機械学習をPythonで学ぼう! 基礎、できること、ライブラリ:機械学習入門
「知識ゼロから学べる」をモットーにした機械学習入門連載の第1回。ルールベースと機械学習ベースの違いから、教師あり学習などの学習方法、回帰/分類などのタスクまで基礎の基礎から説明。機械学習のためのPythonライブラリも概説する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ここを更新しました(公開日:2024年2月8日、更新日:2024年12月2日)
2024年12月2日のColab環境で、記事内の全てのコードが正常に動作することを検証しました。それに合わせてバージョンに関する記述をアップデートしました。
機械学習は、今や私たちの生活や仕事に不可欠なテクノロジーです。朝起きてスマートフォンでチェックするニュース、それはあなたの関心に基づいて機械学習によって選ばれています。オフィスに到着すると確認する今週の売上予測レポート、これもまた過去のデータを基に機械学習が予測したものです。
これだけ便利な機械学習を、自分でも使いこなせたら素晴らしいですよね。それを可能にするのが、この連載の目的です(図1)。
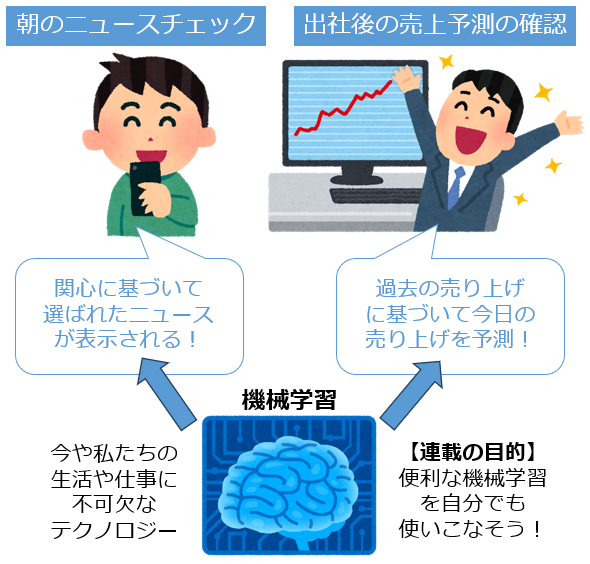 図1 本連載の目的:有用な機械学習を使いこなすために学ぼう
図1 本連載の目的:有用な機械学習を使いこなすために学ぼう「機械学習は難しそう」と思っていませんか? 心配は要りません。
本連載では、「知識ゼロから学べる」をモットーに、機械学習の基礎と各手法を図解と簡潔な説明で分かりやすく解説します。Pythonを使った実践演習もありますので、自分の手を動かすことで実用的なスキルを身に付けられます(図2)。
 図2 本連載のモットー:知識ゼロの人でも安心して基礎から学べる
図2 本連載のモットー:知識ゼロの人でも安心して基礎から学べるまず今回は、機械学習の基本から始め、それが解決できる問題、そしてPython言語のプログラミング環境と代表的なライブラリについて学びます。さらに、読者の理解を深めるための実力試しクイズも用意しています。
ちなみに次回はPythonで機械学習を実践する場合に便利なscikit-learnライブラリの基本的な使い方を紹介し、次々回以降は機械学習の各手法を解説していきます(図3)。
 図3 本連載で学ぶ主な項目(あくまで予定で、変更、追加する場合があります)
図3 本連載で学ぶ主な項目(あくまで予定で、変更、追加する場合があります)それではさっそく、まずは基礎中の基礎から始めていきます。この基礎レベル(例えば自己教師あり学習/強化学習や、クラスタリング/次元削減、目的変数/特徴量、NumPy/pandasなど)が既に理解できている方は、今回はスキップしても構いませんが、次回以降の新着記事を見逃さないように、以下のメール通知の登録をお願いします。

機械学習とは
機械学習(Machine Learning:ML)は、コンピュータプログラム(機械)がデータから学習し、パターンや関連性を自動的に見つけ出す技術です。これにより、新しいデータに対して予測や判断が可能になります。
これは人間が経験から学ぶ過程に似ています(図4)。人間の子供は、犬や猫を見て覚えることで、犬か猫かを区別できるようになります。同様に機械学習も、データから犬や猫の特徴を学ぶことで、犬か猫かを判別できるようになります。
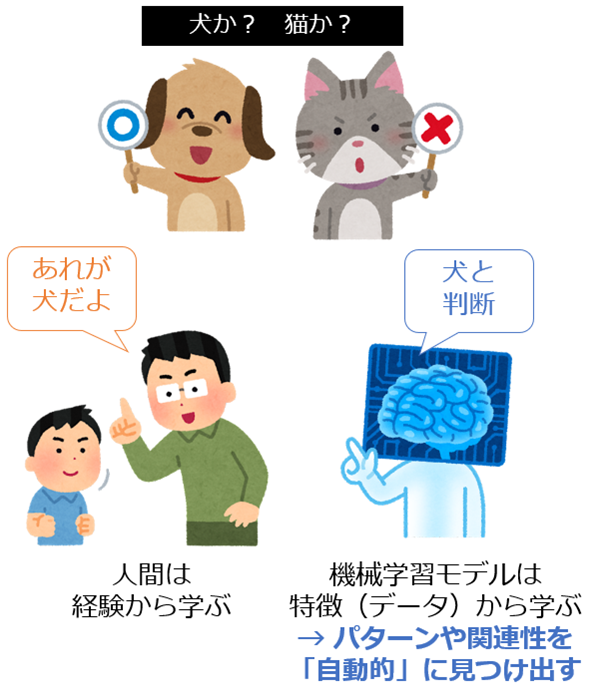 図4 機械学習は、人間が経験から学ぶことに似ている
図4 機械学習は、人間が経験から学ぶことに似ているルールベースと機械学習ベースの違い
機械学習の強みは、パターンを「自動的に」見つけ出すことです。従来のプログラミングによるソフトウェア開発とは、この点が大きく異なります。これを「車のスピードに基づく交通状況の判別(渋滞中か/通常の交通量か/すいているか)」で例えると、以下のようになります。
ルールベースのアプローチ
ルールベースでは、プログラマーがスピードを基準にしたルールを設定します。例えば「時速40km未満は“渋滞”」「時速40〜60kmは“通常の交通量”」「時速60km以上は“すいている”」といったルールを基に交通情報を判別します。
ルールは人間にも理解しやすいですが、複数のルールを組み合わせたり条件分岐させたりすると、徐々に複雑さが増していき全体を把握することが難しくなります。そうなると、ルールの設定も難しくなり、急速に増えたルールの管理は煩雑になります。このようにルールベースのアプローチは、「複雑な状況に弱い」と言えるでしょう。
機械学習ベースのアプローチ
機械学習ベースでは、プログラムが大量のデータから学習し、スピードという要素から適切な交通状況を得るためのパターンを自動的に見つけ出します。そのパターンを使って、“渋滞”“通常の交通量”“すいている”という交通状況をより正確に判別できます。
また機械学習は、スピードだけでなく時間帯や天気など、複数の要素から適切な交通状況を得るための複雑なパターンを「自動的に」見つけ出すことも得意です。このように機械学習ベースのアプローチは「複雑な状況に強い」と言えるでしょう。

では、機械学習はどのような方法でデータから学習するのでしょうか?
機械学習の学習方法
さまざまな学習方法が考案されていますが、最も代表的な学習方法に「教師あり学習」「教師なし学習」「自己教師あり学習」「強化学習」の4つがあります。それぞれ説明します。
教師あり学習
教師あり学習(Supervised Learning)は、「正解」の情報を含むデータ(ラベル付きデータ)を使って学習する方法です。例えば、賃貸物件の特徴(部屋数や最寄り駅からの距離など)から賃貸価格を予測する機械学習モデルを作成する場合、各物件の「賃貸価格」がそのデータの「ラベル」(統計学では「目的変数」とも呼ばれます)として含まれている必要があります。
同様に、犬や猫の画像を分類するモデルや、車のスピードから交通状況を予測するモデルを作成する際にも、「正解」となるラベル(「犬か/猫か」の正解情報や、「渋滞中か/通常か/すいているか」という交通量の正解情報)が必須です。教師あり学習では、このような正解ラベルを用いて、モデルが予測の正確さを向上させる方法を「学習」します。
教師あり学習は、機械学習で最も一般的な学習方法です。例えば、メールの内容からスパムか否かを判断する「スパムフィルター」や、医療画像から特定の疾患を発見する「医療診断システム」など、現実世界で広く応用されています。

教師なし学習
教師なし学習(Unsupervised Learning)は、「正解」の情報を含まないデータ(ラベルなしデータ)を使って学習する方法です。例えば、顧客の購買データから顧客群を似た傾向や興味を持つグループに自動的に分ける機械学習モデルを作成する場合、各顧客のラベルは必要ありません。
同様に、文書データから類似トピックごとにグループ化するモデルや、自動車の顧客レビューから重要な特徴(=主成分)を抽出するモデルを作成する際にも、ラベルは不要です。教師なし学習では、データ内の構造やパターン、関係性を自動的に「学習」し、「発見」します。
教師なし学習も非常に有用です。例えば、顧客を自動的にグループ化する「顧客セグメンテーション」や、取引データから不審な動きを識別して詐欺などを早期に発見する「異常検知システム」、ユーザーの購入履歴から興味を持ちそうな商品を提示する「推薦システム」など、現実世界のさまざまな分野で応用されています。

自己教師あり学習
自己教師あり学習(Self-Supervised Learning:SSL)は、ラベルなしデータからラベルを自動的に生成し、その生成されたラベルを用いて学習する方法です。例えば、ウィキペディア(Wikipedia)の文書データで幾つかの単語を自動的にマスキングし(隠し)、その単語を予測するタスク(問題)を解くように学習することで、機械学習モデルの言語理解能力を鍛えます。マスクされた単語は、教師あり学習における「ラベル」として機能します。
同様に、画像データでも一部分を隠して、その部分を予測するタスクを解くように学習することで、機械学習モデルの視覚的理解能力を鍛えます。自己教師あり学習では、こういったタスクはプレテキストタスク(疑似的なラベルが自動生成された代替のタスク)と呼ばれ、その学習は事前学習とも呼ばれます。また、大量のデータを用いて事前学習した機械学習モデルのことを基盤モデル(Foundation Model)と呼びます。
事前学習した機械学習モデルは基本的に、特定のタスク(下流タスクやターゲットタスクと呼ばれる)に対して微調整(再学習)されます。例えば、事前学習された大規模言語モデル(例:GPT-4)が、「対話」という特定のタスクを解けるように微調整されることで、チャットAI(例:ChatGPT)が作られます。
大量のラベルなしデータを活用できる自己教師あり学習は、文章生成AIや画像生成AIといった生成系AIの作成で特に有効です。この学習方法により、AI技術の発展が加速しています。

強化学習
強化学習(Reinforcement Learning:RL)は、試行錯誤を通じて最適な行動を学習する方法です。例えば、チェスや囲碁などのゲームをプレイするAI(機械学習モデル)を作成する場合、各手の「報酬」(ゲームでの勝利やポイント獲得など)に基づいて、どの手が最も有効かを学習します。強化学習では、ラベルではなく報酬や罰(=避けるべき行動に対する負の報酬)を使います。
同様に、自律走行レーシングカー(例:AWS DeepRacer)がレーストラックを最速で走行するモデルの場合、正確なコースを保持することで報酬を獲得し、コースから外れると罰(ペナルティー)を受けます。強化学習では、環境からフィードバックされる報酬や罰に基づき、目標達成に向けた最適な行動パターンを「学習」します。
強化学習は、自律的な意思決定が求められる分野で有用です。例えば自動運転車の制御から、高度なシミュレーション環境での意思決定まで、幅広い応用が期待されています。また、ChatGPTの開発では「RLHF(人間のフィードバックによる強化学習)」という手法が導入されており、AIの出力がより安全で、人間にとって有益なものとなるように人間の判断が活用されています。このように強化学習の活用場面は広がってきています。

以上、機械学習の主要な学習方法を理解しました。これらの方法が「どのような問題(タスク)を解決できるか」も既に簡単に触れていますが、あらためて「解決できること」という切り口で、より学術的にまとめます。
機械学習が解決できること
機械学習におけるタスク(task)とは、機械学習モデルによって解決したい「特定の問題」のことを指します。以下では、機械学習が解決できる主なタスクを説明します。
解決できるタスクとは
教師あり学習や教師なし学習では、回帰/分類/クラスタリング/次元削減といった代表的なタスクを解決できます。これらの用語は専門的で難しそうに見えますが、それぞれの意味は一般人でも理解できるくらい簡単なものです。以下では、これらのタスクについて簡潔に説明していきます。
なお、以下の見出しには【教師あり学習】のようにそれぞれのタスクを解決する際に使われる一般的な学習方法を明記していますが、あくまで基本的な利用ケースを示しています。他の学習方法が応用的に利用される可能性も大いにあるので注意してください。
また、【自己教師あり学習】は主に基盤モデルを作成するために、【強化学習】は主に意思決定や行動を最適化するために用いられますが、「回帰」や「分類」のように一般化されたタスク名が存在しないため、自己教師あり学習と強化学習のタスクについては説明を省略します。
【教師あり学習】回帰(数値予測)
「回帰」は難しい単語ですが、「数値予測」と言い換えれば簡単に思えますよね。より厳密に説明しておきます。
回帰(Regression)とは、与えられた入力データから「連続的な数値」を予測するタスクです。連続的な数値とは、具体的には「50,000円」や「123,345円」のように、どのような値でも取り得る実数値のことです。
例えば、賃貸物件の特徴データ(部屋数や最寄り駅からの距離など)から賃貸価格を予測する機械学習モデルは、「回帰」問題を解きます。

【教師あり学習】分類
分類(Classification)とは、与えられた入力データから「カテゴリー(=あらかじめ定義された分類)」を予測するタスクです。カテゴリーとは、例えば「ひまわり」や「チューリップ」など、それぞれを明確に区別できる分類項目のことであり、基本的にそれらの項目は離散的な数値の分類ラベル(例:ひまわり=0、チューリップ=1)によって表されます。
例えば、植物の特徴データ(色や形など)から「ひまわり」「チューリップ」といった花の種類を識別する機械学習モデルは、「分類」問題を解きます。
【教師なし学習】クラスタリング(グループ分け)
クラスタリング(Clustering)とは、与えられた入力データから各データポイントを幾つかの「グループ」に分けるタスクです。グループ分けとは、例えば「映画好き」や「旅行好き」など、類似の特徴を持つデータポイント同士を群(=クラスタ)にまとめることです。
例えば、ソーシャルメディアの投稿データ(映画、旅行、本の言及数など)から各ユーザーを「映画好き」「旅行好き」といった興味関心を持つ群にグループ化する機械学習モデルは、「クラスタリング」問題を解きます。

【教師なし学習】次元削減
次元削減(Dimensionality Reduction)とは、与えられたデータから特徴量の数(=次元数)を減らして重要な情報を圧縮/要約するタスクです。このプロセスにより、データの本質的な構造をより直感的に理解できるようになったりします。
次元削減の一般的な手法である「主成分分析(PCA)」は、データから主要な成分を抽出します。例えば高校生の国語と英語という2科目のテスト結果データから、第1主成分「文系能力」という1軸に減らして成績に関する情報を要約したりできます。これにより、各生徒の学業傾向や能力を簡潔に表現し、教育的な支援に役立てることなどが可能です。
以上、機械学習のタスク種別について説明しました。次回以降の説明がスムーズに進むように、機械学習の基本用語を幾つかピックアップして簡単に説明します。
機械学習の基本用語
機械学習モデルの入力と出力
機械学習の基本的な仕組みは、機械学習モデルにデータを入力して、結果を出力することです(図12)。

入力データと出力結果はさまざまな用語で表現されますが、多くの場合は対応する語句が決まっています(図12の矢印はその対応関係を示しています)。以下ではこれについて簡単に説明しましょう。
説明変数と目的変数
統計学/数理最適化寄りの説明では、モデルへの入力データは説明変数(もしくは独立変数)と呼ばれ、出力結果は目的変数(もしくは従属変数)と呼ばれます。特に回帰分析など伝統的に統計学の手法だったものは、これらの用語で説明されるケースが多いです。
特徴量とラベル
一方、機械学習寄りの説明では、モデルへの入力データは特徴量(features)と呼ばれ、出力結果や正解値はターゲット(target)やラベル(label)と呼ばれます。
パラメーターとハイパーパラメーター
機械学習モデルで、学習によって自動的に計算される設定項目をパラメーター(parameter)と呼びます。回帰分析では自動的に計算される「傾き」や「切片」がパラメーターです。ニューラルネットワークでは「重み」や「バイアス」がパラメーターです。
一方、学習前に人間によって指定する設定項目をハイパーパラメーター(hyperparameter)と呼びます。ニューラルネットワークでは「層の数」や「学習率」がハイパーパラメーターです。ハイパーパラメーターも、自動的に調整(チューニング)するためのツールがあります(例えば本連載で使用するscikit-learnのGridSearchCVクラスで、ハイパーパラメーターを自動的に最適化できます)。
学習と訓練
機械学習の実行プロセスは、大きく「学習」と「推論」の2ステップに分けられます。学習(learning)プロセスは、機械学習モデルを作る工程を示す概念です。推論(inference)プロセスは、学習後のモデルを実運用で使用する工程を示す概念です。
これに対し、機械学習モデルのパラメーターを最適化する具体的な作業は「訓練」(training)と表現するのが一般的です。日本語で「学習済みモデル」と表記されることがよくありますが、英語では一般的に「trained model」と書くので直訳すると「訓練済みモデル」です。日本語では「訓練」と「学習」の使い分けがあいまいになっており、本稿でももっぱら「学習」という用語を使ってきましたが、今後は学習プロセスではない機械学習モデルの最適化については「訓練」という用語を使うようにします。
その他の用語
本連載では、下記の3本の記事レベルはあらかじめ知っていることを前提としています。ここまでの説明で知らない用語があるなど不安がある場合は、次回までに以下の記事をご一読ください。
機械学習の環境を準備しよう
次回からは早速、手を動かしてPythonで機械学習をプログラミングしていきます。そのため、機械学習の実行環境について紹介しておきます。
無料のクラウドを使用する場合【誰にもお勧め】
この連載ではGoogle Colaboratory(コラボラトリー、略してコラボ。以降、本連載では「Google Colab」と表記)の使用を前提とします。毎回、サンプルコードはColabノートブックでも提供し、それを実行するだけで実習できるようにします。
Colabを使うには、GoogleアカウントとGoogleドライブが必須です。「Colaboratory へようこそ」からログインするなどして使い始めてください(図13)。インストール方法などは、使い始めようとすれば直感的に分かるので何とかなると思います。心配な方はこちらの記事を参考にしてください。

Colabの代替として、Amazon SageMaker Studio Labを利用しても構いません。
【コラム】ローカルPCを使用する場合【本格的に始めたい人にお勧め】
かつての機械学習では、Ubuntu OSをインストールしたローカルPC(やクラウド上のVM:仮想マシン)にJupyter NotebookやJupyterLabというノートブック環境をインストールして使うのが王道でしたが、今は特に学習者であればColabで手軽に済ますのが一般的です。
しかしColabには利用上の制限があるのも事実です。「ローカルPCの環境を自由に使いたい」というニーズもあるでしょう。
筆者自身も本格的に機械学習する際には、WindowsやUbuntuをインストールしたローカルPCを活用しています。ただし今は、JupyterLabなどのWebツールではなく、Visual Studio CodeのJupyter拡張を活用しています(図14)。Jupyter拡張の使い方はこちらの記事を参考にしてください。

また、ローカルPCにはPython環境をインストールする必要があります。これについては、以下の記事を参考にしてください。
「Pythonの仮想環境に何を選ぶべきか」は、本連載ではPython標準のvenv(virtualenvとも表記される)か、機械学習パッケージが多数同梱されるAnacondaというPythonディストリビューションのcondaをお勧めします。これはscikit-learnパッケージのインストール方法を説明する公式ページに、この2つのインストール方法が記載されているからです。
ローカルPCを使う場合は、Python環境を使いこなせるスキルが必要です。scikit-learnなどの各種Pythonパッケージをインストールして使いこなす必要がありますが、そういった作業は読者自身が自力で行ってください。本連載では対象外として説明を割愛します。
本稿で使用するPythonやscikit-learnライブラリのバージョンはGoogle Colabに準拠することとします。2024年12月2日時点で筆者が確認したところ、Pythonがバージョン3.10.12で、scikit-learn(sklearn)がバージョン1.5.2でした。
機械学習のライブラリを知ろう
機械学習を実践する際には、プログラミング言語やそのライブラリが不可欠です。最後に、これらについて概説しておきます。
Python言語
Pythonは、機械学習分野で最も人気のあるプログラミング言語です。その理由の一つが、科学計算やデータ分析、可視化、機械学習などに対応した豊富なライブラリが利用可能だからです。コードも比較的シンプルに記述でき、読みやすいと筆者は感じています。
NumPy
NumPyは、数値計算を効率的に行うための基本的なPythonライブラリです。行列などの多次元配列オブジェクトを高速に操作できるのが特徴で、現代の科学計算を支えています。
pandas
pandasは、表形式データや時系列データでデータ分析を行うための強力なPythonライブラリです。データを「データフレーム」と呼ばれるオブジェクトで管理するのが特徴で、データの前処理を行うのに便利です。
Matplotlib
Matplotlibは、グラフを描画するための基本的なPythonライブラリです。スタティックな図から、アニメーション、インタラクティブな可視化まで、可視化に関する豊富な機能を提供します。
seaborn
seabornは、高度な統計グラフィックに強い、MatplotlibベースのPythonライブラリです。より美しいグラフを作成できるだけでなく、より複雑なデータも可視化できます。
scikit-learn
scikit-learnは、機械学習を行うためのPythonライブラリです。本稿で紹介した、回帰/分類/クラスタリング/次元削減などのタスクに対応した、さまざまな機械学習アルゴリズムが実装されています。
APIは非常に簡単に利用でき、公式ドキュメントも英語ですが充実しています。機械学習の入門から実践的なアプリケーション開発にまで幅広く採用されています。
実行環境のバージョンチェック
Pythonや各ライブラリのバージョンによって、Pythonコードの挙動が異なる可能性があります。そのため、サンプルノートブック作成時の実行環境と一致させられるよう、本連載で提供する全てのサンプルノートブックではバージョン情報を出力しています。具体的にはリスト1のようなコードが各ノートブックの冒頭に記載されており、このコードを実行すると、リスト2のような結果が出力されます。
from datetime import datetime
import platform
import numpy as np
import pandas as pd
import matplotlib
import seaborn as sns
import sklearn
print(f'実行日: {datetime.now():%Y年%m月%d日}')
print(f'Python version: {platform.python_version()}')
print(f'NumPy version: {np.version.version}')
print(f'pandas version: {pd.__version__}')
print(f'matplotlib version: {matplotlib.__version__}')
print(f'seaborn version: {sns.__version__}')
print(f'scikit-learn version: {sklearn.__version__}')
実行日: 2024年12月02日
Python version: 3.10.12
NumPy version: 1.26.4
pandas version: 2.2.2
matplotlib version: 3.8.0
seaborn version: 0.13.2
scikit-learn version: 1.5.2
【コラム】その他のプログラミング言語「R」「Julia」について
R言語は、統計解析と可視化に強いプログラミング言語です。機械学習を含むデータ分析に広く使用されおり、Pythonの次に人気があります。
Juliaは、高性能で高レベルな数値計算を実現するために設計されたプログラミング言語です。機械学習や科学計算の分野で注目されています。
駆け足で機械学習の基本を紹介しましたが、それなりのボリュームでしたね。付いてこれたでしょうか? 余裕があれば、末尾の実力試しもやってみてください。
前提知識に不安があると感じる人は、以下の3つの連載も並行して読むことで、本連載の内容もより理解しやすくなると思います。
次回は、「習うより慣れろ」ということで、scikit-learnでプログラミングしてみます。データを読み込んで操作し、グラフ化します。お楽しみに。
実力試しクイズ
オレンジ色の部分をクリックまたはタップすると答えが表示されます。ヒントが欲しい場合は、緑色の部分をクリックしてください。穴埋め問題に使える選択肢が表示されます。
問題
機械学習は、コンピュータプログラム(機械)がデータから学習し、パターンや関連性を自動的に見つけ出す技術です。これにより、新しいデータに対して予測や判断が可能になります。このプロセスは人間が経験から学ぶ過程に似ており、例えば、人間の子供は犬や猫を見て覚えることで、犬か猫かを区別できるようになります。同様に機械学習も、データから犬や猫の特徴を学ぶことで、犬か猫かを判別できるようになります。
教師あり学習では、「正解」の情報を含むデータ(ラベル付きデータ)を使って学習します。この方法は、例えばメールの内容からスパムか否かを判断する「スパムフィルター」や、医療画像から特定の疾患を発見する「医療診断システム」など、現実世界で広く応用されています。
回帰は、「数値予測」タスクです。与えられた入力データから「連続的な数値」を予測することが目的です。例えば、家の広さや立地などの特徴から家の価格を予測するなどがその一例です。
クラスタリングは、与えられた入力データから各データポイントを幾つかの「グループ」に分けるタスクであり、この方法で例えば「映画好き」や「旅行好き」などのグループに分類できます。
次元削減は、特徴量の数を減らして重要な情報を圧縮するタスクであり、「主成分分析(PCA)」がその一般的な手法です。これにより、データの本質的な構造をより直感的に理解できるようになります。
ヒント: ラベル データフレーム 機械学習 強化学習 離散的 クラスタリング ランダムフォレスト 次元削減 ニューラルネットワーク モデル 自己教師あり学習 データ 連続的 スパース性 グリッドサーチ 回帰 パターンや関連性 バイアス 教師あり学習 予測や判断
「機械学習入門」
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。