OpenStackを使うと、結局何を効率化できるのか?:特集:OpenStack超入門(7)(2/2 ページ)
クラウド時代の構築作業
本題となるクラウド環境(OpenStack環境)について見ていきます。この例ではサーバー仮想化の時と同様に、すでにOpenStack環境を導入している、もしくはパブリックなOpenStackクラウドを利用している場合を想定します。
まず作業の全体像を図3へ記載します。ここではサーバー仮想化の場合と対比して記載しています。
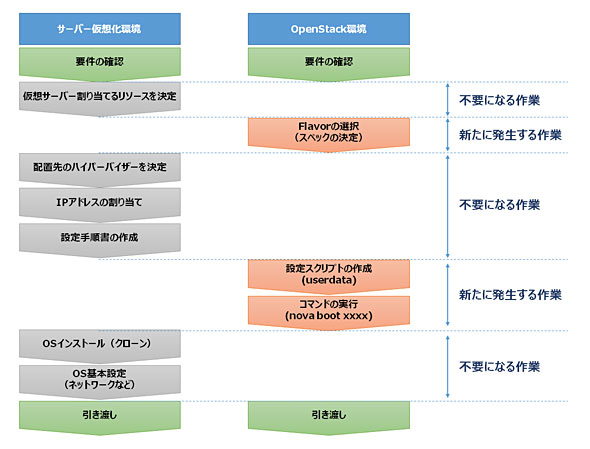 図3 サーバー仮想化環境とOpenStack環境における作業の違い
図3 サーバー仮想化環境とOpenStack環境における作業の違いサーバー仮想化で必要だった作業がほとんどなくなり、代わりに新たな作業項目が加わっているのが分かると思います。実際にOpenStack上で行う作業は3つです。
フレーバーの選択は、OpenStack側に準備されている仮想サーバーのスペック(vCPU数/Mem容量など)のセットから要件を満たすフレーバーを選びます。OpenStackでは細かなスペックを毎回個別に選ぶよりも、あらかじめいくつかのフレーバーを準備しておき、そこから選ばせる方が効率的という思想です。選択肢の幅を狭めて判断を効率化しています。
次に、作成した仮想サーバーで実行させる設定スクリプトを作成します。例えばパッケージのインストールや、設定ファイルの編集といった内容です。いわゆる設定手順書の内容を、スクリプトやレシピという形式で準備しておき、作成した仮想サーバーの起動時に実行させることができます。このときに作成するスクリプトは、同時に何台でも適用できる上に後で使い回すこともできるので、何台でも全く同じサーバーが作成できるようになります。
そして最後にサーバーを作成するためのコマンドを実行します。第3回の記事において、似たようなシチュエーションを取り上げているので、そこからコマンドを引用しつつ、引数を少し変更したものが以下のコマンドです。OpenStack環境においては、このコマンドを実行するだけで、物理環境とサーバー仮想化環境で生じていた全ての作業を実行できます。
# nova boot \
--flavor standard.small \ ←選択したフレーバー
--image centos6 \ ←起動するOSイメージ
--nic net-id=<dmz-net-uuid> \ ←接続するネットワーク1
--nic net-id=<app-net-uuid> \ ←接続するネットワーク2
--key-name user-keys \ ←作成する仮想サーバーへ入れ込むキーペア
--user-data web_server_config.txt \ ←起動時に実行する設定スクリプト
--num-instances 3 \ ←作成する仮想サーバー台数
web-server ←仮想サーバーの名前
図3を見ていただくと、このコマンドによって実にさまざまな作業が簡略化されていることが分かると思います。特に注目してもらいたいのが、物理環境からサーバー仮想化へ進化した際に、新たに発生した「人の判断」の部分がなくなっていることです。他にもIPアドレスの割り当てといった、人が判断していた作業もなくなっています。
このようにOpenStackを導入することによって「人の判断」をなくす、もしくは減らすことができるようになります。これは、OpenStackが仮想マシンの最適な配置や、アドレスの割り当て、設定の入れ込みといった作業を自動的に行ってくれるようにできているからです。
また、この作業フローには出てきませんが、ストレージを割り当てる際のボリューム作成と仮想サーバーとの接続といった作業や、仮想ルーターへのルーティング追加といった作業も不要になります。これらの作業も従来であれば人が「判断」して作業されていましたが、OpenStack上では自動化されています。
このように、OpenStackでは人の判断を必要とする作業を自動化することで、作業のボトルネックを排除するとともに、属人的なミスの可能性をなくすことが可能となります。今回はサーバーを3台増設するという作業ですので、自動化による恩恵は微々たるものです。しかしこれが100台の場合であったり、3台の増設を10回繰り返すような場合には、非常に大きな効果を発揮することは容易に想像できると思います。
このような性質から、OpenStackは開発とリリースが短いサイクルで繰り返されるインターネットサービスの基盤で好んで採用されます。今日ではネット系企業のみにとどまらず、銀行や製造業などでも活用が進んでいます。これは、非IT業だからといって、ITの活用を社内の業務効率化のみに限定するのではなく、自社ビジネスの付加価値創造のために、積極的なサービス開発を行う企業が増えてきたためです。
自動化 vs 人の管理
さて、ここまでの説明では、OpenStackを使うと仮想マシンの配置やIPアドレスの割り当て、ネットワーク接続、ストレージ接続といった、従来は人が判断して作業していた項目をプログラムに任せることになるという話をしてきました。こういった話を聞くと、
いやいや、心配でプログラムに任せておけないよ
今まで手動で管理していたから、これからも手動で管理したい
と感じてしまい、OpenStackに抵抗を感じてしまう方もいると思います。
ですが、考えてみてください。本来、計算機の仕事は「人間の代わりに仕事を行う」「人間には不可能な速度で計算を行う」ということであり、それが計算機の存在理由であるはずです。計算機の歴史とは、人間の作業をいかに計算機に代替させるかへの挑戦でした。
振り返れば、メインフレーム上でタイムシェアリングやメモリを緻密に割り当てていたエンジニアにとって、全てのリソース管理をカーネルが自動的に行うオープンシステムには抵抗があったと思います。また、ディスクシステムをRAIDや論理ボリュームマネジャーに任せることに不安を感じたエンジニアの方もいると思います。
しかし、現代のシステムでは、CPUのタイムシェアリングやメモリ割り当て、ディスク管理、ボリューム管理といった過去に人手で行われていた作業のほとんど全てがソフトウエア側に委ねられるのが当たり前になっています。OpenStackはこのような自動化の考え方が、仮想マシンやネットワーク、ストレージの「管理」という領域まで引き上げられてきたということです。
※この背景には、第3回で説明した「抽象化」によってこれまで人が意識する必要があった、物理層が隠蔽(いんぺい)できるようになったことがあります。ご興味があればこちらも併せて読んでみてください。
当然、ソフトウエアでの制御は人間のような柔軟性がなく融通が効かないため、人がきめ細かな決め事をした場合に比べ、局所的には効率が落ちる面もあります。また、一度使ったシステムをほとんど変更なしに3〜5年間使い続けるという状況では判断をする回数自体が少なくいため、OpenStackが有効に働かないケースもあります。一方で、アジャイルに代表される短いサイクルで開発とリリースを繰り返すシステムやサービスの運用にOpenStack基盤を活用すれば、人の判断がボトルネックにならない自動化の仕組みは強力な効率化を実現してくれます。
少し視点を変えてみると、ハードウエアのコモディティ化が進行し、リソースの単価が劇的に安価になった現在において、図2の右側に表されるような「人の判断」に対して高額な人件費を費やし続けるというのは、コストの面から見てもひどくアンバランスです。
当たり前の話ですが、OpenStackはただ導入すればコストが下がり、運用が簡素化され、クラウド時代に最適なシステムが構築できる、という魔法の技術ではありません。重要なのは技術の特性と自社ビジネスで必要とされるITシステムの特性を正しくマッチングし、最適な環境を提供していくことです。
今回の記事では、作業という点に注目して、OpenStackのもたらす現場の変化について説明をしてきましたが、これまでの特集記事では異なる観点でOpenStackについて解説しています。これらを参考にして、ぜひOpenStackのメリットを理解していただき、自社での活用について検討していただければ幸いです。
著者プロフィール

中島 倫明(なかじま ともあき)
日本OpenStackユーザ会会長(2012〜)
一般社団法人クラウド利用促進機構 技術アドバイザー(2012〜)、国立情報学研究所/TOPSE 講師(2014〜)、東京大学 非常勤講師(2015〜)を勤め、国内でのOpenStack/クラウド技術の普及と人材育成を行う。普段は伊藤忠テクノソリューションズ(CTC)に勤務し、オープンソースソフトウェア(OSS)を中心とした新規クラウド技術の開発と企画を行っている。2014年5月『オープンソース・クラウド基盤 OpenStack入門』(共著/監修:中井悦司、KADOKAWA/アスキー・メディアワークス刊)、2015年1月『OpenStackクラウドインテグレーション入門』(監修/共著:日本OpenStackユーザ会、翔泳社)を執筆。
特集:OpenStack超入門
スピーディなビジネス展開が収益向上の鍵となっている今、ITシステム整備にも一層のスピードと柔軟性が求められている。こうした中、オープンソースで自社内にクラウド環境を構築できるOpenStackが注目を集めている。「迅速・柔軟なリソース調達・廃棄」「アプリケーションのポータビリティ」「ベンダー・既存資産にとらわれないオープン性」といった「ビジネスにリニアに連動するシステム整備」を実現し得る技術であるためだ。 ただユーザー企業が増えつつある一方で、さまざまな疑問も噴出している。本特集では日本OpenStackユーザ会の協力も得て、コンセプトから機能セット、使い方、最新情報まで、その全貌を明らかにし、今必要なITインフラの在り方を占う。

関連記事
- OpenStackが今求められる理由とは何か? エンジニアにとってなぜ重要なのか?
スピーディなビジネス展開が収益向上の鍵となっている今、システム整備にも一層のスピードと柔軟性が求められている。こうした中、なぜOpenStackが企業の注目を集めているのか? 今あらためてOpenStackのエキスパートに聞く。 - OpenStackのコアデベロッパーは何をしているのか
@IT特集「OpenStack超入門」は日本OpenStackユーザ会とのコラボレーション特集。特集記事と同時に、日本OpenStackユーザ会メンバーが持ち回りでコミュニティの取り組みや、超ホットでディープな最新情報を紹介していく。第2回は日本OpenStackユーザ会メンバーで、OpenStack開発コミュニティ コアデベロッパーの元木顕弘氏が語る。 - ますます進化・拡大するOpenStackとOpenStackユーザーたち
@IT特集「OpenStack超入門」は日本OpenStackユーザ会とのコラボレーション特集。特集記事と同時に、ユーザ会メンバーが持ち回りでコミュニティの取り組みや、まだどのメディアも取り上げていない超ホットでディープな最新情報をコラムスタイルで紹介していく。第1回は日本OpenStackユーザ会会長 中島倫明氏が語る。 - 開発環境構築の基礎からレゴ城造り、パートナー交渉術まで〜OpenStack Upstream Trainingの内容とは?
OpenStack Summit Parisでは、数々の先進的な企業事例が登場した一方で、開発コミュニティ参加希望者に向けたオープンなトレーニングプログラムも企画されていた。OSSコミュニティのエコシステムの考え方まで考慮した2日間にわたるプログラムを、参加エンジニアがリポートします。 - OpenStack、結局企業で使えるものになった?
OpenStackを採用することで、企業のITインフラはどう変わるのか、導入のシナリオや注意点は何か。そんな問題意識の下で開催した@IT主催セミナー「OpenStack超解説 〜OpenStackは企業で使えるか〜」ではOpenStackの企業利用の最前線を紹介した。 - OpenStackとレゴタウンとの意外な関係
10月10、11日に東京で実施されたOpenStack Upstream Trainingでは、レゴを使った街づくりのシミュレーションが。レゴはOpenStackプロジェクトとどう関係するのか。 - いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。