フラッシュストレージの差別化ポイントとDBAがチェックしておきたい機能:Database Expert基礎用語解説(2)(1/2 ページ)
データベースを格納するフラッシュストレージ製品の選定では、「ファームウエア」の機能がストレージの性能と同じほど重要な要素になる場合があります。その理由と関連する機能を見ていきましょう。
本連載では、データベースアプリケーションを速くするためのハードウエアのうち、ストレージI/Oの高速化に寄与する「フラッシュストレージ」を中心に基礎知識を紹介しています。第一回では、データベースアプリケーションのワークロードの違いや、フラッシュストレージの種類を整理しました。今回は、フラッシュストレージアレイのファームウエアの中でも、とりわけ多くのベンダーが切磋琢磨して技術開発を進めている機能を中心に見ていきます。
最適なストレージを選ぶ上では、その目的や環境によって、パフォーマンスを最優先すべきか、あるいは安全性や経済性を重視すべきか、といった具合に、実現したい要件の優先順位に基づいたトレードオフの判断が求められます。もちろん、運用効率も含めて考える必要があります。今回紹介するのは製品資料などでも多く目にする機能ですが、自社の目的・環境に基づいて、適用の可否を慎重に判断することが重要です。
フラッシュストレージのファームウエアが持つ特徴
多くのストレージアレイには、「ファームウエア」という形で組み込み型のOS(ストレージOS)が搭載されています。
ハードウエアがコモディティ化しつつある現在、このファームウエアの品質がフラッシュストレージ製品の特性差に結び付いていることも少なくありません。従って、容量やI/O性能、帯域幅などのハードウエア要素の他に、ファームウエア機能の見極めが重要になってきます。
ストレージベンダー各社は、フラッシュストレージの特性を生かす目的で独自のファームウエアを提供しています。例えば、ストレージベンダーである米ネットアップでは自社ストレージOS「Data ONTAP」を持っていますが、オールフラッシュストレージアレイ製品「FlashRay」は、「Mars」というフラッシュストレージアレイ専用のストレージOSを搭載しています。同様にストレージベンダーである米EMCもフラッシュストレージアレイ製品「XtremIO」に「XtremIO Operating System(XIOS)」という専用のストレージOSを搭載しています。スタートアップ系の若いストレージベンダーも、ファームウエアで差別化を図ろうとしています。
いずれも、フラッシュストレージの特性を考慮し、I/O性能などのパフォーマンス面、価格競争面、管理運用面での付加価値を競う実装になっています。
データ量削減のための技術
ファームウエアには、各種管理機能やストレージ仮想化、自動バックアップやミラーリングの仕組みなど、高度で多様な実装が含まれることが少なくありませんが、直近で注目される機能には「データ圧縮」「重複排除」「データ保護」があります。本連載の主題であるデータベースアプリケーションのパフォーマンスを優先してフラッシュストレージ選定を考える場合には、これらの機能の利用にはトレードオフの判断が必要です。
データ圧縮機能
データ圧縮機能は、名前の通り格納するデータを圧縮する機能です。データ圧縮の方法自体は多岐にわたりますので本稿では深く言及しませんが、テキストファイルなどをzip形式で圧縮した場合に、ファイルサイズが小さくなることと原理は同じです。
着目すべきは、データ圧縮の機能はストレージだけでなくデータベースアプリケーションやサーバーOSが持つものもありますが、いずれの場合も、このデータ圧縮の処理を格納した後に行うのか、格納前に行うのか、格納と同時に行うのかで特性が異なることです。処理負荷をサーバーリソースに委ねるか、ストレージファームウエアのリソースに委ねるかで、同じハードウエアを利用していてもパフォーマンスには差が出るのです。
また、単純なデータ圧縮はJPEG画像などのように既に圧縮が行われているデータではほとんど効果がありませんが、リレーショナルデータベースに格納されているデータや、あるいは今後増えるといわれているIoT(Internet of Things:モノのインターネット)機器から得られるログデータなどを想定した場合、多くが文字列や数字などのテキストデータであることから、データ圧縮によって格納データ容量を削減することができます。
もちろん、データ圧縮機能を利用した場合には、圧縮/展開ともに処理にリソースを使うことになりますので、更新頻度の高いものにこうした機能を適用するのは不適切ですが、格納データを夜間に一度に読み出す処理などで、リソース負荷の影響が軽微であれば、格納容量削減のために利用できるでしょう。
重複排除の使いどころ
データ圧縮の一種である「重複排除」も、多くのフラッシュストレージのファームウエアに搭載されている機能です。格納するデータを特定のデータのまとまり(データチャンク)で比較し、共通するデータをまとめてしまう仕組みです。下で示したのは重複排除のイメージです。図にあるように、データの中で同じものがあればデータ量を削減できます。
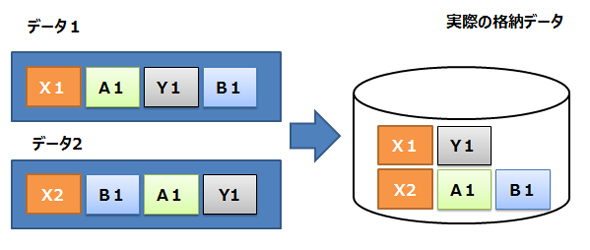 重複排除機能のイメージ 重複したデータを省いて格納することで容量を削減する
重複排除機能のイメージ 重複したデータを省いて格納することで容量を削減する格納データに類似の部分が多い場合は、この重複排除が効果的な場合があります。例えば、VDI(仮想デスクトップインフラストラクチャ)システムで「仮想デスクトップ」を大量に展開する場合、仮想マシンイメージの実体データは、多くの部分が共通になります。そうすると、重複排除できる領域が多くなるため、ストレージが持つデータ量は少なくて済むようになります。
重複排除の仕組みそのものは、製品ごとに比較するデータブロックのサイズ設定が異なったり、あるいは固定長のデータチャンクだけでなく可変長で扱えるものがあったりするので、「同じデータ」と判断される部分(=排除できるデータ量)の比率が異なってきます。結果的に、これが各ファームウエアのデータ圧縮率にも影響を与えます。
この機能を利用する際は、適用するデータの特性と、ストレージファームウエアに実装されている重複排除機能の特性がマッチしていなければ効果的なデータ容量削減はできませんので、理論値ではなく実測での検証が重要です。重複排除処理の実装方法(プリプロセスの処理方法など)も製品によって異なりますので、どのパターンでパフォーマンスに影響があるかも事前に確認すべきポイントです。
また、多くのフラッシュストレージのファームウエアが搭載している機能ではありますが、原則として、重複排除の処理そのものは何らかのリソースを使います。よって、非常に 高いパフォーマンスを求められるデータベースアプリケーションの高速化においては、直接的にこの機能の恩恵を受けることは少ないかもしれません。扱うデータの性質から、重複データが少ないことにより、データ比較処理によるリソース負荷に対して高速化の効果が望めないケースもあるでしょう。
一方で、定期的に実施するデータバックアップや、バッチによる定期的なデータ格納などの際には重複排除が非常に有効なケースがあります。前述のように、重複排除機能のメリットを引き出すためには、製品のスペックだけではなく、自社の目的、環境を踏まえて適用を検討する視点が不可欠となるのです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。