NumPyでニューラルネットワークをフルスクラッチ実装してみよう:ニューラルネットワーク入門(2/3 ページ)
ここからの内容に不明点がある場合は、「第2回:逆伝播」も併せてご参照ください。
ステップ2. 逆伝播の実装
損失関数:二乗和誤差

総和(Σ)する処理は関数外で行う仕様のため、リスト13では総和していません。次の導関数(リスト14)も同様の仕様です。
def sseloss(y_pred, y_true):
"""
二乗和誤差(Sum of Squared Error)の関数。
- 引数:
y_pred: モデルの最終出力値=予測値(predicted value)を一次元配列値で指定する。
y_true: 目的となる値=正解値(true/actual value)を一次元配列値で指定する。
- 戻り値:
二乗和誤差の計算結果を一次元配列値で返す。
"""
return 0.5 * (y_pred - y_true) ** 2

∂は偏微分を表し、「ラウンドディー」などと呼びます。
def sseloss_der(y_pred, y_true):
"""
二乗和誤差(Sum of Squared Error)の偏導関数。
予測値(y_pred)に関して二乗和誤差関数(sseloss())を偏微分する。
- 引数:
y_pred: モデルの最終出力値=予測値(predicted value)を一次元配列値で指定する。
y_true: 目的となる値=正解値(true/actual value、label)を一次元配列値で指定する。
- 戻り値:
二乗和誤差の偏微分の計算結果(偏微分係数)を一次元配列値で返す。
"""
return y_pred - y_true
1つのノードにおける逆伝播の処理
逆伝播の処理については、数式の意味が理解しやすいように、基礎編と同じ説明を要約して再掲しておきます。※あくまで要約であり、完全な解説ではありません。
基本的なニューラルネットワークでは、ここまでに実装してきたように線形和関数/活性化関数/損失関数の3つの関数を使います。これら3つの関数の関係をPythonコード的に表現すると、
Loss( # 損失関数。数式ではLと表記
activation( # 活性化関数(出力層にあるj番目のノード)。数式ではzjと表記
summation( # 線形和関数。数式ではujと表記
next_x, # ノードへの入力
w, # 重み
b # バイアス
)
)
)
のような入れ子構造になっています。逆伝播では、連鎖律という数学ルールを用いることで後ろから順番に、
「損失関数の偏微分」×「活性化関数の偏微分」×「線形和関数の偏微分」(それぞれの関数への入力値で偏微分)
と掛け算していく計算をします(図5)。

※損失関数の数式では予測値、つまり出力層の「活性化関数」の出力値を
と表現しましたが、この図では(出力層にあるj番目のノードにおける)「活性化関数」をコード的にactivationj()、数式ではzjと表現しています。また、(出力層にあるj番目のノードにおける)「線形和関数」をコード的にsummationj()、数式としてujと表現しています。
図5は各重みに関して損失関数を偏微分する例ですが、各バイアスや各入力に関して損失関数を偏微分する際も連鎖律の形はほぼ同じです(図6)。ただし入力については、前の層のノードごとに、今の層からの全てのエッジから来る各誤差情報(偏微分係数)を合計する必要があるので注意してください。

図6を数式で表現すると次のようになります。
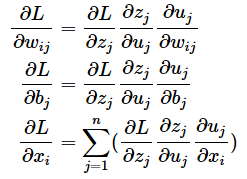
共通する計算の部分を抽出すると、次のように(今の層にあるj番目のノードにおける)δ(デルタ)の数式を定義できますね。
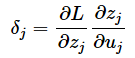
よって最終的には、よりシンプルに次の式にまとめられます。これらが冒頭の図2に掲載した数式です。
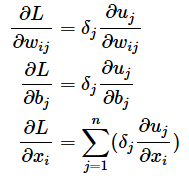
ここまでの説明は出力層におけるものですが、他の層でも同様の計算式になるので共通化することが可能です。具体的に各層における各ノードの計算は、
「逆伝播していく誤差情報」×「活性化関数の偏微分」×「線形和関数の偏微分」
という掛け算に共通化できます(図7)。

本連載(応用編)では、この各層の処理を共通化した計算パターンにのっとって実装していきます。パターン全体の実装を掲載する前に、パターン内の計算処理を、
- (1)逆伝播していく誤差情報
- (2)活性化関数を偏微分
- (3)線形和を重み/バイアス/入力で偏微分
- (4)各重み/バイアス/各入力の勾配を計算
という4つに分けて見ておきます。
(1)〜(4)は層ごとにまとめた処理として実装していきます。※なお基礎編では、(1)は層ごとにまとめた処理、(2)〜(4)はノードごとの処理になっていました。その点が違うのでご注意ください。
(1)逆伝播していく誤差情報
# 取りあえず仮で、変数を定義して、コードが実行できるようにしておく
layer_i = 2 # 2:出力層、1:隠れ層1、0:入力層
layer_max_i = 2 # 最後の層(=出力層)のインデックス
is_output_layer = (layer_i == layer_max_i) # 出力層か(True)、隠れ層か(False)
# 入力層/隠れ層1/出力層にある各ノードの(活性化関数の)出力値
cached_outs = [
np.array([0.05, 0.1]),
np.array([0.5, 0.5, 0.5]),
np.array([0.0])
]
y_true = np.array([1.0]) # 正解値
grads_x = [] # 入力の勾配
# ---ここまでは仮の実装。ここからが必要な実装---
if is_output_layer:
# 出力層(損失関数の偏微分係数)
y_pred = cached_outs[layer_i]
back_error = sseloss_der(y_pred, y_true) # 逆伝播していく誤差情報
else:
# 隠れ層(次の層への入力の偏微分係数)
back_error = grads_x[-1] # 最後に追加された入力の勾配
(2)活性化関数を偏微分
# 取りあえず仮で、変数を定義して、コードが実行できるようにしておく
SKIP_INPUT_LAYER = 1 # 入力層を飛ばす
cached_sums = [
np.array([0.0, 0.0, 0.0]), # 隠れ層1
np.array([0.0]) # 出力層(※入力層はない)
] # 隠れ層1/出力層(※入力層はない)
layer_sums = cached_sums[layer_max_i - SKIP_INPUT_LAYER] # 出力層
# ---ここまでは仮の実装。ここからが必要な実装---
if is_output_layer:
# 出力層(恒等関数の微分)
active_der = identity_der(layer_sums)
else:
# 隠れ層(シグモイド関数の微分)
active_der = sigmoid_der(layer_sums)
(3)線形和を重み/バイアス/入力で偏微分
# 取りあえず仮で、変数を定義して、コードが実行できるようにしておく
PREV_LAYER = 1 # 前の層を指定するため
node_i = 0 # ノード番号
# 重みとバイアスの初期値
weights = [
np.array([[0.0, 0.0], [0.0, 0.0], [0.0, 0.0]]), # 入力層→隠れ層1
np.array([[0.0, 0.0, 0.0]]) # 隠れ層1→出力層
]
biases = [
np.array([0.0, 0.0, 0.0]), # 隠れ層1
np.array([0.0]) # 出力層
]
# 入力層/隠れ層1/出力層にある各ノードの(活性化関数の)出力値
cached_outs = [
np.array([0.05, 0.1]),
np.array([0.5, 0.5, 0.5]),
np.array([0.0])
]
# ---ここまでは仮の実装。ここからが必要な実装---
W = weights[layer_i - SKIP_INPUT_LAYER]
b = biases[layer_i - SKIP_INPUT_LAYER]
x = cached_outs[layer_i - PREV_LAYER] # 前の層の出力(out)=今の層への入力(x)
sum_der_w = sum_der(x, W, b, with_respect_to='W')
sum_der_b = sum_der(x, W, b, with_respect_to='b')
sum_der_X = sum_der(x, W, b, with_respect_to='x')
(4)各重み/バイアス/各入力の勾配を計算
delta = back_error * active_der
NumPyでは2つの多次元配列を*演算子もしくはnp.multiply()関数で掛け算すると、要素ごとの掛け算(アダマール積:⊙)となります。その計算は、数学的に表現すると次のような計算になります。

次に1つの層内にある全てのバイアスの勾配(layer_grads_b変数)を計算します。
# 取りあえず仮で、変数を定義して、コードが実行できるようにしておく
layer_grads_b = [] # 層ごとの、バイアス勾配のリスト
# ---ここまでは仮の実装。ここからが必要な実装---
# 1つのノードに対して、バイアスは「1つ」だけ
layer_grads_b = delta * sum_der_b
リスト19の計算方法も先ほどと同じ要素ごとの掛け算(アダマール積:⊙)です。その計算は、数学的に表現すると次のような計算になります。
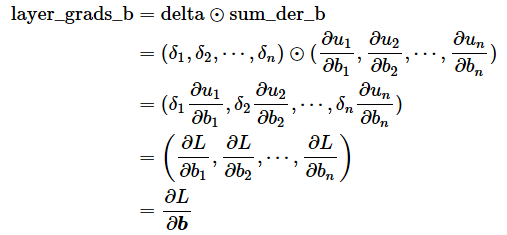
バイアスの勾配の計算結果(一次元配列値)は、各要素に「今の層にあるノード数分(n個)の偏微分係数」がノード順に並んでいますね。この並び順は、重み付き線形和の数式で使ったbと同じです。
より直感的に分かるように、バイアスの勾配の計算を仮の数値で行ってみると、例えば次のようになります。
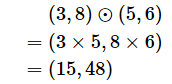
念のため、各重み/バイアス/入力の偏微分計算の図を再掲しておきます(図6)。例えば図の左中央にある「損失関数を/バイアス bj で偏微分」の計算結果が、上記の一次元配列値にある1つの要素に対応しています。
さらに1つの層内にある全ての重みの勾配(layer_grads_W変数)と全ての入力の勾配(layer_grads_x変数)を計算します。
# 取りあえず仮で、変数を定義して、コードが実行できるようにしておく
node_count = len(layer_sums)
# ---ここまでは仮の実装。ここからが必要な実装---
# 1つのノードに対して、重みと入力は「前の層のノードの数」だけある
# 重みは「今の層のノード」×「前の層のノード」の行列で取得する
layer_grads_W = np.dot(delta.reshape(node_count, 1), sum_der_w)
# 入力は「前の層のノード」ごとに「今の層からのエッジ」を全て合計する
layer_grads_x = np.dot(delta, sum_der_X)
# layer_grads_x = np.dot(sum_der_X.T, delta) # こう書いてもOK
まずはリスト20にある「重みの勾配の計算内容」を見てみます。
既に説明したようにreshape()は行列の形状変換をするための関数です。例えばreshape(node_count, 1)であればn(=今の層にあるノードの数)行×1列の列ベクトルに変換しているということになります。
sum_der_wはn行m列の行列ではなく、1行m(=前の層にあるノードの数)列の行ベクトルになっている点に注意してください。前述の「重み付き線形和」の偏微分のコード部分でも説明しましたが、これは実際にはj行m列を意図しており、今の層の何ノード目(j=1,2,…,n)であっても、計算結果が同じ値となるので、しかも行ベクトルの方が逆伝播のNumPyによる計算がしやすかったので、1行に要約しました。
重みの勾配の計算は、数学的に表現すると以下のように表現できます。
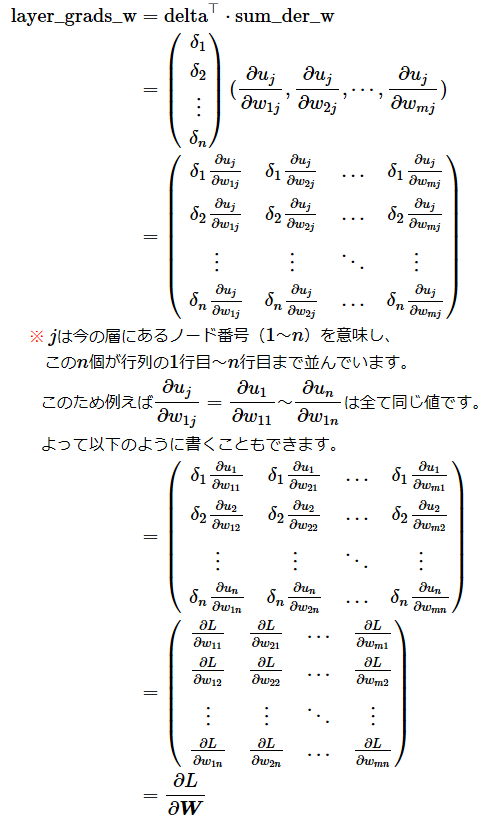
重みの勾配の計算結果(二次元配列値)は、各行に「今の層にあるノード数分(n個)の偏微分係数」がノード順に並び、各列に「前の層にあるノード数分(m個)の偏微分係数」がノード順に並びます。この並び順は、重み付き線形和の数式で使ったWと同じですね。
より直感的に分かるように、重みの勾配の計算を仮の数値で行ってみると、例えば次のようになります。
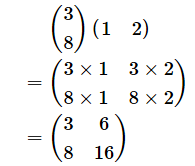
次にリスト20にある「入力の勾配の計算」を見てみます。
sum_der_Xはn行m列の行列です。
入力の勾配の計算は、数学的に表現すると以下のように表現できます。

入力の勾配の計算結果(一次元配列値)は、各要素に「前の層にあるノード数分(m個)の偏微分係数」がノード順に並びます。この並び順は、重み付き線形和の数式で使ったxと同じですね。
注意点として、「前の層にあるノード(からの出力=今の層への入力)」ごとに「今の層からのエッジ」(n個)の計算結果を全て合計する必要があります。(上の数式にもある)行列計算の中で総和(Σ)する計算部分がこの合計処理に該当します。
より直感的に分かるように、入力の勾配の計算を仮の数値で行ってみると、例えば次のようになります。この場合、+で合計していますね。
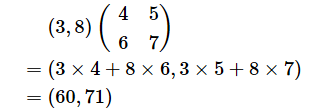
上記のような行列による計算式を組み立てる際には、掛け算や足し算の流れを追ってうまく組み立てる必要があり、特に入力の勾配の計算は頭の中が混乱してしまうかもしれません。落ち着いて組み立てていくしかありませんが、どうしても分からない場合は、基礎編での計算の流れと今回の応用編での計算の流れを逐一比較して、同じ計算内容になるかを確かめてみるとよいかもしれません。
逆伝播の処理全体の実装
ニューラルネットには、層があり、その中に複数のノードが存在するという構造です。従って、
- 逆順に各層を1つずつ処理するforループと、
- 層の中の全ノードをまとめて処理する行列計算、の2段階構造が必要で、ここに行列計算を使った「逆伝播の処理」
を記述すればよいわけです(リスト21)。
def back_prop(layers, weights, biases, y_true, cached_outs, cached_sums):
"""
逆伝播を行う関数。
- 引数:
(layers, weights, biases): モデルを指定する。
y_true: 正解値(出力層のノードが複数ある場合もあるのでリスト値)。
cached_outs: 順伝播で記録した活性化関数の出力値。予測値を含む。
cached_sums: 順伝播で記録した線形和(Σ)値。
- 戻り値:
重みの勾配とバイアスの勾配を返す。
"""
# ネットワーク全体で勾配を保持するためのリスト
grads_w = [] # 重みの勾配
grads_b = [] # バイアスの勾配
grads_x = [] # 入力の勾配
layer_count = len(layers)
layer_max_i = layer_count-1
SKIP_INPUT_LAYER = 1
PREV_LAYER = 1
rng = range(SKIP_INPUT_LAYER, layer_count) # 入力層以外の層インデックス
for layer_i in reversed(rng): # 各層を逆順に処理
# 層ごとに全ノードまとめて処理を行う
layer_sums = cached_sums[layer_i - SKIP_INPUT_LAYER]
node_count = len(layer_sums)
is_output_layer = (layer_i == layer_max_i)
# (1)逆伝播していく誤差情報
if is_output_layer:
# 出力層(損失関数の偏微分係数)
y_pred = cached_outs[layer_i]
back_error = sseloss_der(y_pred, y_true) # 誤差情報
else:
# 隠れ層(次の層への入力の偏微分係数)
back_error = grads_x[-1] # 最後に追加された入力の勾配
# (2)活性化関数を偏微分
if is_output_layer:
# 出力層(恒等関数の微分)
active_der = identity_der(layer_sums)
else:
# 隠れ層(シグモイド関数の微分)
active_der = sigmoid_der(layer_sums)
# (3)線形和を重み/バイアス/入力で偏微分
W = weights[layer_i - SKIP_INPUT_LAYER]
b = biases[layer_i - SKIP_INPUT_LAYER]
x = cached_outs[layer_i - PREV_LAYER] # 前の層の出力=今の層への入力
sum_der_w = sum_der(x, W, b, with_respect_to='W')
sum_der_b = sum_der(x, W, b, with_respect_to='b')
sum_der_X = sum_der(x, W, b, with_respect_to='x')
# (4)各重み/バイアス/各入力の勾配を計算
delta = back_error * active_der
# 1つのノードに対して、バイアスは「1つ」だけ
layer_grads_b = delta * sum_der_b
# 1つのノードに対して、重みと入力は「前の層のノードの数」だけある
# 重みは「今の層のノード」×「前の層のノード」の行列で取得する
layer_grads_W = np.dot(delta.reshape(node_count, 1), sum_der_w)
# 入力は「前の層のノード」ごとに「今の層からのエッジ」を全て合計する
layer_grads_x = np.dot(delta, sum_der_X)
# 層ごとの勾配を、ネットワーク全体用のリストに格納
grads_w.append(layer_grads_W)
grads_b.append(layer_grads_b)
grads_x.append(layer_grads_x)
# 保持しておいた各勾配(※逆順で追加したので反転が必要)を戻り値で返す
grads_w.reverse()
grads_b.reverse()
return (grads_w, grads_b) # grads_xは最適化で不要なので返していない
逆伝播の実行例
何カ所かnp.array()関数を呼び出している以外は、基礎編と全く同じコードです。
x = np.array([0.05, 0.1])
layers = [2, 2, 2]
weights = [
np.array([[0.15, 0.2], [0.25, 0.3]]),
np.array([[0.4, 0.45], [0.5, 0.55]])
]
biases = [
np.array([0.35, 0.35]),
np.array([0.6, 0.6])
]
model = (layers, weights, biases)
y_true = np.array([0.01, 0.99])
# (1)順伝播の実行例
y_pred, cached_outs, cached_sums = forward_prop(*model, x, cache_mode=True)
print(f'y_pred={y_pred}')
print(f'cached_outs={cached_outs}')
print(f'cached_sums={cached_sums}')
# 出力例:
# y_pred=[1.10590597 1.2249214 ]
# cached_outs=[array([0.05, 0.1 ]), array([0.59326999, 0.59688438]), array([1.10590597, 1.2249214 ])]
# cached_sums=[array([0.3775, 0.3925]), array([1.10590597, 1.2249214 ])]
# (2)逆伝播の実行例
grads_w, grads_b = back_prop(*model, y_true, cached_outs, cached_sums)
print(f'grads_w={grads_w}'.replace('\n ', ''))
print(f'grads_b={grads_b}'.replace('\n ', ''))
# 出力例:
# grads_w=[array([[0.00670603, 0.01341205], [0.00748746, 0.01497492]]), array([[0.65016812, 0.65412915], [0.13937182, 0.14022092]])]
# grads_b=[array([0.13412051, 0.14974924]), array([1.09590597, 0.2349214 ])]
ちなみにノートブックの方では、コード中にprint()関数を仕込むことで(※全てコメントアウトしています)、途中の計算内容が順番にテキスト出力されるようにしてみました。リスト22では、以下のように出力されます。
y_pred=[1.10590597 1.2249214 ]
cached_outs=[array([0.05, 0.1 ]), array([0.59326999, 0.59688438]), array([1.10590597, 1.2249214 ])]
cached_sums=[array([0.3775, 0.3925]), array([1.10590597, 1.2249214 ])]
■第3層-全て(2個)のノード:
●(1)逆伝播していく誤差情報(出力層は損失関数:二乗和誤差)の偏微分係数=[1.09590597 0.2349214 ])
●(2)活性化関数(出力層は恒等関数)([1.10590597 1.2249214 ])の偏微分=[1. 1.]
●(3)線形和関数の偏微分:
○重み([[0.4 0.45] [0.5 0.55]])で偏微分=[[0.59326999 0.59688438]]
○バイアス([0.6 0.6])で偏微分=[1. 1.]
○入力([0.59326999 0.59688438])で偏微分=[[0.4 0.45] [0.5 0.55]]
●(4)各重み/バイアス/各入力の勾配を計算:
○デルタ: 逆伝播していく誤差情報([1.09590597 0.2349214 ])×活性化関数の偏微分([1. 1.])=[1.09590597 0.2349214 ]
○バイアスの勾配: デルタ([1.09590597 0.2349214 ])×線形和関数をバイアスで偏微分([1. 1.])=[1.09590597 0.2349214 ]
○重みの勾配: デルタの列ベクトル([[1.09590597] [0.2349214 ]])・線形和関数を重みで偏微分([[0.59326999 0.59688438]])=[[0.65016812 0.65412915] [0.13937182 0.14022092]]
○入力の勾配: デルタ([1.09590597 0.2349214 ])・線形和関数を入力で偏微分([[0.4 0.45] [0.5 0.55]])=[0.55582309 0.62236446]
■第2層-全て(2個)のノード:
●(1)逆伝播していく誤差情報(隠れ層は次の層への入力)の偏微分係数=[0.55582309 0.62236446])
●(2)活性化関数(隠れ層はシグモイド関数)([0.3775 0.3925])の偏微分=[0.24130071 0.24061342]
●(3)線形和関数の偏微分:
○重み([[0.15 0.2 ] [0.25 0.3 ]])で偏微分=[[0.05 0.1 ]]
○バイアス([0.35 0.35])で偏微分=[1. 1.]
○入力([0.05 0.1 ])で偏微分=[[0.15 0.2 ] [0.25 0.3 ]]
●(4)各重み/バイアス/各入力の勾配を計算:
○デルタ: 逆伝播していく誤差情報([0.55582309 0.62236446])×活性化関数の偏微分([0.24130071 0.24061342])=[0.13412051 0.14974924]
○バイアスの勾配: デルタ([0.13412051 0.14974924])×線形和関数をバイアスで偏微分([1. 1.])=[0.13412051 0.14974924]
○重みの勾配: デルタの列ベクトル([[0.13412051] [0.14974924]])・線形和関数を重みで偏微分([[0.05 0.1 ]])=[[0.00670603 0.01341205] [0.00748746 0.01497492]]
○入力の勾配: デルタ([0.13412051 0.14974924])・線形和関数を入力で偏微分([[0.15 0.2 ] [0.25 0.3 ]])=[0.05755539 0.07174887]
■第1層-全て(2個)の特徴量:
●(1)逆伝播していく誤差情報: 【入力層】次の層への入力の偏微分係数=[0.05755539 0.07174887])
grads_w=[array([[0.00670603, 0.01341205], [0.00748746, 0.01497492]]), array([[0.65016812, 0.65412915], [0.13937182, 0.14022092]])]
grads_b=[array([0.13412051, 0.14974924]), array([1.09590597, 0.2349214 ])]
次のページでは最適化の処理をNumPy/線形代数で実装し、デモの回帰問題を解いてみます。ここからはそれほど難しくありません。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。