Python偱慄宍戙悢両乣峴楍丒墳梡曇乮峴楍幃丒屌桳抣乯丗悢妛亊Python僾儘僌儔儈儞僌擖栧乮5/5 儁乕僕乯
楙廗栤戣
丂偱偼丄楙廗栤戣偵庢傝慻傒傑偟傚偆丅栤戣偺峫偊曽偵偮偄偰夝愢偟偨摦夋傕梡堄偟偰偁傝傑偡丅偤傂偛帇挳偔偩偝偄丅
摦夋4丂峴楍墳梡偺楙廗栤戣
乮1乯峴楍幃傪巊偭偰僴乕僩宍偺柺愊傪媮傔傞
丂偙偺楙廗栤戣偼栚昗2偺墑挿慄忋偵偁傞傕偺偱偡丅栚昗2偱偼扨弮側恾宍傪巊偄傑偟偨偑丄偙偙偱偼暋嶨側恾宍偱傗偭偰傒傑偟傚偆丅恾6偺傛偆側僴乕僩宍偺撪晹偺柺愊傪媮傔偰偔偩偝偄丅

丂偙偺僴乕僩宍偺捀揰僨乕僞偼儕僗僩12偺僐乕僪偱庢摼偱偒傑偡丅
import numpy as np
data = np.loadtxt('https://raw.githubusercontent.com/Gessys/math/main/data/heart.csv', skiprows=1,delimiter=',')
print(data)
# 弌椡椺丗
# [[ 0. -1. ]
# [ 0.01 -0.97073482]
# [ 0.02 -0.95348411]
# ...
# [-0.02 -0.95348411]
# [-0.01 -0.97073482]
# [ 0. -1. ]]
0楍栚偑x嵗昗丄1楍栚偑y嵗昗偲側偭偰偄傞丅嵟弶偺嶰妏宍偼尨揰偲(0,亅1)丄(0.01,亅0.97073482)偱嶌傜傟丄師偺嶰妏宍偼尨揰偲(0.01,亅0.97073482)丄(0.02,亅0.95348411)偱嶌傜傟傞丅
丂偪側傒偵丄偙偺僨乕僞偼埲壓偺幃偵婎偯偄偰嶌惉偟偨傕偺偱偡*2丅macOS偵晅懏偺Grapher偱愊暘偺嬤帡抣傪媮傔傞偲4.443偖傜偄偵側傞偺偱丄偦傟偵嬤偄抣偑摼傜傟傟偽惓夝偱偡丅
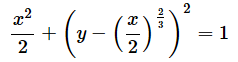

*2丂偙偺僨乕僞偼丄僐乕僪傪彂偒傗偡偔偡傞偨傔丄嵗昗偺愨懳埵抲傪暲傋偨傕偺偵偟偰偁傝傑偡偑丄愭摢偩偗傪愨懳揑側埵抲偵偟丄偦傟埲崀偼堏摦検傪婰榐偟偰偍偄偨曽偑庢傝埖偄偑曋棙偱偡乮愭摢偺埵抲傪曄偊傞偩偗偱恾宍偑堏摦偱偒傑偡乯丅傑偨丄偙偺CSV僼傽僀儖偺撪梕傪SVG僼傽僀儖偵庢傝崬傔偽丄儀僋僩儖僌儔僼傿僢僋僗傪庢傝埖偆偨傔偺僜僼僩僂僃傾傗僽儔僂僓乕偱昞帵偱偒傞傛偆偵側傝傑偡丅偨偩偟丄偙偺僨乕僞偼y幉偺壓偺曽偑彫偝側抣偵側偭偰偄傞偺偱丄僌儔僼傿僢僋傪庢傝埖偆娐嫬偱y幉偺忋偺曽偑彫偝側抣偵側偭偰偄傞応崌偵偼丄忋壓偑媡偝傑偵側傝傑偡丅乧乧偲偄偆偺偼慡偔偺梋択偱偡偑丅
乮僸儞僩乯峴楍傪揮抲偟偰傕峴楍幃偺抣偼曄傢傝傑偣傫丅偙傟傑偱偺偍榖偱偼壓偺幃偺嵍曈偺宍偱峴楍幃傪媮傔偰偄傑偟偨偑丄塃曈偺宍偱傕寢壥偼摨偠偵側傝傑偡丅
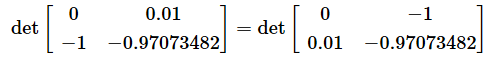
乮2乯暘嶶丒嫟暘嶶峴楍偺屌桳抣偲屌桳儀僋僩儖傪媮傔偰庡惉暘暘愅傪峴偆
丂屌桳抣傪棙梡偡傞偲丄庡惉暘暘愅偲屇偽傟傞暘愅傪峴偆偙偲偑偱偒傑偡丅偦偙偱丄埲壓偺傛偆側僨乕僞傪巊偭偰庡惉暘暘愅傪峴偭偰傒傑偟傚偆丅偙傟偼丄楢嵹戞5夞偱嶶晍恾傪嶌惉偡傞偨傔偵巊偭偨惉愌僨乕僞偱偡丅嶶晍恾傕暪偣偰昤偄偰偍偒傑偡乮儕僗僩13丄恾7乯丅
import numpy as np
import matplotlib.pyplot as plt
english = np.array([98, 77, 64, 45, 58, 62, 89, 30])
mathmatics = np.array([88, 54, 72, 85, 70, 81, 63, 27])
plt.scatter(english, mathmatics, marker='*')
plt.xlabel('English')
plt.ylabel('Math')
plt.show()
8恖偺塸岅偲悢妛偺惉愌丅偙傟傜偺僨乕僞偺摿挜傪偆傑偔昞偡傛偆側捈慄傪媮傔傛偆偲偄偆偺偑庡惉暘暘愅丅
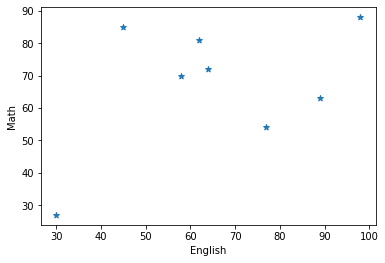 恾7丂塸岅偲悢妛偺惉愌傪僾儘僢僩偟偨嶶晍恾
恾7丂塸岅偲悢妛偺惉愌傪僾儘僢僩偟偨嶶晍恾丂傑偨傑偨偄偒側傝偱偡偹丅庡惉暘暘愅偲偼偄偭偨偄壗偐丄偲偄偆偲偙傠偐傜僗僞乕僩偟側偄偲庤偺晅偗傛偆偑側偄偺偱丄娙扨偵愢柧偟傑偡丅庡惉暘暘愅偲偼丄僨乕僞偑帩偮忣曬傪偱偒傞偩偗幐偆偙偲側偔丄
偲偄偆幃傪嶌傝丄a1, a2, ... an傪媮傔傞偙偲偱偡丅
丂庡惉暘暘愅偼丄懡師尦偺僨乕僞偺師尦傪嶍尭偡傞偨傔偵巊傢傟傑偡乮恾7偺椺偼2師尦側偺偱丄師尦傪嶍尭偟偰傕偁傑傝堄枴偑側偝偦偆偱偡偑丄椺偊偽丄偙偺僨乕僞偺摿挜傪乽曌嫮偑摼堄偐晄摼堄偐乿偩偗偱昞偦偆偲偄偆偙偲偱偡乯丅
丂偙偙偱偼丄曄悢偑塸岅偺惉愌偲悢妛偺惉愌偩偗側偺偱丄塸岅偺惉愌傪x丄悢妛偺惉愌傪y偲偟偰丄忋偺幃傪埲壓偺傛偆偵昞偡偙偲偵偟傑偡乮揧偊帤偑懡偄偲斚嶨偵側傞偺偱x1傪扨偵x偲偟丄x2傪y偲偟傑偟偨乯丅
丂庡惉暘偺媮傔曽偲丄庡惉暘傪夝庍偡傞偨傔偵昁梫側庡惉暘摼揰傪媮傔傞庤弴傪帵偟傑偡丅
- 僗僥僢僾1丗 numpy儌僕儏乕儖偺cov娭悢傪巊偭偰暘嶶丒嫟暘嶶峴楍傪媮傔傞
- 僗僥僢僾2丗 暘嶶丒嫟暘嶶峴楍偺屌桳抣傪媮傔傞
- 僗僥僢僾3丗 屌桳抣偺戝偒偄傕偺偵懳偡傞屌桳儀僋僩儖傪媮傔傞乮偙傟偑戞1庡惉暘偲側傞乯
- 僗僥僢僾4丗 師偵戝偒偄屌桳抣偵懳偡傞屌桳儀僋僩儖傪媮傔傞乮偙傟偑戞2庡惉暘偲側傞乯
- 僗僥僢僾5丗 庡惉暘偲奺僨乕僞傪巊偭偰庡惉暘摼揰傪媮傔傞
丂n師尦偺僨乕僞偱偁傟偽嵟戝n屄偺庡惉暘偑媮傔傜傟傑偡偑丄廳梫側偺偼戝偒側屌桳抣偵懳偡傞庡惉暘偱偡丅僗僥僢僾1乣4傑偱偼偙傟傑偱偺抦幆偱偱偒傞偲巚偄傑偡丅僗僥僢僾5偵偮偄偰偼丄椺偊偽戞1庡惉暘傪昞偡屌桳儀僋僩儖偑(a1,a2)偱偁傞偲偒丄奺僨乕僞傪乮4乯幃偵戙擖偟丄
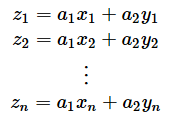
傪媮傔丄z1乣zn偺暯嬒z̄傪寁嶼偟偰丄
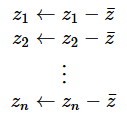
偲偟傑偡丅庡惉暘摼揰偼丄屌桳儀僋僩儖傪嵗昗幉偲偟偨偲偒偺奺僨乕僞偺埵抲傪昞偡傕偺偲峫偊傜傟傑偡丅
丂偙偙偱偼丄庡惉暘暘愅偺巇慻傒偲寁嶼曽朄偵偮偄偰徻偟偔愢柧偡傞梋桾偑側偄偺偱丄棟孅敳偒偱丄忣曬懝幐検傪嵟彫偵偡傞傛偆側捈慄乮庡惉暘乯傪媮傔傞偲丄偦偺學悢a1,a2,..., an偑丄暘嶶丒嫟暘嶶峴楍偺屌桳儀僋僩儖偵側偭偰偄傞偲峫偊偰壓偝偄*3丅

*3丂庡惉暘暘愅偺曽朄偼丄廳夞婣暘愅偲帡偰偄傑偡乮偑丄彮偟堘偄傑偡乯丅廳夞婣暘愅偱偼幚應抣偲夞婣幃偺乽崅偝乿偺嵎傪嵟彫偵偟傑偡偑丄庡惉暘暘愅偱偼丄捈慄偲偺嫍棧丄偮傑傝奺僨乕僞偐傜捈慄偵壓傠偟偨悅慄偺挿偝傪嵟彫偵偡傞傛偆側寁嶼偵側傝傑偡丅偦偆偡傟偽丄奺僨乕僞偺帩偮忣曬偑嵟戝尷丄偦偺捈慄偵斀塮偝傟傞偲偄偆傢偗偱偡丅幬傔偐傜擔偑嵎偟崬傓傛傝丄恀忋偐傜乮悅捈偵乯嵎偟崬傓曽偑擔岝偺僄僱儖僊乕傪嵟戝尷庴偗傜傟傑偡丅偁偔傑偱椺偊偱偡偑丄偦傟偲摨偠傛偆側偙偲偱偡丅
丂庢傝偁偊偢丄偙傟偱僐乕僪偑彂偗傞偲巚偄傑偡丅僾儘僌儔儉偺嶌惉偵庢傝慻傫偱傒傑偟傚偆丅
楙廗栤戣偺夝摎椺
丂埲壓丄夝摎偲僾儘僌儔儉偺嶌惉椺偱偡丅傕偪傠傫丄堎側傞傗傝曽傕偁傞偺偱丄偙傟傜偑桞堦偺摎偊偲偄偆傢偗偱偼偁傝傑偣傫丅
乮1乯峴楍幃傪巊偭偰僴乕僩宍偺柺愊傪媮傔傞
丂偙傟偼娙扨偱偡丅撉傒崬傫偩僨乕僞偺0峴栚偲1峴栚偺峴楍幃傪媮傔丄1峴栚偲2峴栚偺峴楍幃傪媮傔丄2峴栚偲3峴栚偺峴楍幃傪媮傔乧乧偲偄偆嬶崌偵恑傔偰丄偦傟傜偺抣傪崌寁偡傟偽偄偄偱偡偹丅崌寁偟偨抣偼暯峴巐曈宍偺柺愊側偺偱丄嵟屻偵2偱妱傞偙偲傪朰傟偢偵丅
import numpy as np
data = np.loadtxt('https://raw.githubusercontent.com/Gessys/math/main/data/heart.csv', skiprows=1,delimiter=',')
total = 0
rows = data.shape[0] # 峴悢傪摼傞
for i in range(rows-1):
total += np.linalg.det(data[i:i+2])
print(total / 2)
# 弌椡椺丗
# 4.4401816396000084
data[i:i+2]偼i峴栚偐傜i+2峴栚偺庤慜傑偱偲偄偆堄枴丅峴楍幃偺抣傪媮傔偰total偵壛偊偰偄偔丅弌椡椺傪尒傞偲丄4.443偵嬤偄抣偑摼傜傟偨偙偲偑暘偐傞丅
丂幚偼丄恾6傪尒偰傕暘偐傞偺偱偡偑丄偙偺椺偱偼峴楍幃偑晧偵側傞晹暘偑1偮傕偁傝傑偣傫丅偑丄偦傟偼栤戣偱偼偁傝傑偣傫丅晧偵側傞晹暘偑偁偭偰傕丄栚昗2偱尒偨傛偆偵偪傖傫偲柺愊偑媮傔傜傟傑偡丅
乮2乯暘嶶丒嫟暘嶶峴楍偺屌桳抣偲屌桳儀僋僩儖傪媮傔偰庡惉暘暘愅傪峴偆
丂庡惉暘暘愅偲偄偆暦偒姷傟側偄庤朄偑搊応偟偨偺偱丄恎峔偊偰偟傑偭偨乮屌傑偭偰偟傑偭偨乯曽傕偍傜傟傞偐傕偟傟傑偣傫偑丄庤弴捠傝偵恑傔傟偽偱偒傑偡丅
import numpy as np
english = np.array([98, 77, 64, 45, 58, 62, 89, 30])
mathmatics = np.array([88, 54, 72, 85, 70, 81, 63, 27])
V = np.cov(english, mathmatics) # 暘嶶丒嫟暘嶶峴楍傪媮傔傞
print("暘嶶丒嫟暘嶶峴楍丗")
print(V)
DP = np.linalg.eig(V) # 屌桳抣乛屌桳儀僋僩儖傪媮傔傞
print("屌桳抣乛屌桳儀僋僩儖丗")
print(DP)
# 弌椡椺丗
# 暘嶶丒嫟暘嶶峴楍丗
# [[498.83928571 201.64285714]
# [201.64285714 396.85714286]]
# 屌桳抣乛屌桳儀僋僩儖丗
# (array([655.83843329, 239.85799528]), array([[ 0.78903768, -0.61434481],
# [ 0.61434481, 0.78903768]]))
暘嶶丒嫟暘嶶峴楍偼numpy儌僕儏乕儖偺cov娭悢偱媮傔傞丅弌椡椺偺懳妏梫慺偑暘嶶丄嵍壓偲塃忋偑嫟暘嶶偲側傞丅屌桳抣乛屌桳儀僋僩儖偺媮傔曽偼偙傟傑偱偲摨偠丅
丂屌桳抣偺戝偒側曽偼655.838...偱偡丅偦傟偵懳偡傞屌桳儀僋僩儖偼(0.789...,0.614...)偲側偭偰偄傑偡丅偙傟偑戞1庡惉暘偺a1偲a2偵摉偨傝傑偡丅戞2庡惉暘偼丄屌桳抣239.857...偵懳偡傞屌桳儀僋僩儖(亅0.614...,0.789...)偱媮傔傜傟傑偡丅偙傟傜偺屌桳儀僋僩儖傪尒傞偲丄戞1庡惉暘偲戞2庡惉暘偼捈岎偡傞偙偲偑暘偐傝傑偡丅
丂師偵丄庡惉暘摼揰偱偡丅嵟戝偺屌桳抣傪戞1庡惉暘丄嵟彫偺屌桳抣傪戞2庡惉暘偲偡傞偺偼屌桳抣偑2屄偟偐側偄応崌偵偟偐巊偊側偄偺偱偁傑傝僗儅乕僩側傗傝曽偱偼偁傝傑偣傫偑丄偙偺椺偱偼偆傑偔偄偒傑偡丅儕僗僩15偵懕偗偰儕僗僩16偺僐乕僪傪擖椡偟偰偔偩偝偄丅
# 戞1庡惉暘
idx = DP[0].argmax() # 屌桳抣偑2偮側偺偱嵟戝偺曽傪戞1庡惉暘偲偡傞
a1= DP[1][0, idx]
a2= DP[1][1, idx]
# 慡偰偺z傪媮傔傞乮巄掕乯
z = a1 * english + a2 * mathmatics
# z偺暯嬒傪媮傔傞
zmean = z.mean()
# z傪媮傔傞
print("戞1庡惉暘")
print(a1, a2)
print("戞1庡惉暘偺庡惉暘摼揰")
print(z - zmean)
# 戞2庡惉暘
idx = DP[0].argmin() # 屌桳抣偑2偮側偺偱嵟彫偺曽傪戞2庡惉暘偲偡傞
a1= DP[1][0, idx]
a2= DP[1][1, idx]
# 慡偰偺z傪媮傔傞乮巄掕乯
z = a1 * english + a2 * mathmatics
# z偺暯嬒傪媮傔傞
zmean = z.mean()
# z傪媮傔傞
print("戞2庡惉暘")
print(a1, a2)
print("戞2庡惉暘偺庡惉暘摼揰")
print(z - zmean)
# 弌椡椺丗
# 戞1庡惉暘
# 0.7890376766407048 0.6143448094038383
# 戞1庡惉暘偺庡惉暘摼揰
# [ 38.33642279 0.87890806 1.67962484 -5.3256085 -4.28329084
# 5.63065277 15.87646347 -52.79317259]
# 戞2庡惉暘
# -0.6143448094038383 0.7890376766407048
# 戞2庡惉暘偺庡惉暘摼揰
# [ -3.86772704 -17.79376704 4.39539366 26.32543483 6.50338716
# 12.72542237 -18.06456567 -10.22357827]
argmax儊僜僢僪偱屌桳抣偺嵟戝抣偺僀儞僨僢僋僗傪媮傔丄偦傟偵懳墳偡傞屌桳儀僋僩儖偺梫慺傪戞1庡惉暘偲偟偰a1丄a2偵戙擖偡傞丅偁偲偼庤弴捠傝偵z偺抣傪媮傔傞丅戞2庡惉暘偵偮偄偰偼丄argmin儊僜僢僪偱屌桳抣偺嵟彫抣偺僀儞僨僢僋僗傪媮傔丄偦傟偵懳墳偡傞屌桳儀僋僩儖偺梫慺傪a1丄a2偵戙擖偡傞丅偙偪傜傕庤弴捠傝偵z偺抣傪媮傔傞丅
丂戞1庡惉暘偺庡惉暘摼揰傪尒傞偲丄揰悢偺崅偄恖偼庡惉暘摼揰偑戝偒偔丄揰悢偺掅偄恖偼庡惉暘摼揰偑彫偝偄偙偲偑暘偐傝傑偡丅椺偊偽丄嵟弶偺塸岅98揰丄悢妛88揰偺恖偺庡惉暘摼揰偼38.336...偱偡丅堦曽丄嵟屻偺塸岅30揰丄悢妛27揰偺恖偺庡惉暘摼揰偼-52.973...偱偡丅廬偭偰丄戞1庡惉暘偼丄傗偼傝乽曌嫮偑摼堄偐晄摼堄偐乿偲偄偆摿挜傪昞偟偰偄傞傛偆偱偡丅
丂堦曽丄戞2庡惉暘偺庡惉暘摼揰偼丄塸岅傛傝傕悢妛偺惉愌偑偄偄恖偺庡惉暘摼揰偑戝偒偔丄悢妛傛傝傕塸岅偺惉愌偑偄偄恖偺庡惉暘摼揰偑彫偝偔側偭偰偄傑偡丅椺偊偽丄塸岅偑45揰丄悢妛偑85揰偺恖偺庡惉暘摼揰偼26.325...偱丄媡偵丄塸岅偑89揰丄悢妛偑63揰偺恖偺庡惉暘摼揰偼-18.064...偲偄偆抣偱偟偨丅偙偪傜傕摉弶偺梊憐捠傝乽暥壢宯丒棟悢宯乿偲偄偭偨摿挜傪昞偟偰偄傞傛偆偱偡丅
丂乧乧偲偄偆傢偗偱丄崱夞偼丄AI乛婡夿妛廗偵昁梫偲偝傟傞慄宍戙悢偺抦幆偺偆偪丄峴楍幃傗屌桳抣乛屌桳儀僋僩儖側偳偺庢傝埖偄偵偮偄偰丄婎杮揑側峫偊曽偲娭悢傪巊偭偰娙扨偵寁嶼偡傞曽朄丄婔偮偐偺墳梡椺傪尒偰偒傑偟偨丅庤嶌嬈偱偺寁嶼偑戝曄側偺偱擄偟偄偲偐柺搢偩偲偄偆報徾偼偁傞偐傕偟傟傑偣傫偑丄娭悢傪巊偭偰偲偵偐偔寁嶼偟偰傒傞偲丄堄奜偵娙扨偩偲偄偆偙偲偑暘偐傞偺偱偼側偄偱偟傚偆偐丅
丂偝偰丄師夞偱偡偑丄偟偽傜偔慄宍戙悢偺榖戣偑懕偄偨偺偱丄婥暘傪曄偊偰嶰妏娭悢偺棙梡偵偮偄偰尒偰偄偔偙偲偵偟傑偡丅
Copyright© Digital Advantage Corp. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅