「自称“Python祭り”について」と「飛行機内でもAIプログラミングしたい」:Deep Insider's Eye 一色&かわさきの編集後記
かわさきからは「自称“Python祭り”について」というタイトルでPython 3.14の新機能を紹介する連載記事の紹介と紹介しきれなかったトピックについて、一色からは「飛行機内でもAIプログラミングしたい」というタイトルで、16GBメモリのMacBook Pro(M4)上でVS CodeとローカルLLMを使ってプログラミングを試した体験とその感想について書きました。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
@ITのDeep Insiderフォーラム【AI・データサイエンスの学びをここから】を担当しているDeep Insider編集部の一色とかわさきです。7月末に公開した前回の編集後記から、もう3カ月がたちました。最近は記事内に筆者コメントを添える機会も増えてきたので、「久しぶり」という感じはあまりしませんね。
編集者が記す“あとがき”であるこの編集後記では、執筆や編集の裏側で感じたこと、記事では書ききれなかった小話や裏話、そして読者の皆さんにもぜひ知ってほしい話などをつづっています。
自称“Python祭り”について(かわさき)
かわさきしんじ
 かわさきしんじ
かわさきしんじ大学生時代にIT系出版社でアルバイトを始めて、そのまま就職という典型的なコースをたどったダメ人間。退職しても何か他のことをできるでもなくそのままフリーランスの編集者にジョブチェンジ。そしてDeep Insider編集部に拾ってもらう。お酒とおつまみが大好き。通称「食ってみおじさん」。最近はすっかり「ダイエットおじさん」に変貌したのでした。
今年の夏は長かったですねぇ。というか、秋が短すぎる気がします。「着るのはまだちょっと先かな」と思いながら買ったフリースが役立つ日がポツポツとある今日この頃ですが、皆さん、いかがお過ごしでしょうか。ぼくは元気です。ダイエットはアレです。ちょっと体重増やしてからまた減らそうと思い、66kgまで増やしたところです。
体重が増えたのはよしとします。でも、そのときには体脂肪率はなるべく上げないようにと考えていたのに、なかなかそうはいかず、「筋肉よりも脂肪の増加量の方が多い」疑惑が頭の中に広がっているところです(秋だからしょうがないっす)。というわけで、11月に入ったら再び減量の方向に切り替えて4kgくらい落とす予定です。落とせるといいなぁ。
筆者が担当している記事でもちょこちょこと書いていますが、M4 Mac miniを購入しました。Amazonで何かのセールをやっていたタイミングで15万円ちょっとの定価から13%オフということで約13万円。「これなら買うでしょ!」と飛びついてしまったのです。が、ここのところの自称“Python祭り”のおかげでなかなかセットアップの時間が取れなくて、開封の儀こそ済ませましたが、お姿を拝見しただけで、まだそのまま箱の中で寝てもらっています。
単に電源を入れて、アカウントの設定だけやればOK! とはいかないのがメンドウなんですよね。PhotoshopやMorisawa Fonts(モリサワのフォントサブスクリプション)なんかを新しい環境に移行したり、アプリ以外のローカルに持っているデータを移行したり、Windows 11 on ARMをインストールしたり、何だりかんだりとやらなきゃいけないことをここに書くだけでどんどんテンションが下がってきました……(Time Machineは使っていないんです。ダメ人間だから)。とはいえ、いつまでもIntel Mac miniを使い続けるわけにもいきませんからねぇ(macOS Tahoeも入れられないし)。

Windowsと比べると、Macは「移行アシスタント」で楽チンなイメージがあったのですが、そうでもないのでしょうか? 私はいつも移行アシスタントだけで済ませていますが、まぁThunderbirdというメールソフトと、Chromeと、Visual Studio Codeくらいしか主に使っていないので、そもそも移行するものが少ないんですよね。
移行アシスタント! そんなのあったかもしれません。何せ久々の移行なので。調べて試してみます。ありがとん。
ということで、近いうちにM4 Mac miniで原稿を書いたり、編集作業をしたり、Pythonを動かしたりする日がくるはずです。次回の編集後記では「M4サイコー」などと語っているハズです。知らんけど。
でもって、自称“Python祭り”ですが、今のところ、次のような記事を公開しています。
どれが一番読まれているかといえば、ズバリ「Python Install Manager」の記事です。Pythonを(Windows環境に)インストールする方法は色々とありますが、その競争に拍車を掛ける(それとも、冷や水をぶっかける?)かのようなPSF自身のこの動きがなかなか興味深いですね。筆者は「Windowsにはインストーラーを使ってPythonをインストールしているし、仮想環境はvenvを使って作成しているし、拡張モジュールのインストールにはpipを使っているし」といわば「全く成長していない」系の人間です。が、使い慣れているpyコマンドで古いバージョンから最新バージョンまでのPythonをインストール/アンインストールできるのが気に入りました。当面はこいつを使ってみようかなと考えています。
そして、concurrent.interpretersモジュールについて、ちょっと落ち穂拾いもしておきましょう。上記の記事ではInterpreter.call_in_threadメソッドを使って、新規スレッドでInterpretersオブジェクトに関数を実行させるコードは示しました。でも、スレッドを主体として、何かのコード(Interpreterオブジェクトを内部に持つ関数)を実行させる方法については話をしていませんでした。「ナニいってんの?」となる人もいるでしょうから、どんなコードになるのかをお見せしましょう。
from threading import Thread
from concurrent.interpreters import create, list_all
from time import time
def func0(msg):
interp = create()
interp.prepare_main(msg=msg)
code = '''from concurrent.interpreters import get_current
from time import thread_time
cur = get_current()
print(f'{cur} start')
tmp = 0
st = thread_time()
while thread_time() - st < 10: # 単に10秒間CPUに仕事させるだけ
tmp += 1
print(f'{msg} from {cur}')
'''
interp.exec(code)
msgs = ['hello', 'goodbye', 'good night']
threads = [Thread(target=func0, args=(m,)) for m in msgs]
st = time()
for t in threads:
t.start()
for t in threads:
t.join()
ed = time()
print(f'{ed - st}')
for interp in list_all()[1:]:
interp.close()
func0関数はその内部でInterpreterオブジェクトを作成して、そのexecメソッドで10秒間仕事をするようになっています。これをthreading.Threadオブジェクトに渡して、並列処理をしてみようということです。複数のThreadオブジェクトがこのコードを実行すると、それぞれにInterpreterオブジェクトを作成するので、GILもThreadオブジェクトごとに存在し、その結果、フリースレッドモードではないPythonでもCPUコアを存分に使えるというわけです。
手元のpython3.14コマンド(フリースレッド版ではない方)でこれを実行すると、以下のような結果になりました。

上のコードではスレッドを3つ用意して、スレッドごとに10秒の仕事をさせてからメッセージを表示させています。でも、スレッドごとにGILがあるので、全体では10秒ともう少しの時間で処理が完了しています。
比較用に以下のコードを書いてみました。
from threading import Thread
from time import time
def func1(msg, n):
code = '''from time import thread_time
print(f'thread #{n} start')
tmp = 0
st = thread_time()
while thread_time() - st < 10: # 単に10秒間CPUに仕事させるだけ
tmp += 1
print(f'{msg} from thread #{n}')
'''
exec(code)
msgs = ['hello', 'goodbye', 'good night']
threads = [Thread(target=func1, args=(m, n)) for n, m in enumerate(msgs)]
st = time()
for t in threads:
t.start()
for t in threads:
t.join()
ed = time()
print(f'{ed - st}')
手元のpython3.14コマンドでこのコードを実行すると、実行が完了するまでに30秒強の時間がかかりました(当たり前)。一方、フリースレッド版のpython3.14tコマンドでは10秒強で実行が完了しました。
というわけで、スレッドごとにInterpreterオブジェクトを持たせるようなコードの書き方は、フリースレッド版Pythonが広く使われるようになるまでの過渡的なものになるんじゃないかな? とも思うので無理にこうしたコードを書く必要はないでしょうが、知っておくと何かの役に立つかもしれません。対して、Interpreterオブジェクトのcall_in_threadメソッドを使う書き方はフリースレッド版Pythonが普及した後でも、一定程度の使い道がありそうです(何となく。なので追求はしないでくださいね)。
どうでもいいことを長々と書いてしまいました。すみません。サガなんです。
Pythonの大きめのバージョン更新(例えば「3.14」→「3.15」のようなマイナーバージョンアップ)は、年に1回だとかわさきさんに聞きました。今年の更新は内部機構に関わる変更が多く、やや地味な印象でした。とはいえ、かわさきさんが続々と公開中の記事では、まだ全ての機能が紹介されていないので、今後の回でもっと面白い新機能が登場するのかもしれませんが……。来年は、もう少し“目に見えて便利な”新機能やモジュールの追加があるとうれしいですね。
REPLで構文が色分けされるようになったじゃないですかー。見た目に分かりやすい大変化ですよ(笑)。でも、個人的にはテンプレート文字列や並列処理系の機能追加など、実は大きく変わりつつあるなと感じました。
飛行機内でもAIプログラミングしたい(一色)
一色政彦(いっしきまさひこ)
@ITのDeep Insider編集部の編集長です。前回の編集後記の自己紹介で書いた通り、夏休みには長崎・五島列島を訪れ、『劇映画 孤独のグルメ』のロケ地を巡ってきました。中でも印象的だったのは「みかんや食堂」のちゃんぽん。福岡出身の私には懐かしい味で、心がほっとしました。
五島といえばお魚。「四季の味 奴(やっこ)」で名物のハコフグ味噌焼きを楽しみました。よく混ぜて食べる漁師飯なのですが、戸惑っていると地元の方が声をかけてくれ、お薦めのお酒を少し分けてもらったりして、すっかり打ち解けました。その後はご主人とも会話が弾み、地元のバラモン焼酎(芋と麦)を知りました。閉店間際まで楽しく過ごせた、忘れられない夜です。
後日、その焼酎を求めて「リカーズマルヒサ」を訪ねました。酒屋なのに、店内には「バラモン」という地元の凧がたくさん飾られており、店主からその制作の話を伺うことができました。朝ドラ『舞いあがれ!』にも使われたそうです。五島の人たちは本当に温かく、気さくに話しかけてくれます。地元の人との交流を楽しみたい方には、五島の旅をお勧めします。今は、最高においしいクラフトジン「GOTOJIN(ゴトジン)」をチビチビ飲みながら、楽しかった旅を思い出しています。
旅と食と酒! いいですねぇ。旅したい。湯豆腐食べたい(笑)!
1月の編集後記で紹介したロングセラー本から、「(90歳になって資産が人生最高額になるよりも)今しかできないことに適度にお金を使い、思い出を作ることが人生を豊かにする」というメッセージを紹介しました。旅と食と酒はまさに、それを体現できる行為だと思います。
自己紹介に書いた通り、東京から五島に行きました。当然、飛行機に乗ったのですが、その時ふと「そうだ、プログラミングしよう」と思い立ちました。ところが、もはやAIなしではプログラミングできなくなっていたのです(苦笑)。
そんな身体になってしまうとは……。ボクもです。
機内(ネット接続なし)でプログラミングするとなると、使えるのはローカルLLMしかありません。というわけで、今回はそのあたりを調べたり試したりした話を披露します。
私もこれまで、OllamaやLM StudioといったツールでローカルLLMを“遊び程度”に試してきました。ただ、クラウド上のChatGPTやGeminiと比べると、量子化によって軽量化されている分、どうしても“頭が悪い”印象があり、積極的に使う気にはなれませんでした。とはいえ、今回は必要に迫られて本格利用を始めてみた、というわけです。
まず、OllamaをノートPCにダウンロードしてインストールします。
インストール自体は簡単です。編集後記なので詳しい説明は割愛します。
次に、Ollamaを使って利用したいローカルLLMをダウンロードします。これには、ターミナルで以下のようにコマンドを入力します。
ollama pull deepseek-r1:7b
ollama pull gemma3:4b
私の場合は、「DeepSeek-R1」モデルの7B(=約70億のパラメーター)版と、Google製の「Gemma 3」モデルの4B版をダウンロードしました。いずれも「Q4_K_M」という量子化の形式で、精度を少し落としてメモリ使用量を減らすタイプです。
ちなみに、日頃持ち歩いているノートPCは、メモリ16GBのMacBook Pro(M4)です。M4は、システムメモリ(RAM)とGPUメモリ(VRAM)を共有する“ユニファイドメモリ”という仕組みを採用しています。これにより、CPUとGPUが同じ16GBのメモリ領域を柔軟に使い合うことができます。実際には、GPU側に割り当てられる容量は8GB前後と考えられるため、ローカルLLMで使えるモデルは「7B(70億パラメーター)以下」が現実的です(※OS情報の取得とLLM実行要件を検証するために筆者が自作したPythonスクリプトによる推定)。そのため、今回は上記の2つのモデルを選びました。
MacBook Pro(M4)なら、さまざまなローカルLLMが動くのではと勝手に期待していたのですが、意外と動かせるモデルは少なそうです……。正直、ちょっとへこみました(泣)。どうもメモリ16GBでLLMを動かすのは厳しいみたいですね。これから購入を検討されている方は、できれば32GB以上をお勧めします。
以上で、ローカルLLMを使う環境が整いました。私の開発環境はVisual Studio Code(以下、VS Code)で、コーディング支援にはGitHub CopilotのPro(有償のベーシックプラン)を利用しています。この調査を始めて気づいたのですが、この組み合わせで意外にも簡単に、OllamaのローカルLLMを使えるのです。
具体的には、VS Code上部のチャットアイコンをクリックし、右側にチャット領域を表示します。プロンプト入力欄の下部にあるモデル選択部分から[モデルの管理]を選択すると、上部に[モデルプロバイダー]のリストが表示されるので、ここで「Ollama」を選びます。すると、ローカルにインストール済みのモデル一覧が表示されるので、使用したいものにチェックを入れて[OK]ボタンをクリックするだけです。
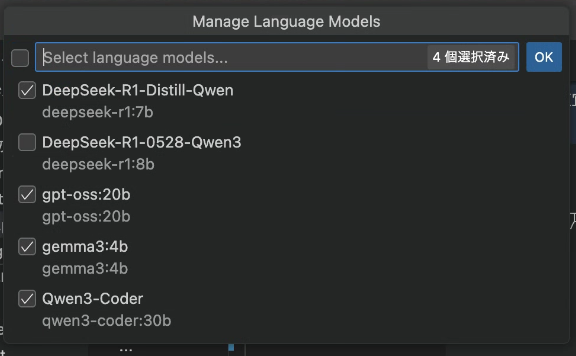 VS Code+GitHub Copilotで「Ollama」のローカルLLMを使えるようにする設定
VS Code+GitHub Copilotで「Ollama」のローカルLLMを使えるようにする設定これだけの手順で、VS Code上のGitHub CopilotでローカルLLMが使えるようになります。あとは普段通りに、プロンプト入力欄の下部にあるモデル選択部分で、使いたいモデルを選ぶだけです。
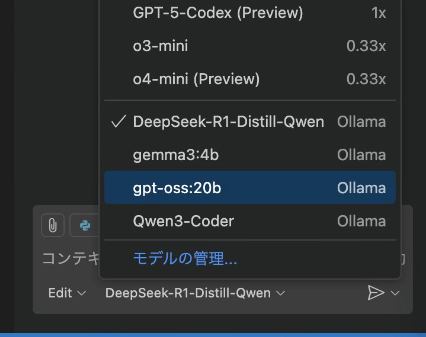 VS Code+GitHub Copilotで「Ollama」のローカルLLMを実際に選択して使用しようとしているところ
VS Code+GitHub Copilotで「Ollama」のローカルLLMを実際に選択して使用しようとしているところ――これで「めでたし、めでたし」とはいきませんでした……。VS Code+GitHub Copilotには「Ask(質問)」「Edit(編集)」「Agent(エージェント)」の3つのモードがあります。このうち、AskモードとEditモードでは、私が選択したローカルLLMを問題なく利用できました。しかし、Agentモードでは候補に出てこず、選択することすらできませんでした。
Agentモードで使用できるモデルの基準は明確ではありませんが、恐らく「ツールやコマンドを扱う能力があるかどうか」が必須条件になっているようです。この“ツール使用能力”を持つモデルは、Ollamaのモデルライブラリで「tools」タグが付いているものとして確認できます。
実際、OpenAI製「gpt-oss」モデルの20B版や「Qwen3-Coder」モデルの30B版は、このツール使用能力を備えており、Agentモードの候補としてリストアップされました。ただし、いずれもモデルサイズが大きすぎて、私のMacBook環境では実行がかなり厳しいんですよね……(泣)。
さらに調べてみると、「Qwen3」モデルの4B版にも「tools」タグが付いており、こちらは取りあえず動作しました。とはいえ、実際に使ってみると動作は遅く、推論の精度もかなり低く、“頭が悪い”印象。正直、「実用レベルには達していない」と感じました。
レスポンスが悪いと、コーディングしていて気分よくないですもんね。
さらに、推定していた「7B」でもモデルサイズが大きすぎるようです。「4B」にまで落とすと、ようやく許容できるスピードになりました。7B以上も動かせなくはありませんが、あまりに遅すぎて実用には耐えません……(苦笑)。
最終結論。MacBook Pro(M4)程度では、ローカルLLMによるAIコーディングはまだまだ「実用的」とは言いがたい……というのが正直な感想です(泣)。メモリを16GBから32GBや、M4 Maxの128GBに増やせば、もしかしたらこの印象は変わるのかもしれません。もちろん、感じ方は人それぞれだと思いますので、ぜひご自身の環境でも試して評価してみてください。
とはいえ、「4B」クラスのモデルであれば、全てのモードが基本的には動作することが分かりました(※「目的が達成できる」とは言っていません)。次に飛行機に乗るときは、これを使って本格的に“機上プログラミング”に挑戦してみようと思います。
ちなみに、「Continue」というVS Code拡張機能でも、ローカルLLMによるAIコーディングを実現できるので試してみましたが、上記の体験と大きな違いはありませんでした。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。