Bツリーインデックスに最高のパフォーマンスを:Oracleパフォーマンス障害の克服(3)(1/4 ページ)
Oracleデータベースの運用管理者は、突発的に直面するパフォーマンス障害にどうやって対処したらよいか。本連載は、非常に複雑なOracleのアーキテクチャに頭を悩ます管理者に向け、短時間で問題を切り分け、対処法を見つけるノウハウを紹介する。対象とするバージョンはOracle8から9iまでを基本とし、10gの情報は随時加えていく。(編集局)
SQL処理(インデックス)にかかわる確認
前回「ロックをつぶせ!最初に疑うべき原因」では、SQLにかかわる問題の解決方法としてロックの確認方法を説明しました。データ更新には必ずオブジェクトの処理が行われていることを理解できたと思います。
SQL文をきっかけに更新されるOracleサーバ内のオブジェクトとして、今回はインデックスを取り上げます。SQL文発行時、直接データとのかかわりを意識しづらいオブジェクトなので、データの更新頻度やインデックスの作り方によっては、Oracleサーバの問題の原因になっていても気付かないこともあります。そこでまず、インデックスの特徴を確認してみましょう。本稿で取り上げるのは少々基本的な内容になりますが、インデックスの問題を正しく理解するためには重要です。
インデックスの問題を切り分ける
データ検索には欠かせないインデックスですが、Oracleサーバがデータ検索を行う方法は理解できているでしょうか。インデックスの特徴を理解する前にデータベースサーバの動きを確認して、インデックスの種類の確認をしていきます。
| データ検索の方法 | 動作 |
|---|---|
| フルスキャン | データベースに格納されているデータのすべての行を取得する。検索している途中で条件に一致しても、最後まで検索し、その中から対象となるデータを抽出する |
| インデックススキャン | インデックスを読み取り、検索条件に一致したデータが格納されている場所に関するID(データベーステーブルのROWID 注1 )を取得し、ROWIDを基に対象となるデータベーステーブルからデータを取得する |
| 表1 Oracleデータベースサーバのデータ検索方法 | |
注1:ROWID
ファイル番号、ブロック番号、行番号によりデータ行の物理的な位置を示す。
フルスキャンで検索が行われると当然すべてのデータを検証するため、大量のデータがテーブルに格納されていると検索に時間がかかります。この検索パフォーマンスを向上させるために、インデックススキャンを使用します。しかし、インデックススキャンでは、実際のデータを取得するためにテーブルオブジェクトとは異なる領域(インデックス領域)にアクセスし、そのデータを読み出すため、実際のテーブル検索とは別に処理時間やI/Oが発生することを理解すべきです。
インデックスの種類を確認していきましょう。
インデックスの種類
Oracleデータベースサーバで使用できるインデックスは以下になります。
| インデックスの種類 | 特徴 |
|---|---|
| Bツリーインデックス | ルート、ブランチ、リーフのツリー構造上に索引エントリをキー値データから作成し、キー値データおよびROWIDを格納する |
| 索引エントリのルートよりデータの種類ごとに選択を行うため、データの種類が多い(カーディナリティが高い)列をキーにした検索に有効 | |
| キー値データの更新時には、キー値データとROWIDを格納するのでインデックス更新が容易 | |
| ビットマップインデックス | 索引エントリをキー値データから作成したビットデータとし、ビットデータのみを格納する |
| ビット演算を使ったデータ整合による選択を行うため、データの種類が少ない(カーディナリティが低い)列をキーにした検索に有効 | |
| キー値データの更新時にはその都度、キー値データからビットデータを作成するため頻繁に更新されるデータには向かない | |
| 逆キーインデックス | キー値データを逆順に並べ替え格納する |
| 連番など数値データが格納される際、生成されたデータを昇順に挿入すると同じ索引エントリブロックに更新が集中するため、I/Oボトルネックが発生するが、キー値データを逆順にすることにより更新する索引エントリブロックをインデックス領域全体に分散させられる | |
| ファンクションインデックス | 関数や演算子を利用した式の結果を格納する |
| SQL文のWHERE句に関数などの式を含んだ検索で、フルスキャンではなくインデックススキャンが利用可能となり、行ごとに計算結果を評価する必要がなくなるためパフォーマンスが向上する | |
| 表2 インデックスの種類とその特徴 | |
データの構成は使用用途によって有効なインデックスが用意されていますが、一般的に作成されているBツリーインデックスは木構造(ツリー)にキー値となるデータを格納していきます。ビットマップインデックスはキー値となるデータをビットによって表現し、メモリを効率的に使用することが可能です。そのほかにもOracleには複数のインデックスの種類がありますが、今回はインデックスとして最も一般的に使われているBツリーインデックスについて考えていきましょう。
Bツリーインデックスの構造
Bツリーインデックスは図1のような「ルートノード」「ブランチノード」「リーフノード」に分かれた構造をしています。インデックスというその名前から分かるように、キー値データを昇順にリーフノードに格納していきます。さらにリーフノードの上層にリーフノード内のデータ位置を示すデータブロックアドレス(DBA)で、リーフノードデータ値の範囲を格納しています。さらに上層のルートノードには各リーフノード内のデータブロックを格納しデータ位置を示しています。
インデックスを作成したテーブルにデータを挿入したイメージを確認してください。テーブルデータの行自体を識別するROWIDにより、その行を特定できます。従って、インデックスにはこのROWIDを格納し、このROWIDを基に実際のテーブル行を特定してデータを取得することになります。
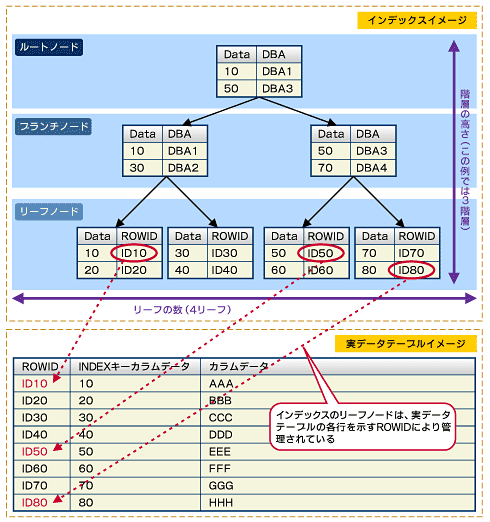 図1 Bツリーインデックスの構造
図1 Bツリーインデックスの構造この図1のツリー構造をデータディクショナリビューにて確認してみましょう。
INDEX_STATS
SQL> DESC INDEX_STATS
INDEX_STATSデータディクショナリビューの取得コマンド
(内容の抜粋は下記の表3参照)
| 列名 | データ型 | 格納されているデータの内容 |
|---|---|---|
| HEIGHT | NUMBER | Bツリーの階層の高さ(階層数) |
| BLOCKS | NUMBER | 現在インデックスに割り当てられている全ブロック数 |
| NAME | VARCHAR2(30) | インデックス名 |
| LF_ROWS | NUMBER | 各リーフ内に保持されている行数 |
| LF_BLKS | NUMBER | 各リーフブロック数 |
| LF_ROWS_LEN | NUMBER | 各リーフ行の長さの合計 |
| LF_BLK_LEN | NUMBER | リーフブロック内の使用可能領域 |
| BR_ROWS | NUMBER | 各ブランチ内に保持されている行数 |
| BR _BLKS | NUMBER | 各ブランチブロック数 |
| BR _ROWS_LEN | NUMBER | 各ブランチ行の長さの合計 |
| BR _BLK_LEN | NUMBER | ブランチブロック内の使用可能領域 |
| DEL_LF_ROWS | NUMBER | 削除されたリーフ行の数 |
| DEL_LF_ROWS_LEN | NUMBER | 削除された行の長さの合計 |
| USED_SPACE | NUMBER | 使用されている領域 |
| PCT_USED | NUMBER | 使用されている領域の割合 |
| 表3 INDEX_STATSデータディクショナリビュー(抜粋) | ||
情報取得SQL文
SQL> SELECT NAME AS インデックス名, BLOCKS AS ブロック数,
LF_ROWS AS リーフ行数, LF_BLKS AS リーフブロック数,
BR_BLKS AS ブランチのブロック数
FROM INDEX_STATS;
このSQL文では作成されたインデックスの現在割り当てられている全ブロック数とリーフ内に保持されているデータ行数、各リーフのブロック数、ブランチのブロック数が確認できます。これを使って、現在のインデックスがどのくらいのブロックを占有し、リーフとブロックでどのくらいブロックを使用しているか確認します。(次ページへ続く)
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。