Microsoft Research、バグを発見、修正するためのディープラーニングモデル「BugLab」を開発:バグを自動的に埋め込み、それを発見することで学習
Microsoft Researchは、コード内のバグを発見、修正するためのディープラーニングモデル「BugLab」を開発した。BugLabではラベル付きデータを使わずに、バグを自動的に埋め込み、それを発見する“かくれんぼ”ゲームを通じてバグの検出と修正をトレーニングする。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
Microsoft Researchは2021年12月8日(米国時間)に公開したブログ記事で、開発したディープラーニングモデル「BugLab」について紹介した。BugLabはコードのバグを自動的に発見、修正できるAIの開発に向けたディープラーニングの研究成果だ。ラベル付きデータを使わずに、“かくれんぼ”ゲームを通じてバグの検出と修正をトレーニングできる。
Microsoft Researchは、2021年12月に開催されたバーチャルイベント「NeurIPS 2021」で、BugLabを紹介した論文「Self-Supervised Bug Detection and Repair」のプレゼンテーションを行った。
コードの構造の他に自然言語をヒントとして使う
コードのバグを見つけて修正するには、コードの構造を推論するだけでなく、コードコメントや変数名などに含まれる、自然言語によるヒントを理解する必要がある。例えば、次のコードスニペットは、GitHubにあったあるオープンソースプロジェクトのバグとその修正案だ(57行目)。

このコードスニペットを見れば、自然言語のコメントと高レベルのコード構造から、開発者の意図は明らかだ。だが、何らかの理由で間違った比較演算子が使われていた。BugLabはこの問題を正しく認識し、開発者に警告できた。
同様に、別のオープンソースプロジェクトにあった例を示す。次のコードでは正しい変数「read_partition」ではなく、変数「write_partitions」が空であるかどうかを誤ってチェックしていた(67行目)。

Microsoft Researchは、見つけるのが簡単そうに見えて、実は難しい場合が多いこのようなバグを自動的に発見して修正できる、優れたAIの開発を目指している。こうしたバグの発見、修正という厄介な作業から解放されれば、開発者はソフトウェア開発のより重要な、そして興味深い要素に取り組む時間を増やせるからだ。
細かいバグの修正は難しい、ではどうする?
だが、コードの細かい部分には通常、どのような意図があるのか正式な仕様が示されていないため、一見小さなバグであっても、見つけ出すのは難しい。トレーニングデータが足りないため、バグを自動的に認識するように、マシンをトレーニングするのは至難の業だ。膨大なプログラムのソースコードがGitHubなどのサイトで公開されているものの、明示的に注釈されたバグのデータセットは、ごくわずかしかない。
この問題を解決するために、Microsoft ResearchはBugLabの構築に乗り出した。BugLabは、生成的敵対ネットワーク(GAN)から広く触発された“かくれんぼ”ゲームを行うことで学習する2つの競合モデルを使用する。正しいと考えられる既存のコードが与えられると、「バグセレクタモデル」が、意図的にバグを挿入すべきかどうか、どこに挿入するか、その具体的な方法(特定の「+」を「−」に置き換えるなど)を決定する。
セレクタの選択を受けて、バグを挿入するようにコードが編集される。次に、「バグ検出器」と呼ばれるもう1つのモデルが、コードにバグが挿入されているかどうかを判断し、挿入されている場合はバグを特定し、修正する。
 BugLabの概念図 コードがバグセレクタに入力された後、バグセレクタ(Bug Selector)がコードを変更し、意図的なバグを混入する。このデータがバグ検出器(Bug Detector)に入力される。バグ検出器はバグがあるかどうかを判断し、ある場合は、どこをどのように修正すべきかを判断する(出典:Microsoft Research)
BugLabの概念図 コードがバグセレクタに入力された後、バグセレクタ(Bug Selector)がコードを変更し、意図的なバグを混入する。このデータがバグ検出器(Bug Detector)に入力される。バグ検出器はバグがあるかどうかを判断し、ある場合は、どこをどのように修正すべきかを判断する(出典:Microsoft Research)この2つのモデルは数百万のコードスニペットを使って、ラベル付きデータなしで、つまり自己教師あり学習によって共同でトレーニングされる。バグセレクタは、コードスニペットの中に興味深いバグを「隠す」ことを学習し、検出器は、バグを見つけて修正することで、セレクタに勝つことを目指す。このプロセスにより、検出器はバグを検出、修正する能力を高め、セレクタはより難しいトレーニングサンプルを生成するようになる。これが”かくれんぼゲーム”という例えの意味だ。
BugLabのトレーニングプロセスは、概念上GANと似ている。だが、BugLabのバグセレクタは、新しいコードスニペットを何もないところから生成するのではなく、(正しいと想定される)既存のコードを書き換えている。さらに、コードの書き換えは必然的に離散的であり、検出器からセレクタに勾配を伝播(でんぱ)することはできない。
GANとは対照的に、BugLabでは、良いセレクタ(GANの生成器に似ている)ではなく、良い検出器(GANの識別器に似ている)を得ることが重要だ。
この“かくれんぼ”ゲームは、セレクタが検出器に、バグを確実に特定、修正することを教えようとする、教師と生徒のモデルと見なすこともできる。
トレーニングの結果どうなったのか
理論上は、“かくれんぼ”ゲームを広範囲に適用することで、任意の複雑なバグを特定できるようマシンに教えることができるはずだ。だが、そうしたバグの特定は、現在のAIの手法では手が届かない。そのため、BugLabではよく出現する一連のバグに焦点を当てている。
例えば、間違った比較(「<」や「>」の代わりに「<=」を使うなど)、間違ったブール演算子(「or」の代わりに「and」を使うなど)、変数の誤用(「j」の代わりに「i」を使うなど)といったものだ。BugLabシステムをテストするために、Microsoft ResearchはPythonコードに注目した。
検出器のトレーニングを完了した後に、実際のコードで検出器を使ってバグの検出と修正を行った。パフォーマンス測定のために、Python Package Indexに含まれるパッケージのそうしたバグを集めた小さなデータセットに、手動で注釈を付けたところ、“かくれんぼ”手法でトレーニングしたモデルは、ランダムに挿入されたバグでトレーニングした検出器などと比べて、最大で30%高いパフォーマンスを記録した。
バグの約26%が自動的に発見、修正され、有望な結果が得られた。BugLabの検出器が発見したバグのうち19個は、GitHubにある実際のオープンソースコードでこれまで知られていなかったバグだった。ただし、多くの誤検出もあり、こうしたモデルを実用的に展開するには、さらに進化させる必要があるだろう。
機械学習でコードを「理解」できるのか
ディープラーニングモデルに、コードスニペットが何をしているのかを、どうすれば「理解」させることができるのか。過去の研究では、コードをトークン(コードの「言葉」)のシーケンスとして表現すると、それだけでは最適な結果が得られないことが分かっている。構文やデータ、制御フローといった情報に富んだコード構造を利用する必要がある。
そこでBugLabの構築に当たっては、以前の研究にヒントを得て、コード内のエンティティー(シンタックスノードや式、識別子、シンボルなど)をグラフの頂点(ノード)として表現し、それらの関係を辺(エッジ)で示した。
こうした表現を採用すれば、バグ検出器とセレクタをトレーニングするために、さまざまな標準的なニューラルネットワークアーキテクチャを利用できる。BugLabでは、グラフニューラルネットワーク(GNN)とリレーショナルトランスフォーマーの両方を試した。
この2つのアーキテクチャはいずれも、情報が豊富なグラフ構造を利用し、エンティティーとその関係を推論することを学習できる。論文では、これらのモデルアーキテクチャを比較し、一般的に、GNNの方がリレーショナルトランスフォーマーよりも優れていることを明らかにした。
関連記事
 バグを修正するには「3ステップ」が必要、なぜか
バグを修正するには「3ステップ」が必要、なぜか
GitHubのセキュリティ研究者、ケビン・バックハウス氏は同社の公式ブログで、ソフトウェアのバグ修正の際に踏むべきステップを解説した。バグの起きた箇所を修正しなければならないのは当然だが、それ以外にも2ステップの作業が必要だという。 バグのないコードを作るにはオープンソースツールが役立つ、Microsoft Researchが紹介
バグのないコードを作るにはオープンソースツールが役立つ、Microsoft Researchが紹介
Microsoft Researchはバグのないコードの迅速な作成を支援する目的で取り組んでいる4つのオープンソースプロジェクトの概要を紹介した。並列プログラムのバグを検出したり、クラウド向けにREST APIのファジングを助けたりするプロジェクトだ。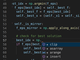 MITとIBMの研究者、自動プログラミングツールの弱点を発見し修正する方法を提案
MITとIBMの研究者、自動プログラミングツールの弱点を発見し修正する方法を提案
MITとIBMの研究者はディープラーニングに基づくコード処理モデルの弱点を発見し、モデルを再トレーニングして、攻撃に対する回復力を高める自動的な方法を発表した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。