文字化けに関するトラブルに強くなる【実践編】:Oracleトラブル対策の基礎知識(6)(1/4 ページ)
今回は、前回(文字化けに関するトラブルに強くなる【基礎編】)に引き続きOracleの「文字化け」について説明します。前回で説明したOracleの文字コード処理の説明を踏まえて、「〜」(チルダ)の文字化けに代表されるJavaなどのUnicodeベースのアプリケーションで発生する問題と、Windows Vistaの登場によって現在問題となりつつあるJIS X 0213の問題について説明します。
「〜」の文字化け
連載バックナンバー
主な内容
- JavaベースのWebアプリケーションにおける「〜」の文字化け
- JavaベースのWebアプリケーションのシステム構成と変換表
- 「〜」文字化けのメカニズム
- JA16SJISTILDE・JA16EUCTILDEによる対処
- Vistaが新たに対応したJIS X 0213とは?
- Oracle DatabaseでJIS X 0213に対応するには
- JIS X 0213とクライアント環境
- 補助文字(追加文字)とサロゲートペア
(関連キーワード:文字化け、SJIS16TILDE、チルダ文字、サロゲートペア、補助文字(追加文字)
WindowsやJavaなどのように、OSやプログラミング言語の内部処理では、文字データをUnicodeで扱うことが一般的になってきています。Unicodeの目的の1つは、同一のプログラムで複数言語に対応することですから、これは想定された望ましい流れです。
しかし、過去の経緯から、Unicode以前に存在したシフトJIS、日本語EUCといったUnicode以外の文字コードで文字データを格納したり、各種の処理を実行する必要は依然として残っています。このため、UnicodeとシフトJIS、日本語EUCなどとの相互変換が必要となりますが、それぞれのソフトウェアにおける変換処理の違いによって文字化けが発生する可能性があります。
Oracleを用いたシステムにおいて、変換処理の違いによって生じる最も代表的な文字化け事例がJavaベースのWebアプリケーションにおける「〜」の文字化けです。本章ではこの事例を題材に、UnicodeとUnicode以前の文字コードの相互変換にまつわる問題について説明します。
JavaベースのWebアプリケーションにおける「〜」の文字化け
本稿では、図1に示すシステム構成のとおり、JavaのベースのWebアプリケーションを想定し、このシステムにおける「〜」の文字化けについて説明します。
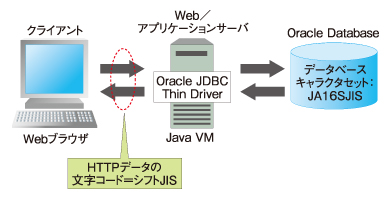 図1 JavaベースWebアプリケーションの典型的なシステム構成
図1 JavaベースWebアプリケーションの典型的なシステム構成図1に示したシステムの文字データの扱いにおけるポイントは以下のとおりです。
- クライアントのWebブラウザとWeb/APサーバ間のHTTPデータの文字コードは、WindowsのシフトJISとする
- OracleとはOracle JDBC Thin Driverで接続する
- OracleのデータベースキャラクタセットはJA16SJISとする
このような構成のシステムにおいて、「〜」文字をWebブラウザからデータベースに格納して参照すると、表示された文字が「?」になる文字化けが発生します。
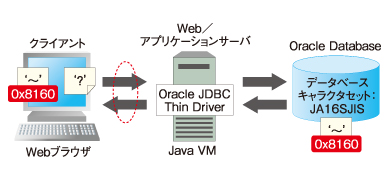 図2 「〜」文字の文字化け
図2 「〜」文字の文字化けここで文字化けする「〜」はJIS X 0208に含まれている文字で、いわゆる機種依存文字でもありません。
なお、「〜」はシフトJISでは0x8160となります。一般には機種依存文字ではないJIS X 0208に含まれている文字は文字化けの可能性が低いといわれていますが、なぜこのような文字化けが発生するのでしょうか。
ここで発生した文字化けを理解するためには、前回説明したOracleの文字コード変換のみならず、Javaにおける文字コード変換を含めて理解する必要があります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。