用に使うようになっています。左側の出力は学習のために利用し、右側の出力は検証用に利用します。
中央と右の箱:Project Columns
次に「Project Columns」を見ていきます。
実際にデータを見ていった方が理解しやすいので、上段中央の箱「Restarunt customer data」からつながっている方の「Project Columns」がどのような出力をしているか見てみましょう。下段中央です。出力データを確認するには、先ほどと同じようにコンテキストメニューから「Visualize」をクリックしてください。
すると、「userId」「latitude」「longitude」「interest」「personality」の5個の項目が表示されています。
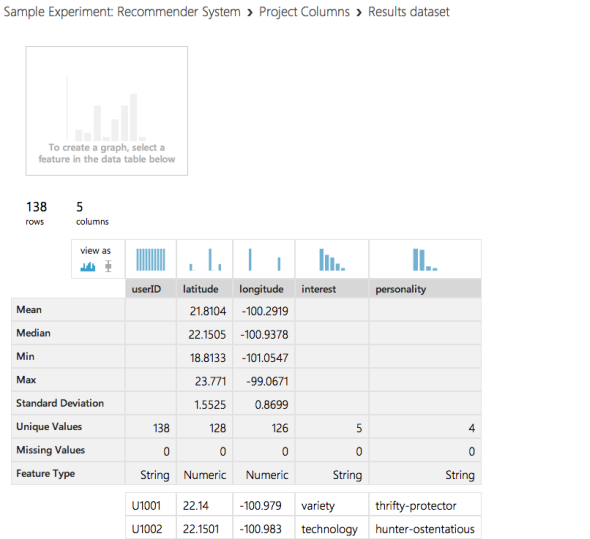 「Project Columns」の出力を表示してみる
「Project Columns」の出力を表示してみるもともとのRestaurant customer dataは以下のような列が存在していました。
| Restaurant customer dataに含まれるデータ列 | |
|---|---|
| Restaurant customer data | |
| userID | |
| latitude | |
| longitude | |
| smoker | |
| drink_level | |
| dress_preference | |
| ambience | |
| transport | |
| marital_status | |
| hijos | |
| birth_year | |
| interest | |
| personality | |
| religion | |
| activity | |
| color | |
| weight | |
| budget | |
| height | |
このようにProject Columnsでは、入力されたデータの中から、必要なカラムだけを抜き出す時に利用します。ここでは中央の箱だけを見ていますが、右側も同様に取得したデータから必要なカラムを抜き出しています。ここでは省略しますが、各自で確認してみてください。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。