Webブラウザーだけで学ぶ機械学習の「お作法」:Webブラウザーでできる機械学習Azure ML入門(2)(4/4 ページ)
お作法5:予測と検証
次は、実際に予測してみて、それが正しいかどうかを検証します。今回のサンプルでは再下段に相当します。
Score Matchbox Recommender
Score Matchbox Recommenderでは先ほどのTrain Matchbox Recommenderの学習結果を利用して、オススメ順にレストランを出してくれる機能です。
 Score Matchbox Recommender
Score Matchbox RecommenderScore Matchbox Recommenderの入力は、四つあります。四つの入力は次のようになっています。
- Trained Matchbox recommender
- Dataset to score
- User features
- Item features
これらの項目それぞれの詳細はドキュメントで確認するとして、ここでは必要な部分に絞ってみていきましょう。これを見ると、箱の上辺一番左側の○印にはTrain Matchbox Recommenderの出力を入れるようになっています。ここでは学習の「結果(=出力データ)」を利用することができるようになっています。実際のフローを見てみても、Train Matchbox Recommenderにつながっています。
Dataset to scoreには、Splitで分割した検証用に使うための実データを入力します。残り二つには学習の時と同じユーザーの情報、レストランの情報を入力します。ここでの出力は、このユーザーにとって評価が高いであろうレストランの一覧になります。実際にこの段階での出力データを見てみましょう。

UserとItem(この場合はレストランを指します)の組み合せが出てきました。一つ例に挙げてみると、U1048というユーザーは135034のレストランに対して高い評価をするであろうという予測が出ています。言い換えると、「U1048というユーザーに135034のレストランをオススメしている」ということです。
Evalute Recommender
次にこの結果がどの程度妥当なのかを検証します。もし妥当であれば、この機械学習のモデルは実践に投入できるかもしれません。テストには「Evaluate Recommender」という箱を利用します。
入力には、先ほどSplitで検証用として取り出したデータを利用します。前述のScore Matchbox Recommenderで使ったものと同じものが入力されることになります。これによって、Score Matchbox Recommenderが出力した結果と、もともと答えの入っているデータの検証ができるようになります。
nDCG(normalized discounted cumulative gain)という方法を使い、どの程度の精度が出ているのかを検証しています。

Evaluate Recommenderでは入力には、テスト用のRatingの実際のデータと、Score Match Recommenderの結果の二つを指定します。つまり、予測データと実データの比較です。この二つを比べてどうなっているか、比較の結果が出力されます。
実際の出力を見てみましょう。

謎の数字「0.918723」の意味
「0.918723」という値が出力されました。さて、この数字は何を表しているでしょうか。おそらく機械学習の「とっつきにくさ」はここにもあると思います。
この0.918723という値が何なのかが分からないので、学習して、テストしてみた結果、良かったのか悪かったのかが分かりづらいということなのでしょう。
今回はnDCGという方法で検証しています。nDCGの説明をすると「AzureMLで簡単にできる」と言っているのに、小難しくなってしまうので、簡単にしておきます。数式がよく分からない人は、ここは適当に読み飛ばしてください。
Column:謎の数字「「0.918723」を読み解く〜nDCGの数学的な裏付け
nDCGの前にDCG(Discounted Cumulative Gain)について紹介しておきます。DCGは関連度の高い要素が上位にあればあるほど評価が高くなります。出力結果の順位iは関連度を持っています。これを関連度Riと表す事にします。
順位pまでの結果に対して、DCG_pを計算すると
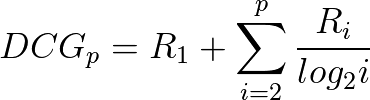
このような数式になります。この今求めたDGC_pに対して、理想的な順位の時のDCGで割って(IDCG)、正規化したものがnDCGです。
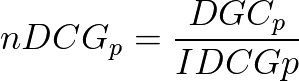
nDCGでは、全くの理想的な順位の場合は1となります。1に近づくほどに正確な結果となってきます。
今回は0.918723という値が出てきているので、データ数の少ないサンプルデータの割には、なかなかの高精度と言えそうです(過学習の可能性もありますが……)。
次回は、ここまで見てきて挙動が理解できたこのサンプルを題材に、すこしアレンジをして、サービスとしてデプロイする方法を見ていきましょう。
<続きは「作った機械学習モデルをWebサービスにしてデプロイする」へ>
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。