Pythonで線形代数!〜行列・応用編(行列式・固有値):数学×Pythonプログラミング入門(2/5 ページ)
目標2: 行列式を使っていびつな形の面積を求める
目標1で見た通り、2×2行列の行列式の値は平行四辺形の面積と等しくなります。そして、ベクトルの位置関係によっては負になることもあります。これをうまく使えば、いびつな形の面積も求められます。検算しやすいように簡単な例で見てみます。図3に示す図形の面積を求めてみましょう。

行列式の値は平行四辺形の面積なので、その半分が三角形の面積です。そこで、頂点を反時計回りに2つずつ並べた、以下のような行列を作ります。(3,2)と(1,4)、(1,4)と(−1,2)、(−1,2)と(1,2)を列ベクトルとした行列にすればいいですね。
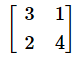
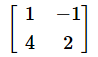
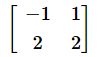
これらの行列式を求め、全て足して2で割れば答えが求められます。
2. 行列式を使っていびつな形の面積を求めるコード
早速やってみましょう。手計算でも簡単ですが、コードを書いて確かめてみます。これまでの知識だけで、リスト4のように書けますね。
import numpy as np
A = np.array([[3, 1],
[2, 4]])
B = np.array([[1, -1],
[4, 2]])
C = np.array([[-1, 1],
[2, 2]])
print((np.linalg.det(A) + np.linalg.det(B) + np.linalg.det(C)) / 2)
# 出力例:
# 6.0
Aの行列式の値が10、Bの行列式の値が6、Cの行列式の値が-4となっている。合計すれば12。これらは平行四辺形の面積なので、2で割って三角形の面積とすればよい。確かに6になっている。
なぜこのようになるのかは、次の図4を見れば明らかですが、念のため動画での解説も用意してあります。確実に理解したい方はぜひご視聴ください。
 図4 行列式の和でいびつな形の面積が求められる理由
図4 行列式の和でいびつな形の面積が求められる理由原点Oと各頂点を結んでできる三角形を考えると、元の図形はブルーの部分からピンクの部分を取り除いたものだということが分かる。行列式を求めると、取り除く部分の符号が負になるので、単に全ての行列式を足せば面積が求められる。平行四辺形を三角形にするために2で割っておく。
動画1 行列式を使っていびつな形の面積を求める
ここまでで、行列式の計算方法と考え方、簡単な応用例を見てきました。以下、本筋から少し外れた長めのコラムをはさみます(が、行列式の図形的な理解とつながるお話です)。固有値や固有ベクトルのお話に進みたい方は、コラムを飛ばしてこちらに進んでください。
コラム χ2検定の中に現れた行列式
目標1で見た行列Aの要素はずいぶんと大きな値でしたね。それらの値はいったい何だったのでしょうか。実は、表1のような2×2分割表の値です。
| 好き | 嫌い | 合計 | |
|---|---|---|---|
| 関西人 | 50 | 18 | 68 |
| 関東人 | 24 | 22 | 46 |
| 合計 | 74 | 40 | 14 |
あるお笑い芸人を好きか嫌いかというアンケートを採った結果。関西人でその芸人を好きと答えた人が50人、嫌いと答えた人が18人、関東人で好きと答えた人が24人、嫌いと答えた人が22人。合計を除いたデータの部分が2×2の形になっている。
2×2分割表の値(合計は除いた部分)を行列Aとして表すと、χ2検定(独立性の検定)で使われる検定統計量Tと呼ばれる値が以下の式で求められます。χ2は「カイジジョウ」と読みます。
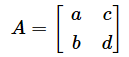
のとき、nを総合計として、
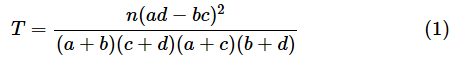
詳細については省きますが、Tの値は、理論的には自由度1のχ2分布(図5)に従う(その確率分布から得られる値である)ことが分かっています。そこで、実際に得られたデータからTの値を求め、それに対するχ2分布の右側確率(P値)が5%(=0.05)よりも小さければ、芸人の好き嫌いと回答者の出身地には関係があると判断します。
 図5 自由度1のχ2分布と右側確率
図5 自由度1のχ2分布と右側確率Tの位置よりも右側の面積がPの値となる。全体の面積は1。Tが大きくなるほど、Pの値が小さくなることに注目。P値は「関係がない」という仮説を棄却することが間違いである確率なので、確率が小さいほど「関係がある」と言いやすくなる。なお、右側確率は上側確率とも呼ばれる。
(1)式をよく見てみましょう。分子の一部に行列式の公式と同じものがありますね。
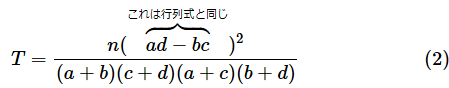
コードを書いてTの値と右側確率Pの値を求めてみましょう。
import numpy as np
from scipy import linalg
from scipy.stats import chi2
A = np.array([[50, 18],
[24, 22]])
n = np.sum(A)
ab_cd = np.prod(np.sum(A, axis=0))
ac_bd = np.prod(np.sum(A, axis=1))
t = n*linalg.det(A)**2 / (ab_cd*ac_bd)
p = chi2.sf(t, df=1)
print("検定統計量:", t)
print("P値:", p)
# 出力例:
# 検定統計量: 5.494134927766641
# P値: 0.019080365467678974
(a+b)(c+d)を表す変数名をab_cdとし、(a+c)(b+d)を表す変数名をac_bdとした。np.sum関数では、axis=0を指定すると行方向の合計(0番目のインデックスが変わる方向の合計)が求められ、axis=1を指定すると列方向の合計(1番目のインデックスが変わる方向の合計)が求められる。np.prod関数は要素の積を求める関数。また、scipy.statsモジュールのchi2.sf関数はχ2分布の右側確率を求める関数。dfは自由度。
リスト5の結果を見ると、P=0.019<0.05なので、芸人の好みと回答者の出身地域には関係がある、ということになります。
実際のところ、ad−bcを求めるのは大した手間ではないので、わざわざ行列式を使うほどのことではありません。また、(1)式は2×2分割表のときにしか使えないので、簡便ですが汎用性には欠けます。さらに言うなら、(1)式を基にTの値を計算しなくても、scipy.statsモジュールのchisquare関数を使えば、配列を指定するだけでχ2検定ができてしまいます(リスト6)。
import numpy as np
from scipy import linalg
from scipy.stats import chi2_contingency
A = np.array([[50, 18],
[24, 22]])
print(chi2_contingency(A, correction=False))
# 出力例:
# (5.494134927766641, 0.019080365467678974, 1, array([[44.14035088, 23.85964912],
# [29.85964912, 16.14035088]]))
scipy.statsモジュールのchi2_contingency関数を使えば、2×2分割表による独立性の検定が簡単にできる(2×2よりも大きな表であっても可能)。引数のcorrection=Falseは、離散値を連続分布で近似するためのイェーツの補正を行わないという指定(補正を行わないとリスト5の結果と同じになる。ただし、補正を行った方が正確な値になる)。順に、検定統計量、P値、自由度、期待値(「関係がない」とするとこの値になるはずという理論値)が表示されている。
長々とお話をしてきましたが、chi2_contingency関数を使えば簡単にできることをなぜ回りくどくやってきたかというと、行列式の図形的な意味を知っていると、Tの値を求める式が実感を持って理解できるようになるからです。(1)式に説明を加えた(2)式をもう一度見てみましょう。
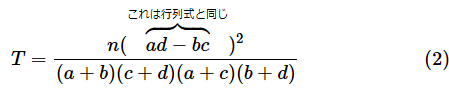
縦横の合計や総合計が変わらないのであれば、nや分母は変わりません。変わるのは行列式の部分だけなので、そこに注目します。すると、行列式の値が小さければTの値も小さくなることが分かります。図5で見た通り、Tの値が小さくなるとP値は大きくなります(「関係がある」とは言いにくくなります)。例えば、行列式の値が0の場合の例としてはリスト2で見た以下のようなものがあります。
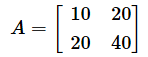
この場合、列ベクトルの(10,20)と(20,40)は、原点から引いた同一直線上にある点です。ということは平行四辺形を作ることができません。従って、平行四辺形の面積は0となり、行列式の値も0になるわけです。その場合、(2)式の値も0となり、Pの値は1(=100%)になります。芸人さんの好き嫌いの表に当てはめて言えば、「回答者の出身地に関係なく、好き嫌いの割合は1:2になっている」ということです。
実は、χ2分布というのは分散の分布で、(2)式の行列式の部分は、実際の値と理論値(期待値)との差のばらつき(分散)を反映した値になっています。分散が0ということは「関係がない場合にはこうなる」という理論値と一致するということです。分散が大きくなるということは、実際の値と理論値とのズレが大きいということですね。
行列式の求め方そのものからはずいぶんと離れてしまいましたが(実用面でも行列式をあまり役立てられない話でしたが)、一見関係のなさそうな話であっても、同じ形の式が現れてきた場合には別の領域の知識が利用できることがあります。あるいは本質的に同じだったということもよくあります……というお話でした。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。