[Python入門]バイナリファイルの操作:Python入門(2/3 ページ)
バイナリファイルの読み込み(その2)
今度はもう少し難しい例として、GIFファイルを読み込んで、その形式と縦横のサイズを調べてみよう。例としては、前回に掲載した画像を利用する。なお、既に述べているが、画像ファイルを扱うためのライブラリとしてはPillowがある。実際、画像ファイルを読み書きしたいというときには、それらを使うのが簡単でよいことも付記しておく。
 サンプルのGIFファイル
サンプルのGIFファイルこの画像ファイルをダウンロードしたら、Jupyter Notebook環境で[File]メニューから[Open]を選択して、ファイル一覧ページを表示する。

ページ右上に[Upload]ボタンがあるので、これをクリックして、ファイル選択ダイアログでダウンロードしたファイルを指定する。
![[Upload]ボタンをクリック](https://image.itmedia.co.jp/ait/articles/1910/01/di-pybasic3910.gif)
![ダウンロードしたファイルを指定して、[開く]ボタンをクリック](https://image.itmedia.co.jp/l/im/ait/articles/1910/01/l_di-pybasic3911.gif)
![画像ファイルの横にある[Upload]ボタンをクリックする](https://image.itmedia.co.jp/ait/articles/1910/01/di-pybasic3912.gif)
ダウンロードしたGIFファイルのアップロード
これで準備は完了だ。
GIFファイルは画像のデータを保存しているバイナリファイルだ。バイナリファイルは多くの場合、その種類によって、データがどのように保存されているかの仕様が定められている。バイナリファイルにデータを保存するときや、逆にデータを読み込むときには、その仕様に従って保存や読み込みを行う。GIFファイルの場合、大まかには次のようになっている(以下は、W3CのGIF89aの仕様書を基に作成)。
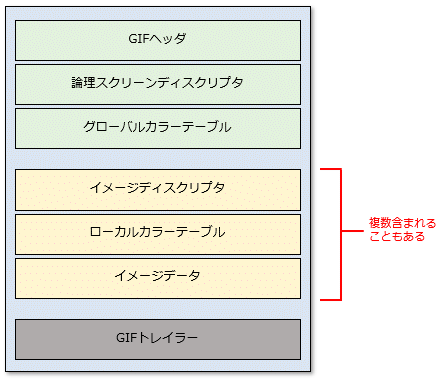 GIFファイルのフォーマット
GIFファイルのフォーマット先頭のGIFヘッダと論理スクリーンディスクリプタを調べれば、GIFファイルの形式と画面サイズが得られるので、ここではそれ以外は無視する。GIFヘッダは3バイトのシグネチャ「GIF」(16進数表記で「\x47」「\x49」「\x46」)に続けて、同じく3バイトのバージョンが続く。バージョンは「87a」(16進数表記で「\x38」「\x37」「\x61」)または「89a」(16進数表記で「\x38」「\x39」「\x61」)のいずれかだ。これらを合計すると、GIFヘッダは6バイトになる。
その次に、論理スクリーンディスクリプタがあり、そこに横幅/縦幅の順に2バイトのデータなどが含まれる(他の要素については本稿では省略)。ただし、データが2バイトのときには、その並び順(バイトオーダー)にも注意が必要だ。例えば、バイナリファイルに2進数表記で「0001 0000」、16進数表記で「01 00」という2バイトのデータがあったとき、それが著している値はどう解釈すればよいだろう。
こうしたデータの解釈方法には大きくリトルエンディアンとビッグエンディアンという2つがある。リトルエンディアンというのは、下位バイトから順にデータが並んでいると解釈する方法で、ビッグエンディアンは上位バイトから順にデータが並んでいると解釈する。上の例なら、リトルエンディアンなら下位バイトが先にあるので、「01 00」という並びは実際には「00 01」という16進数と解釈できる。ビッグエンディアンならそのまま「01 00」となる。これらを10進数に直せば、それぞれ「1」と「16」になる。
GIFの仕様では、下位バイトから先に並べることになる(LSB first。リトルエンディアンと同様な意味)。
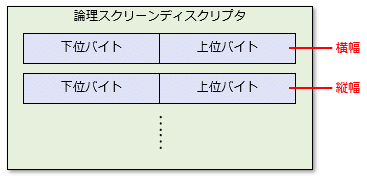 スクリーンディスクリプタの仕様
スクリーンディスクリプタの仕様要するに、GIFファイルの先頭の10バイトを調べると、GIFの仕様と画面サイズが分かるということだ。
では、これをPythonの関数に仕立ててみよう。
def get_dimension(filename):
f = open(filename, 'rb')
spec = f.read(6).decode()
width = int.from_bytes(f.read(2), 'little')
height = int.from_bytes(f.read(2), 'little')
f.close()
print(f'this file is {spec}, size: {width} x {height}')
まず、指定されたファイルをバイナリモードで読み込み用にオープンする。次に、readメソッドで先頭の6バイトを読み込んで、それをdecodeメソッドで文字列に戻したものを変数specに代入する。バイナリファイルからデータを読み込むと、「GIF」に対応する「\x47」「\x49」「\x46」などの値が得られるので、それらをdecodeメソッドで文字列に変換している。
横幅と縦幅については、int型のクラスメソッドであるfrom_bytesメソッドを使って、readメソッドで読み込んだ2バイトのbytesオブジェクトを整数に変換している。このメソッドの第2引数にはバイトオーダーとして先にも述べたようにリトルエンディアン('little')を指定している。
読み込みが終わったら、ファイルをクローズして、それぞれのデータを保存するだけだ。
実際にこの関数に先ほどの画像ファイルのファイル名を渡してやると、その結果が表示される。
get_dimension('di-pybasic3801.gif')
実行結果を以下に示す。
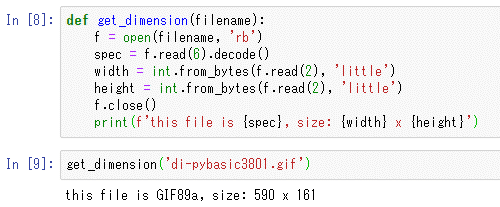 実行結果
実行結果この画像の横幅と縦幅は「590×191」となっている。実際に合っているのが分かるはずだ。
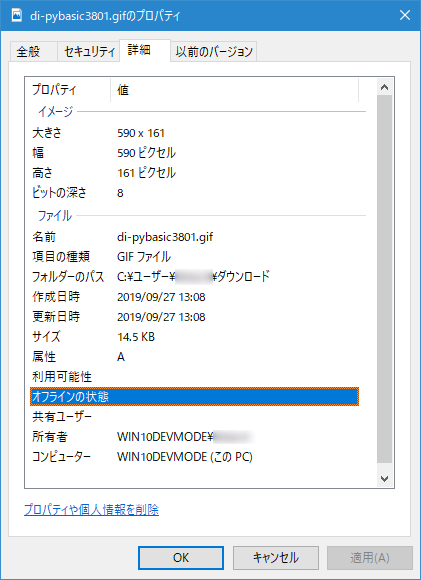 GIFファイルのプロパティ
GIFファイルのプロパティCopyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。