フェイルオーバーの仕組みと問題点:Linuxクラスタリングへの招待(2)
いままで、フェイルオーバークラスタシステムはUNIXやWindows NT/2000の独壇場でしたが、2000年あたりからLinuxフェイルオーバークラスタソフトを各ベンダが出荷し始めました。さて、Linuxのフェイルオーバークラスタはどのように実現されているのでしょうか?
前回は、一口にクラスタシステムといってもフェイルオーバークラスタ、負荷分散クラスタ、HPC(High Performance Computing)クラスタなど、さまざまなクラスタシステムがあるという話でした。そして、「フェイルオーバークラスタ」はHA(High Availability)クラスタの一種で、サーバそのものを多重化することで、障害発生時に実行していた業務をほかのサーバで引き継ぐことにより業務の可用性(Availability)を向上することを目的としたクラスタシステムでした。
今回はNECのCLUSTERPROを例に、Linuxクラスタの実装やLinuxの問題点などについて書きたいと思います。
障害検出のメカニズム
クラスタソフトウェアは、業務継続に問題をきたす障害を検出すると業務の引き継ぎ(フェイルオーバー)を実行します。フェイルオーバー処理の具体的な内容に入る前に、簡単にクラスタソフトウェアがどのように障害を検出するか見ておきましょう。
ハートビートとサーバの障害検出
クラスタシステムにおいて、検出すべき最も基本的な障害はサーバ全体が停止してしまうものです。サーバの障害には、電源異常やメモリエラーなどのハードウェア障害やOSのパニックなどが含まれます。このような障害を検出するために、サーバの死活監視としてハートビートが使用されます。
ハートビートは、pingの応答を確認するような死活監視だけでもよいのですが、クラスタソフトウェアによっては、自サーバの状態情報などを相乗りさせて送るものもあります。クラスタソフトウェアはハートビートの送受信を行い、ハートビートの応答がない場合はそのサーバの障害とみなしてフェイルオーバー処理を開始します。ただし、サーバの高負荷などによりハートビートの送受信が遅延することも考慮し、サーバ障害と判断するまである程度の猶予時間が必要です。このため、実際に障害が発生した時間とクラスタソフトウェアが障害を検知する時間とにはタイムラグが生じます。
リソースの障害検出
業務の停止要因はサーバ全体の停止だけではありません。例えば、業務アプリケーションが使用するディスク装置やNICの障害、もしくは業務アプリケーションそのものの障害などによっても業務は停止してしまいます。可用性を向上するためには、このようなリソースの障害も検出してフェイルオーバーを実行しなければなりません。
リソース異常を検出する手法として、監視対象リソースが物理的なデバイスの場合は、実際にアクセスしてみるという方法が取られます。アプリケーションの監視では、アプリケーションプロセスそのものの死活監視のほか、業務に影響のない範囲でサービスポートを叩いてみるような手段も考えられます。
共有ディスクタイプの諸問題
共有ディスクタイプのフェイルオーバークラスタでは、複数のサーバでディスク装置を物理的に共有します。一般的に、ファイルシステムはサーバ内にデータのキャッシュを保持することで、ディスク装置の物理的なI/O性能の限界を超えるファイルI/O性能を引き出しています。
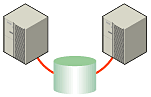 図1 共有ディスクタイプのクラスタ構成
図1 共有ディスクタイプのクラスタ構成あるファイルシステムを複数のサーバから同時にマウントしてアクセスするとどうなるでしょうか?
通常のファイルシステムは、自分以外のサーバがディスク上のデータを更新するとは考えていないので、キャッシュとディスク上のデータとに矛盾を抱えることとなり、最終的にはデータを破壊します。フェイルオーバークラスタシステムでは、次のネットワークパーティション問題などによる複数サーバからのファイルシステムの同時マウントを防ぐために、ディスク装置の排他制御を行っています。
ネットワークパーティション問題(Split-brain-syndrome)
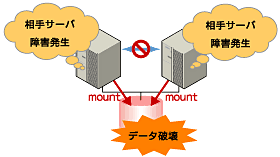 図2 ネットワークパーティション問題
図2 ネットワークパーティション問題サーバ間をつなぐすべてのインターコネクトが切断されると、ハートビートによる死活監視で互いに相手サーバのダウンを検出し、フェイルオーバー処理を実行してしまいます。結果として、複数のサーバでファイルシステムを同時にマウントしてしまい、データ破壊を引き起こします。フェイルオーバークラスタシステムでは異常が発生したときに適切に動作しなければならないことが理解できると思います。
このような問題を「ネットワークパーティション問題」またはスプリット・ブレイン・シンドローム(Split-brain-syndrome)と呼びます。フェイルオーバークラスタでは、すべてのインターコネクトが切断されたときに、確実に共有ディスク装置の排他制御を実現するためのさまざまな対応策が考えられています。
「RESET & RESERVE」問題
共有ディスク装置を排他制御するために、SCSIコマンドのRESERVEを利用するクラスタシステムがあります。これは「RESET & RESERVE」などと呼ばれる手法で、共有ディスクを使用するサーバは共有ディスクのロジカルユニットに対するRESERVE状態を保持し、ほかのサーバからのRESERVE要求に対してRESERVATION_CONFLICTを返すことで排他制御を実現します。共有ディスク使用中のサーバがダウンした場合は、共有ディスクを引き継ぐサーバ側でRESETコマンドを発行し、RESERVE状態を強制的に開放(RELEASE)した後、ターゲットのロジカルユニットをRESERVEします。
ネットワークパーティション問題が発生した場合は、タイミングによってRESERVEを獲得したサーバに優先権が与えられます。
しかし、この仕組みを利用するうえで、Linuxは問題を抱えていました。多くのディストリビュータが採用していたLinuxカーネルでは、RESERVATION_CONFLICT発生時に自動的にRESETを発行して強制的にRESERVEしようとしていました。最近では、この問題を回避するパッチを適用したカーネルも公開され、最初からパッチを組み込んだカーネルを採用するディストリビュータも出てきたようです。
クラスタリソースの引き継ぎ
クラスタが管理するリソースにはディスク、IPアドレス、アプリケーションなどがありました(第1回参照)。フェイルオーバークラスタシステムでは、これらのクラスタリソースを引き継ぐためにLinuxのどのような機能を利用しているのでしょうか? また、Linuxに不足しているのはどのような機能でしょうか?
データの引き継ぎ
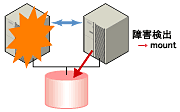 図3 データの引き継ぎ
図3 データの引き継ぎクラスタシステムでは、サーバ間で引き継ぐデータは共有ディスク装置上のパーティションに格納します。すなわち、データを引き継ぐとは、アプリケーションが使用するファイルが格納されているファイルシステムを健全なサーバ上でマウントしなおすことにほかなりません。共有ディスク装置は引き継ぐ先のサーバと物理的に接続されているので、クラスタソフトウェアが行うべきことはファイルシステムのマウントだけです。
単純な話のようですが、クラスタシステムを設計・構築するうえで注意しなければならない点があります。
1つは、ファイルシステムの復旧時間の問題です。引き継ごうとしているファイルシステムは、障害が発生する直前までほかのサーバで使用され、もしかしたらまさに更新中であったかもしれません。このため、引き継ぐファイルシステムは通常ダーティであり、fsckなどによるファイルシステムの整合性チェックが必要な状態となっています。ファイルシステムのサイズが大きくなると、fsckに必要な時間は莫大になり、場合によっては数時間もの時間がかかってしまいます。それがそのままフェイルオーバー時間(業務の引き継ぎ時間)に追加されてしまい、システムの可用性を低下させる要因になります。
もう1つは、書き込み保証の問題です。アプリケーションが大切なデータをファイルに書き込んだ場合、同期書き込みなどを利用してディスクへの書き込みを保証しようとします。ここでアプリケーションが書き込んだと思い込んだデータは、フェイルオーバー後にも引き継がれていることが期待されます。例えばメールサーバは、受信したメールをスプールに確実に書き込んだ時点で、クライアントまたはほかのメールサーバに受信完了を応答します。これによってサーバ障害発生後も、スプールされているメールをサーバの再起動後に再配信することができます。クラスタシステムでも同様に、一方のサーバがスプールへ書き込んだメールはフェイルオーバー後にもう一方のサーバが読み込めることを保証しなければなりません。
ext2からジャーナリングファイルシステムへ
これら2つの点で、Linux標準のext2ファイルシステムには不満が残ります。このような問題を解決する高可用性ファイルシステムであるext3やReiserFSのようなジャーナリングファイルシステムの開発が進められています。
ジャーナリングファイルシステムでは、アンマウントしなかったダーティなファイルシステムをfsckすることなしにマウントすることができます。Linuxのジャーナリングファイルシステムはまだまだ発展途上にあり、Linuxカーネル2.2で実績のあるext3ファイルシステムや最近Linuxカーネル2.4に組み込まれて話題になったReiserFSなど、どれが今後の標準となるか動向から目を離せません。
さらに一歩踏み込んで、複数のサーバで同時に1つのファイルシステムをマウントできるクラスタファイルシステムの開発も進められているようです。こういったファイルシステムの出現によって、Linuxクラスタはさらなる可用性の向上へと向かって発展していくと思われます。
CLUSTERPROにおける実装
NECのCLUSTERPROでは、robust ext2ファイルシステムを採用することでクラスタシステムの可用性を高めています。これは、Linuxで最も実績のあるext2ファイルシステムをベースに、性能向上およびメタデータの書き込み順序を修正して耐障害性を高め、fsckレスを実現したものです。
今後、Linuxの標準動向やジャーナリングファイルシステムそのものの信頼性を見ながら、順次ジャーナリングファイルシステムを採用していく予定です。
CLUSTERPRO:http://www.ace.comp.nec.co.jp/CLUSTERPRO/
エイリアスIPアドレスとGratuitous ARP
IPアドレスの引き継ぎは、サーバに通常割り付けられるIPアドレスとは別のIPアドレスを動的に割り付けることで実現します。このアドレスを仮想IPアドレスと呼びます。
Linuxには1つのNICに通常のIPアドレスのほかに、別名のIPアドレス(エイリアスIPアドレス)を設定する機能があります。仮想IPアドレスはこの機能を使用することで簡単に実現できます。
また、サーバと通信していたクライアントやネットワーク機器はARPテーブルを保持しているので、Gratuitous ARPと呼ばれる自ホストに対するARPパケットをブロードキャストすることで、これらのテーブルを更新して仮想IPアドレスの引き継ぎを完了します。
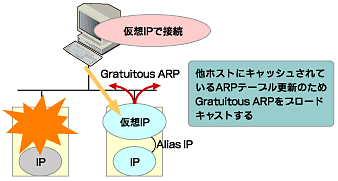 図4 仮想IPアドレスの実装
図4 仮想IPアドレスの実装このようにARPを利用してIPアドレスだけを引き継ぐのではなく、MACアドレスごと引き継ぐ方式を採用するクラスタもあります。MACアドレスを引き継ぐ利点は、Gratuitous ARPに応答しないネットワーク機器やTCP/IP以外のプロトコルでの通信についても引き継げる点にあります。
アプリケーションの引き継ぎ
クラスタソフトウェアが業務引き継ぎの最後に行う仕事は、アプリケーションの引き継ぎです。フォールトトレラントコンピュータ(FTC)とは異なり、一般的なフェイルオーバークラスタでは、アプリケーション実行中のメモリ内容を含むプロセス状態などを引き継ぎません。すなわち、障害が発生していたサーバで実行していたアプリケーションを健全なサーバで再実行することでアプリケーションの引き継ぎを行います。
例えば、データベース管理システム(DBMS)のインスタンスを引き継ぐ場合、インスタンスの起動時に自動的にデータベースの復旧(ロールフォワード/ロールバックなど)が行われます。このデータベース復旧に必要な時間は、DBMSのチェックポイントインターバルの設定などによってある程度の制御ができますが、一般的には数分程度必要となるようです。
多くのアプリケーションは再実行するだけで業務を再開できますが、障害発生後の業務復旧手順が必要なアプリケーションもあります。このようなアプリケーションのためにクラスタソフトウェアは業務復旧手順を記述できるよう、アプリケーションの起動の代わりにスクリプトを起動できるようになっています。スクリプト内には、スクリプトの実行要因や実行サーバなどの情報をもとに、必要に応じて更新途中であったファイルのクリーンアップなどの復旧手順を記述します。
フェイルオーバー総括
今回紹介した内容から、次のようなクラスタソフトの動作が分かると思います。
- 障害検出(ハートビート/リソース監視)
- ネットワークパーティション問題解決(NP解決)
- クラスタ資源切り替え
- データの引き継ぎ
- IPアドレスの引き継ぎ
- アプリケーションの引き継ぎ
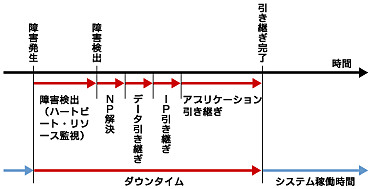 図5 フェイルオーバータイムチャート
図5 フェイルオーバータイムチャートクラスタソフトウェアは、これら1つ1つを確実に短時間に実行することを求められています。今回解説した内容をはじめ、さまざまな考慮・対策を行うことでクラスタソフトウェアは高可用性(High Availability)を実現していることを理解していただけたと思います。
今回はLinuxクラスタの実現ということで、少し技術的な内容になってしまいました。次回も技術的な話になりそうな気がするので、@ITのほかの記事を読んでスキルアップしておいてください。なお、第3回は5月中旬掲載予定です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。