第4回 知ってる!? TensorFlow 2.0最新の書き方入門(初中級者向け):TensorFlow 2+Keras(tf.keras)入門(2/2 ページ)
(2)Sequentialオブジェクトのaddメソッドで追加[tf.keras - Sequential API]
先ほどの(1)は、tf.keras.models.Sequentialクラスのコンストラクター呼び出しの引数に、tf.keras.layers.Denseオブジェクトをリスト形式で指定していた。(2)の書き方では、いったん空の状態でSequentialオブジェクトを生成し、そのオブジェクトのaddメソッドを使ってDenseオブジェクトを追加していくだけである。
リスト2-1を見ると、addメソッドの引数指定のところで、Denseクラスのコンストラクターが呼び出されて、Denseオブジェクトが生成&指定されている。
model = tf.keras.models.Sequential() # モデルの生成
# 隠れ層:1つ目のレイヤー
model.add(layers.Dense( # 全結合層
input_shape=(INPUT_FEATURES,), # 入力の形状(=入力層)
name='layer1', # 表示用に名前付け
units=LAYER1_NEURONS, # ユニットの数
activation='tanh')) # 活性化関数
# 隠れ層:2つ目のレイヤー
model.add(layers.Dense( # 全結合層
name='layer2', # 表示用に名前付け
units=LAYER2_NEURONS, # ユニットの数
activation='tanh')) # 活性化関数
# 出力層
model.add(layers.Dense( # 全結合層
units=OUTPUT_RESULTS, # ユニットの数
name='layer_out', # 表示用に名前付け
activation='tanh')) # 活性化関数
# 以上でモデル設計は完了
model.summary() # モデルの内容を出力
# 学習方法を設定し、学習し、推論(予測)する
#model.compile(tf.keras.optimizers.SGD(learning_rate=0.03), 'mean_squared_error', [tanh_accuracy])
#model.fit(X_train, y_train, validation_data=(X_valid, y_valid), batch_size=15, epochs=100, verbose=1)
#model.predict([[0.1,-0.2]])
それ以外は全く同じ内容なので特に難しいところはないだろう。モデル内容の出力例も、図2-1や図2-2を見ると分かるように、書き方(1)と全く同じである。
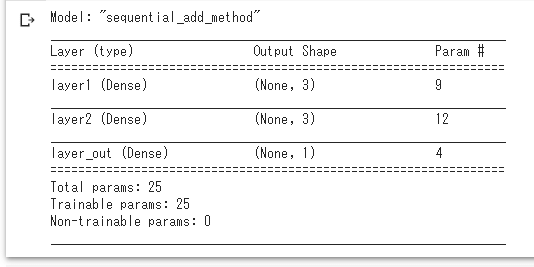 図2-1 モデルの内容を出力
図2-1 モデルの内容を出力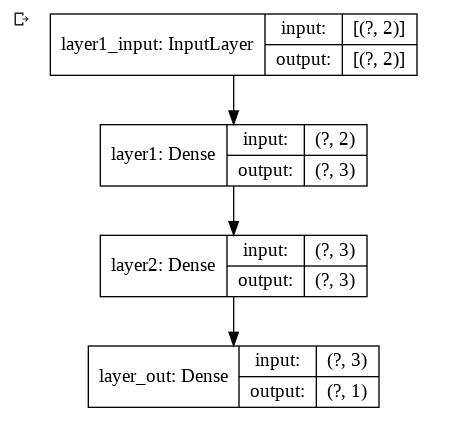 図2-2 モデルの構成図を表示
図2-2 モデルの構成図を表示次にFunctional APIの書き方を見てみよう。
(3)Modelクラスのコンストラクター利用[tf.keras - Functional API]
書き方(3)は、書き方(2)にやや似ている部分がある。まずはリスト3-1の「レイヤーを定義」の箇所のlayer1 = layers.Dense(...)という部分を見てほしい。これは先ほどと同様に、Denseクラスのコンストラクターを呼び出して、Denseオブジェクトを生成&指定しているコードだ。ただし、指定先がlayer1などの変数になっている(つまり、作成したDenseオブジェクトを変数layer1などに代入している)、という違いがある。
# ### 活性化関数を変数(ハイパーパラメーター)として定義 ###
# 変数(モデル定義時に必要となる数値)
activation1 = layers.Activation('tanh' # 活性化関数(隠れ層用): tanh関数(変更可能)
, name='activation1' # 活性化関数にも名前付け
)
activation2 = layers.Activation('tanh' # 活性化関数(隠れ層用): tanh関数(変更可能)
, name='activation2' # 活性化関数にも名前付け
)
acti_out = layers.Activation('tanh' # 活性化関数(出力層用): tanh関数(固定)
, name='acti_out' # 活性化関数にも名前付け
)
# ### レイヤーを定義 ###
# input_shape引数の代わりに、Inputクラスを使うことも可能
inputs = layers.Input( # 入力層
name='layer_in', # 表示用に名前付け
shape=(INPUT_FEATURES,)) # 入力の形状
# 隠れ層:1つ目のレイヤー
layer1 = layers.Dense( # 全結合層
#input_shape=(INPUT_FEATURES,), # ※入力層は定義済みなので不要
name='layer1', # 表示用に名前付け
units=LAYER1_NEURONS) # ユニットの数
# 隠れ層:2つ目のレイヤー
layer2 = layers.Dense( # 全結合層
name='layer2', # 表示用に名前付け
units=LAYER2_NEURONS) # ユニットの数
# 出力層
layer_out = layers.Dense( # 全結合層
name='layer_out', # 表示用に名前付け
units=OUTPUT_RESULTS) # ユニットの数
# ### フォワードパスを定義 ###
# 「出力=活性化関数(第n層(入力))」の形式で記述
x1 = activation1(layer1(inputs)) # 活性化関数は変数として定義
x2 = activation2(layer2(x1)) # 同上
outputs = acti_out(layer_out(x2)) # ※活性化関数は「tanh」固定
# ### モデルの生成 ###
model = tf.keras.Model(inputs=inputs, outputs=outputs
, name='model_constructor' # モデルにも名前付け
)
# ### 以上でモデル設計は完了 ###
model.summary() # モデルの内容を出力
# 学習方法を設定し、学習し、推論(予測)する
#model.compile(tf.keras.optimizers.SGD(learning_rate=0.03), 'mean_squared_error', [tanh_accuracy])
#model.fit(X_train, y_train, validation_data=(X_valid, y_valid), batch_size=15, epochs=100, verbose=1)
#model.predict([[0.1,-0.2]])
また、これまでの連載では、入力層の指定は隠れ層の1番目にinput_shape=(INPUT_FEATURES,)と指定してきた。こうではなく、レイヤーオブジェクトとして入力層を定義することも可能である。これを行っているのが、inputs = layers.Input(...)というコードである。
なお、このときの入力層の形状指定がinput_shapeではなくshapeという引数名になっていることに注意してほしい。
そうやって作成されたinputs/layer1/layer2/layer_outなどの変数を使って、フォワードプロパゲーションの実行パス(=ニューラルネットワークのデータの流れ)を形成する必要がある。書き方(1)や(2)では、リスト値やaddメソッドによる並び順によってフォワードパスが決定していた。今回は変数がバラバラなので、それを明示的に組み立てる必要がある。これを行っているのが、
x1 = activation1(layer1(inputs))
↓
x2 = activation2(layer2(x1))
↓
outputs = acti_out(layer_out(x2))
というコードである。
取りあえず、activation1/activation2/acti_out関数は置いておいて、
入力されたデータinputs → 1つ目の隠れ層layer1 → 出力されたデータx1
↓
伝播されたデータx1 → 2つ目の隠れ層layer2 → 出力されたデータx2
↓
伝播されたデータx2 → 出力層layer_out → 出力された結果outputs
という流れになっていることを確認してほしい。このようなフォワードパスを形成する必要がある。
さらに、ニューラルネットワークでは各ニューロンにおけるデータの出力時に活性化関数でデータを変換する必要があった。これがactivation1/activation2/acti_out関数である。それぞれの関数は、リスト3-1の冒頭に記載されている。例えばactivation1 = layers.Activation('tanh')というコードでは、tf.keras.layers.Activationクラスのコンストラクターに活性化関数名を指定してActivationオブジェクトを生成している。ここに指定できる名前は、第2回で説明済みのものと同じである。
これにより、変数activation1が作成されている。これがx1 = activation1(...)のようなコードで関数のように使われているのが分かる(厳密にはactivation1オブジェクトの__call__()メソッドの呼び出し)。
ちなみに、ニューロン(ノード)へのデータ入力時に行う全結合層の変換は線形変換(linear transformation)と呼び、ニューロンのデータ出力時に行う活性化関数の変換は非線形変換(non-linear transformation)と呼ぶ。
なおリスト3-1では、活性化関数を関数として使えるように切り出したが、書き方(1)や(2)と同様に、Denseクラスのコンストラクター引数activationに文字列で指定することも可能である。その場合、activation1(...)という関数呼び出しはなくなり、x1 = layer1(inputs)のように書ける。ただし、こう書いてしまうと、せっかくのフォワードプロパゲーションの流れが見えにくくなってしまうので、筆者はリスト3-1のような書き方をお勧めする。また、リスト3-1の書き方は次回で説明する書き方(4)にもつながっている。
そうやってできた、入力データinputsと出力結果outputsを、tf.keras.Model()クラスのコンストラクターに指定して、モデルをインスタンス化すれば、モデルの設計は完了である。なお、入力データの引数名はinputs、出力結果の引数名はoutputsである。
それ以外は全く同じ内容なので特に難しいところはないだろう。
モデル内容の出力例は、図3-1や図3-2を見ると分かるように、書き方(1)や(2)と異なり、入力層layer_inや活性化関数activation1がレイヤーとして表示される(※tf.keras.layers名前空間配下のクラスをオブジェクト化した場合は、この活性化関数の例のようにあたかもレイヤーのように扱われる。これは他の多くのライブラリでも同じである)。
 図3-1 モデルの内容を出力
図3-1 モデルの内容を出力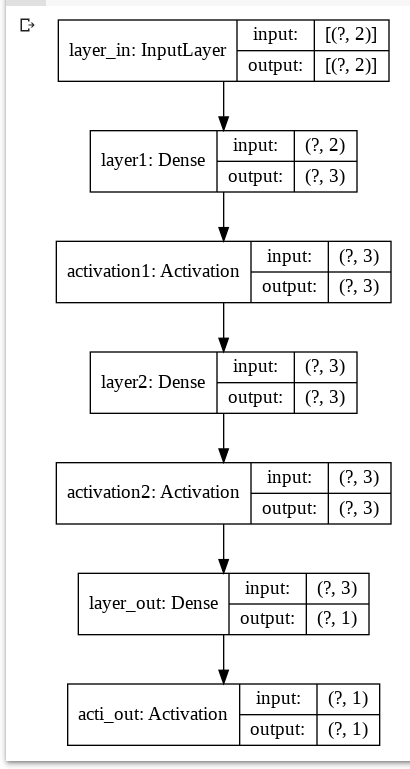 図3-2 モデルの構成図を表示
図3-2 モデルの構成図を表示次回について
今回はSequentialモデル(2通り)とFunctional API(1通り)の2種類(3通り)の書き方について説明した。
今回は初心者〜初中級者向け向けだったが、次回は初中級者〜上級者(エキスパート)向けとなり、書き方の難易度が少し上がる。注意してほしいのは、ニューラルネットワークの理論が難しくなるというのではなく、プログラミングの書き方がよりPython/NumPy的になり、ITエンジニアリングのスキルが要求されるようになる、ということである。
今回の(3)を踏まえて解説するので、(3)は確実に理解しておいてほしい。次回はこちら。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。