作った機械学習モデルをWebサービスにしてデプロイする:Webブラウザーでできる機械学習Azure ML入門(3)(1/2 ページ)
サンプルを使って、機械学習に必要なお作法を学んだところで、今回は実際にインプットとアウトプットのデータを外部から受けられるようにしてみます。このままデプロイしてAPIテストまで進めてみましょう。
連載第1回では環境を用意し、第2回では実際のサンプルをいじりながら使い方をざっと見てきました。
ここからはもう少し実践的に、ここまでに見てきた「Experiments」を改造して、少し違うことをしてみましょう。ここから先の作業は第2回までで操作した続きです。まだ環境が整っていない方は第1回から順に操作していってみてください。
今まで使ってきたサンプルデータは、編集することができないので、「SAVE AS」をクリックして複製し、まずは編集できるようにします。
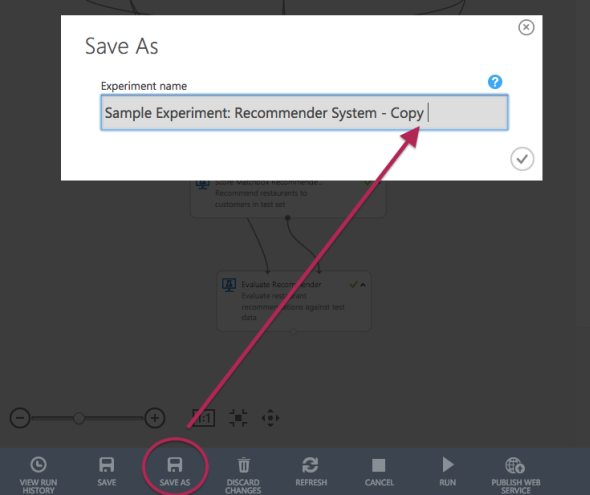 「SAVE AS」をクリックして複製を用意する
「SAVE AS」をクリックして複製を用意するサンプルを実際に使えるように変更してみる
第2回で見てきたサンプルでは、関連度の高いものを順に出していました。しかし、実際にはユーザー(User)がレストランに対してどのような評価(Rate)を付けるのかを予測しないと、効果的なオススメ(レコメンド)はできません。下記二つの変更を施しておきます。
- Rateを付けるために、「Score Matchbox Recommender」のPropertiesのところで「Recommender prediction kind」を「Rating Prediction」に変更
- ここを変更したら、同じように「Evalute Recommender」のPropertiesの「Recommender prediction kind」も同様に「Rating prediction」に変更
さて、この状態で実行してみると、どうなっているのでしょうか?
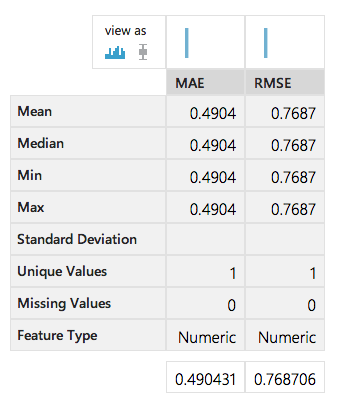 マッチボックスレコメンダーと検証の部分のPropertiesにある「Recommender prediction kind」を「Rating prediction」に変更したところ
マッチボックスレコメンダーと検証の部分のPropertiesにある「Recommender prediction kind」を「Rating prediction」に変更したところMAEとかRMSEが分からなくたって0に近ければいいんです
結果を見てどうでしょう? 「MAE」「RMSE」という項目がありますね。これから機械学習をやろうとする人にとっては、またしても意味が分からない言葉が出現したことと思いますが、ご安心ください。きっとすぐに分かります。
一つ戻って、Score Matchbox Recommenderの出力を見てみましょう。
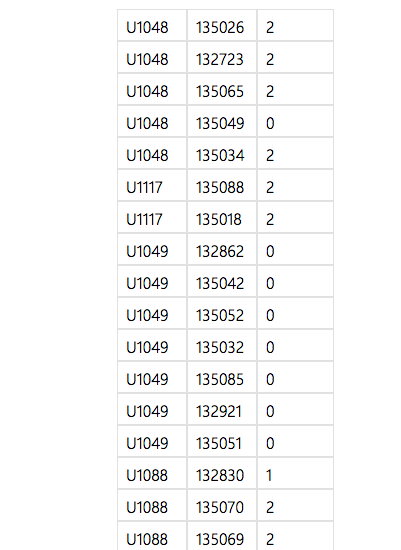 Score Matchbox Recommenderの出力
Score Matchbox Recommenderの出力このデータであれば、「userId(ユーザーID)」「PlaceId(場所ID)」と「rate(評価)」が出ているので、分かりやすそうです。この出力結果は、実はMatchbox Recommenderが「おそらくこのユーザーはこのレストランに対して、これくらいの数値を付けるだろう」という予測を計算しているものです。
先ほどのMAEやRMSEという指標が書かれた出力は、この予測の精度を元に算出したものでした。MAEやRMSEはRating(評価)の実際の値と、機械学習によって得られた値の誤差から、精度を導き出す方法です。それぞれの略称の正式名称は以下の通りです。
- MAE=Mean Absolute Error(平均絶対誤差)
- RMSE=Root Mean Square Error(2乗平均平方根誤差)
実際のデータと今回の機械学習の結果の比較をここに置いておきました。MAE、RMSEの項目には計算式が入っていますので、参考にしてみてください。
実はなぜか、自分の手で計算したものとAzureMLが出してきたMAE、RMSEの値がずれていました。Azure MLの計算では何らかの係数がかかっているのかもしれません。
もし完ぺきな予測ができていたとしたら、MAE、RMSEはともに0になります。今回は「0、1、2」の3段階のRaging(評価)なので、MAE、RMSEの最大(まったく予測が外れている場合)はどちらも2になります(0のはずが2となれば2段階のズレ幅ですね)。
ここまでの操作で実際に比べてみても、「うーんそこまで外れてもないけど、正確でもないかなぁ……」といった感じです。もう少し大量のデータがあれば、MAE、RMSEの値は0に近づいていくだろうと思います。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。