BFF(Backends For Frontends)の5つの便利なユースケース:マイクロサービス/API時代のフロントエンド開発(2)
マイクロサービス/API時代のフロントエンド開発に求められる技術の1つ、Backends For Frontends(BFF)について解説する連載。今回はBFFの代表的なユースケースを5つ紹介します。
マイクロサービス/API時代のフロントエンド開発に求められる技術の1つ、Backends For Frontends(BFF)について解説する本連載「マイクロサービス/API時代のフロントエンド開発」。前回の「BFF(Backends For Frontends)超入門――Netflix、Twitter、リクルートテクノロジーズが採用する理由」では連載初回ということで、BFFの概要を紹介しました。
まだBFFは何をするサーバなのか分かりにくい面もあるかと思いますが、シンプルに言えば、APIサーバがビジネスのドメインロジック部分を担当するのに対して、BFFはあくまでユーザーインタフェースをサポートするサーバです。ドメインロジックを使ってシンプルに作れる種類のWebアプリケーションであればBFFは必要ありませんが、マイクロサービス/API時代の現在は、フロントエンド開発において「APIをまとめる」「サーバサイドレンダリングを行う」などが求められる機会も増えてきたと思います。
そこで今回は、BFFの代表的なユースケースを5つ紹介します。
- API Gateway
- Server Side Rendering
- Session Management
- File Upload
- WebSocket、Server Sent Events、Long Polling
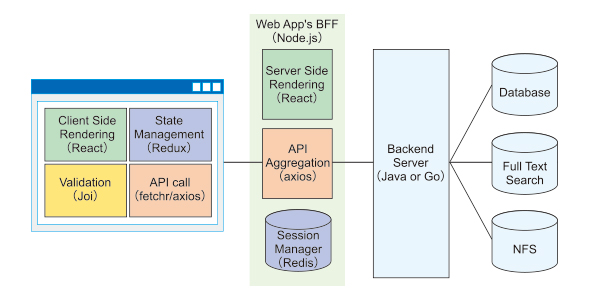
BFFには大別すると、Server Side Renderingのようにクライアントの機能を一部肩代わりするユースケースとバックエンドのAPIサーバとクライアントの間を仲介し、APIの実装をシンプルにするユースケースが存在します。
※ただし、BFFで何でもやってしまうのはむしろアンチパターンです。BFFは、本稿で紹介するようなユースケースで利用されますが、バックエンドのAPIサーバ側やクライアント側の実装を変更することで、BFFを極力分厚い機能にし過ぎないことも重要です。アンチパターンについては次回で詳細に記述します。
API Gateway
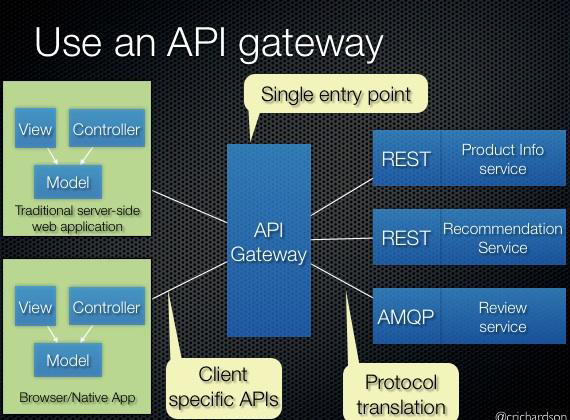
API Gatewayはその名前の通り、APIの入り口を指しています。バックエンドのAPIを経由させる中継点となることで、APIをまとめて複数のAPIを1つに集約したり、APIをクライアント用に翻訳したりするのに利用します。
API Gatewayの中にも幾つか機能があります。下記は主なものです。
- APIを統合する「API Aggregation」機能
- APIのデータをクライアント向けに翻訳する「API Translation」の機能
- 毎回問い合わせる必要がないAPIをキャッシュに保存しておく「API Cache」機能
- 返却されたAPIのレスポンスのうち、一部の情報をフィルタリングすることでデータサイズを縮小させる「API Filter」機能
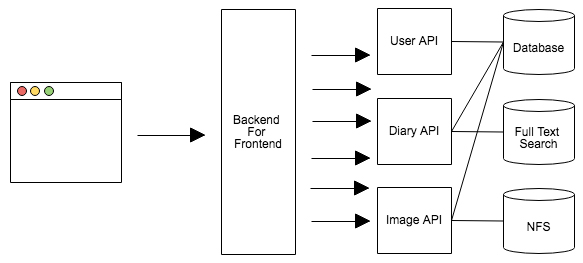
本稿では、代表的な機能として、API Aggregationについて解説します。
マイクロサービスを使ってクライアントを構築する場合、1つの機能を複数のAPI(複数のマイクロサービス)で実現することがあります。例えば、「ページを表示する際に、日記一覧APIから日記の一覧情報を取得して、同時にコメント一覧APIからコメント数件を取得する」といったようなケースです。この場合は複数のAPI(ここでは日記一覧APIとコメント一覧API)を一度に発行する必要があります。
しかし、ブラウザが同時にリクエスト発行できる回数には制限があります。HTTP/1.1では同時に6本までしか接続できません。APIをまとめて発行したいと思っても、この制限により多くは発行できません。また、リクエストを発行するたびにセッションの確認やTCPの接続を行ってしまうとサーバまでのリクエストのコストが高くなります。
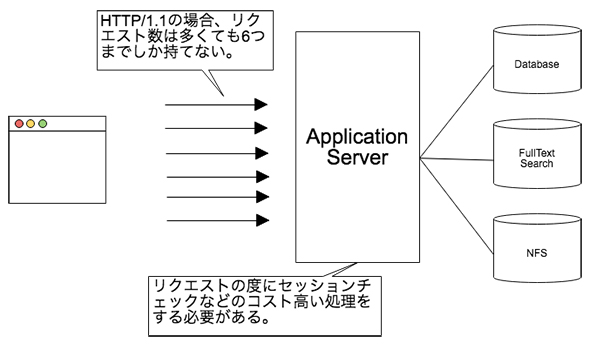
BFFによって、このAPIをまとめて1つのリクエストにすることが可能になります。こうすることで、ブラウザのリクエスト数の制限を受けません。
またセッションの確認もTCPの接続も一度で済ませることができるため、ブラウザから見たときのネットワークリソースは効率的です。
API Gatewayの他の機能については「API Gateway Pattern」を参照してください。
 「
「Server Side Rendering
Server Side RenderingはサーバサイドでHTMLを構築するために利用します。サーバからJSONを受け取り、クライアントでHTMLを構築することを「Client Side Rendering」と呼び、一方で、クライアントとサーバで共通のコードを使ってHTMLを構築することをServer Side Renderingと呼びます。
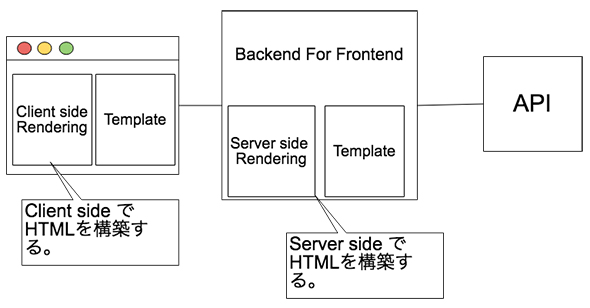
昨今のWebアプリケーションはHTMLを返すだけではなく、JSONをデータフォーマットとして扱い、クライアントサイドでHTMLを構築することも多いですが、HTMLがサーバサイドで必要なケースはまだ多く、特に「検索エンジンの最適化」「初期表示の高速化」といった領域で活用されます。
検索エンジン最適化
Googleに代表される検索エンジンのクローラはJavaScriptを実行する機能を持っており、HTMLをClient Side Renderingで構築してからインデックスすることが可能です。しかし、検索エンジンのクローラも完璧ではなく、確実にJavaScriptが動作するとは限りません。JavaScriptの新しい構文に対応していないクローラも存在しますし、スクロールして初めて表示されるような無限スクロールを持ったWebページを作っている場合、クローラはスクロールしないので、検索インデックスにスクロール後の内容は載りません。
検索エンジンに対しては、できれば検索インデックスに載せたい情報は初期からHTMLに構築しておく方が推奨されています(参考:【Google SEO】JSフレームワークを使ったサイトではプリレンダリングを推奨 | 海外SEO情報ブログ)。
初期表示の高速化
またClient Side RenderingではHTMLを構築するのにJavaScriptのロードが必要なため、その分のコストがかかります。Server Side RenderingではHTMLが最初から存在している分、初期表示では高速化されます。
 「
「Universal Application
このように、Server Side RenderingはClient SideとServer Sideで共通した機構を使ってHTMLを構築するための仕組みですが、単純に実装してしまうと、クライアントでもサーバでもViewを構築する必要があり、二重に開発が必要になってしまいます。これを防ぐためにサーバサイドでもクライアントと同じ仕組み(Webの場合は、JavaScript)を使ってレンダリングする機構が使われます。この機構のことを「Universal Application」と呼びます。
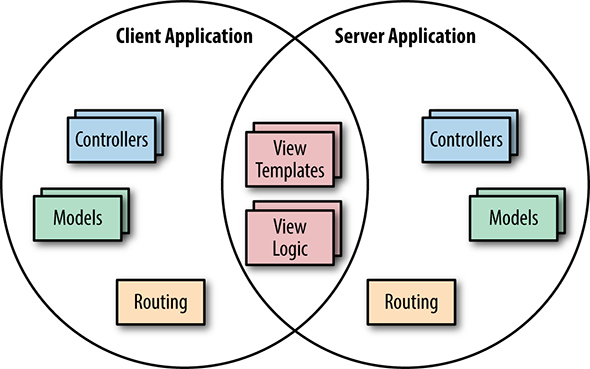
最近では、クライアントで「React.js」「Vue.js」を採用し、サーバでも同じくReact.jsやVue.jsでレンダリングするといった例が見られるようになりました。React.jsには「Next.js」というServer Side Renderingを実現するフレームワークがあります。Vue.jsでは「Nuxt.js」といったフレームワークを使ってServer Side Renderingを比較的簡易に実装するケースが増えています。
なお、リクルートテクノロジーズでも同様の機能を持ったボイラープレートを構築中です(参考:redux-pluto // Speaker Deck)。
Session Management
Session Managementはユーザーの情報を保持しておくための管理機能です。
Session ManagementのSession(セッション)とは、ここではクライアントとサーバ間で双方向に通信をする際のユーザーセッションのことを指します。ユーザーセッションを管理するにはクライアントが「どのユーザーなのか」といった個人をサーバが認識する必要があります。多くの場合、アクセスしたユーザーにCookieを付与し、そのCookieにひも付いた「ユーザーの情報」を管理します。ユーザーの情報とはユーザーIDや氏名、アイコン、「ログインしたかどうか」といった情報です。
これらのユーザーの情報は頻繁にアクセスされるため高速に取得されることが求められます。そのため実装としてはRedisやmemcachedといった高速なデータストアに保持しておくことが多いです。「クライアントが誰なのか」などの情報を高速なデータストアから取得するという役割をBFFで実装すれば、バックエンドのサーバは状態を保持する必要がなくなり、APIサーバの実装はシンプルになります。
具体的にショッピングカートを利用するECサービスで考えてみましょう。ECサービスでは基本的に下記のような行動を実行することが多いです。
- 購入するアイテムを表示する
- 購入するアイテムをショッピングカートに入れる
- レジで購入手続きをする

2.のアクションを実施した時点ではまだ購入が確立していないため、バックエンドのAPIに対してアイテムの在庫を減らすリクエストは送らずに、セッションに入れます。3.のアクションを実施した時点で手続きを完了し、アイテムの在庫を減らすリクエストを実際にバックエンドに発行します。
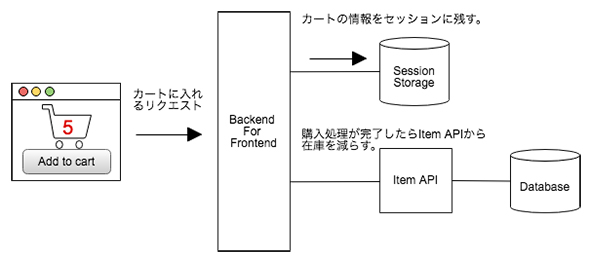
このように、Session Managementは一時的な状態をクライアントのために保持しておくのに利用します。
BFFがない状態で、クライアント側でSession Managementを行う場合、クライアントのCookieやLocal Storage、Indexed DBといったクライアントのストレージを利用することになります。その場合、多量の状態を管理できない上にセキュリティ面でもケアすることが多くなります。
また、バックエンドのAPIサーバにセッションを管理させる場合、同じ処理を他のマイクロサービス化されたAPIサーバでも実施する必要があり、重複処理が多くなります。BFFでSession Managementをすることで、バックエンドのAPIサーバの実装をシンプルに保ちつつ、セキュリティ面でケアすることを減らす効果があります。
File Upload
File Uploadは画像や動画といったメディアファイル、TXTやCSVなどのテキストファイルをアップロードする機能です。ファイルをアップロードするとき、サイズによってはチャンク化されたファイルを少しずつ送ることが多いため、単純なリクエスト/レスポンスの処理では実装しにくく、APIとしても実装するのか難しい機能です。BFFがこのレイヤーを担当することでAPIサーバの実装をシンプルにすることが可能です。
File UploadもBFFがない状態でクライアントとAPIサーバだけで構築すると、非効率的なものになりがちです。特によくあるケースは、クライアントでファイルの内容をbase64などでエンコードし、テキスト情報にした後、JSONで値をPOSTするといったものです。
base64でエンコードする場合、パディングや改行が含まれたテキストに変換されるため、約1.4倍のサイズに容量が増えてしまいます。これによって、5MBのファイルであっても7MBのサイズを送ることになり、非効率的です。
データの転送を軽量にするためにはテキストベースのJSONではなく、バイナリデータとしてチャンク化して少しずつ送る方法や、FORMのmulti-partにして送る方法などがあります。こうなると、単純なJSONベースのAPIサーバでは実装し切れません。
そこでBFFが、ファイルのアップロードの一次受付を担当します。JSONではなく、form/multi-partでファイルの受信を受け付けたり、大容量のファイルの場合は分割してチャンク化したり、チャンク化したデータを少しずつ受信したりして、ファイルを書き出すといった役割を担います。
こうすることで、バックエンドのAPIサーバは格納先のファイルパスを渡すだけのシンプルな状態を保つことができます。
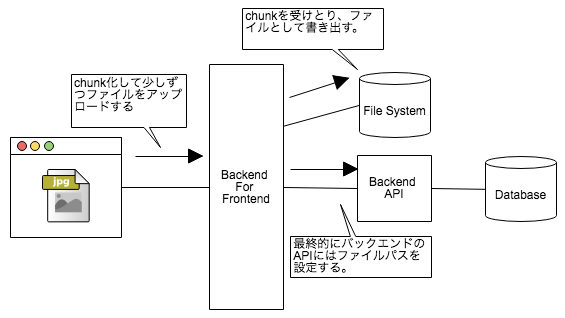
このように、バックエンドのAPIサーバとクライアントの間でAPIの読み替えを行うのもBFFの役割です。ファイルアップロードは一例ですが、次のWebSocketも同様のユースケースです。
WebSocket、Server Sent Events、Long Polling
WebSocket、Server Sent Events、Long Polling はクライアントとサーバ間で即時に通信をするためのHTTPの拡張機能です。特にWebSocketはチャットや同時編集などのリアルタイム性の強いアプリケーション向けに検討されている通信方式であり、SNSなどのアプリケーションで利用されることがあります。また、Server Sent Events、Long Pollingも同様に即時に通知を受け取ると行った処理に使われている通信方式です。
これらも単純なJSON形式でやりとりするAPIサーバで実行するプロトコルとは実装方法が大きく異なります。WebSocketを受け付けるエンドポイントを設け、そこでリアルタイムにデータを交換しつつ、バックエンドのテーブルにデータを格納させる必要があります。BFFがそのエンドポイント部分を担えば、バックエンドのAPIサーバの実装がシンプルになります。
次の図はAPIサーバとクライアントの間でBFFがリアルタイム通信を担っているときの様子です。
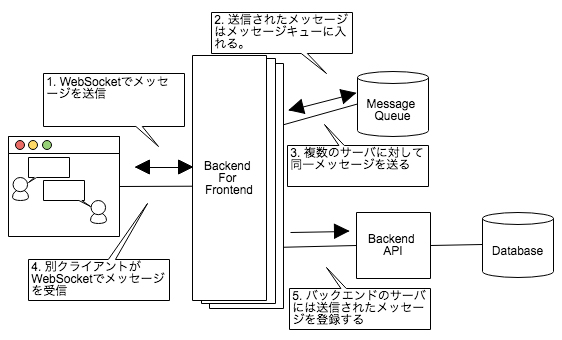
クライアントであるブラウザは「1. WebSocketで接続しながらメッセージを送信」します。そこで送信されたメッセージはBFFで受信され、BFFは「2. メッセージをメッセージキューに入れる」処理を行います。
メッセージキューは「3. 多重化されたBFFサーバの全てにメッセージを送ります」(BFFサーバも同時に接続するクライアントの数が増えると、高可用性を維持するために多重化してマルチサーバで動作させる必要があります)。
キューからメッセージを受信した後「4. 別のクライアントがメッセージを受信」します。それらのリアルタイムな同期処理が終わった後、BFFは「5. バックエンドのサーバにメッセージを登録する」処理を行います。
先ほどのFile Uploadと同様、ここでもバックエンドのAPIサーバに対しての読み替えを実施しています。
BFFを使う際に、どのように始めるのがいいのか
今回は代表的なユースケースとして、5つの機能を紹介しました。
- API Gateway
- Server Side Rendering
- Session Management
- File Upload
- WebSocket、Server Sent Events、Long Polling
この他にも例えばBackend APIが不通になった際に仮のデータを返す「Circuit Breaker」の機能や「APIのキャッシュ」機能といったユースケースがあります。
ただ、BFFに何でも機能を載せてしまうとBFFに負荷が集中してしまい、本来の責務が行えなくなることもあります。BFFはユーザーインタフェース層のサーバであり、マイクロサービスとリッチなWebアプリケーションを構築する際のアーキテクチャパターンのため、機能の載せ過ぎは禁物です。
まずはAPI GatewayやServer Side Renderingといった代表的な使い方から始めて徐々に機能を増やしていくことを推奨します。そこで次回は、BFFを使う際に、どのように始めればよいかについて解説します。
関連記事
 Chatwork、LINE、Netflixが進めるリアクティブシステムとは? メリットは? 実現するためのライブラリは?
Chatwork、LINE、Netflixが進めるリアクティブシステムとは? メリットは? 実現するためのライブラリは?
本連載では、リアクティブプログラミング(RP)の概要や、それに関連する技術、RPでアプリを作成するための手法について解説します。初回は、「リアクティブ」に関連する幾つかの用語について解説し、リアクティブシステムを実現するためのライブラリを紹介します。 React/Redux/Node.jsのSSR/SPAを速くする6つのチューニングポイント
React/Redux/Node.jsのSSR/SPAを速くする6つのチューニングポイント
2004年から続くブログサービス「アメブロ」が2016年9月にシステムをリニューアル。本連載では、そこで取り入れた主要な技術や、その効果を紹介していく。今回は、React/Redux/Node.jsを使ったIsomorphic JavaScript特有のパフォーマンスチューニング手法や実際にあった問題および、その解決方法について。 5分で絶対に分かるAPI設計の考え方とポイント
5分で絶対に分かるAPI設計の考え方とポイント
API設計を学ぶべき背景と前提知識、外部APIと内部API、エンドポイント、レスポンスデータの設計やHTTPリクエストを送る際のポイントについて解説する。おまけでAPIドキュメント作成ツール4選も。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。