メールの文字コードを理解する:Tech TIPS
電子メールで使用される文字コードにはさまざまなものがあり、日本語メールでも複数のコードが使用されている。使用されているメールのコードはヘッダ中のContent-Type:フィールドに記録されている。メールの文字化けして正しく表示されない場合は、強制的にエンコーディング形式を変更するとよい。
この記事で分かること
- 電子メールの文字化けは、文字コードと表示設定の不一致によって発生する
- 使用されている文字コードは、メールヘッダ内の「Content-Type:」フィールドで確認できる
- 自動判別がうまくいかない場合は、手動で表示エンコーディングを変更する
更新履歴
【2025/06/09】記事の要約を追記しました
対象ソフトウェア:Outlook/Outlook Express
解説
電子メールで利用される文字コードには、言語ごとに異なっているのはもちろんのこと、同じ日本語であっても、複数の種類の文字コードが利用されている。本稿では、日本語メールで利用される文字コードの種類についてまとめておく。使用されている文字コードに対して、メールの表示設定があっていないと、いわゆる「文字化け」が発生し、正しくメールの内容を読むことができなくなる。メール・ソフトウェアは文字コードを自動で判別するが、場合によってはその機能が正しく動作しないこともあり、そうした場合には自分で文字コードを調べ、適切な表示コードを手動で選択させるとよいだろう。
●文字コードの種類
日本語環境向けのメール・ソフトウェアでは、以下のような文字コードがサポートされている。歴史的な経緯などにより、さまざまな文字コードが利用され、現在ではこのようになっている。
| 文字コード | エンコード名 | 意味 |
|---|---|---|
| ANSIコード | us-ascii | 英数字記号文字を含む、7bitの基本的な文字コード。ほかの文字コードでも、英数字部分の文字コードはこのANSI文字コードをベースにしているものがほとんどである。ASCIIコードとも呼ばれる |
| Latin 1コード | iso-8859-1 | 英語以外の、ラテン系の欧州言語(仏語や独語、伊語ほか)で使用されるコード |
| JISコード | iso-2022-jp | ANSI文字コードと漢字文字コードを、「エスケープ・シーケンス」と呼ばれる特別な文字シーケンスで切り替えながら共存させている。ほとんどの場合、インターネット電子メールやニュースは、この文字コードで送受信される |
| シフトJIS | shift_jis | MS-DOSの時代から広く使われている文字コード。漢字文字コードの「JISコード」をベースにして、ANSI文字と共存させている。PC環境では一般的な日本語文字コード |
| EUC | euc-jp | UNIX環境で広く使われている日本語文字コード。シフトJISとは異なる方法でANSI文字と漢字文字を共存させている |
| Unicode UTF-7 | utf-7 | Unicodeは、世界中の文字を16bitもしくは32bitの固定長の文字コードで統一的に扱うために作られたコード。16bitの方をUCS-2、32bitの方をUCS-4という。Unicodeをファイルへの保存や、通信回線上で送受信するためのエンコーディング方法の1つがUTF-7である。Unicode(UCS-2)を7bitのコードでのみ送信できるように、一部のUnicode文字をBase64でエンコーディングしている |
| Unicode UTF-8 | utf-8 | Unicodeをファイルに保存したり、通信回線上で送受信したりするためのエンコーディング方法の1つがUTF-8である。2bytes以上の可変長データの組み合わせでUnicodeを表現する。非ASCII文字(U+0080以降の文字)では、各バイトの最上位bit(MSB)が1になるので、場合によっては(7bitデータしか通さないメール・システムだと)利用できないことがある |
| 日本語メールで利用される主な文字コード 日本語メール環境で利用できる主な文字コード(Latin 1以外にも多くの欧米系の言語がサポートされているが、ここでは取り上げない)。ただしシフトJISコードやEUCコードは現在のメールではほとんど利用されていない。これらのコードでは、日本語と英語を同時に表現できるが、それ以外の言語をさらに混在させるのが困難だし、昔のメール・システムでは8bitコードを送信できなかったからだ(最上位bitの情報が欠落してしまう)。エンコード名とは、文字コード種別を表すために、メール・ヘッダ中に記述される文字列のこと(大文字/小文字の違いは関係ない)。 | ||
このうち、現在日本語メールとして広く一般に利用されている文字コードはJISコードであり、ほとんどのメールではこれが利用されている。シフトJISやEUCは、Webページの制作などではまだ利用されているが、メール環境ではほとんど利用されていない。これらのコードは、ほかの言語との互換性や、多言語が同一メッセージ中に混在するようなメールではうまく利用できないからだ。また昔のメール・システムでは8bitコードを送信できなかったので(最上位bitは強制的に0にされてしまう)、8bitを全部使うようなコードは避けられている。
これ以外に、最近では文字コードとしてUnicode(UTF-7もしくはUTF-8)が利用されるケースも少なからずある。スパムを始めとした海外からのメールでよく利用されているようだし、サーバOSやサーバ・アプリケーションなどが送信してくる、動作確認や通知用のメッセージでも利用されていることが多い。
●メール・ヘッダ中における文字コードの指定
メール本文で使用されている文字コードは、メールのヘッダ中に記録されている。メール・メッセージが正しく表示されない場合は、エンコード方法を調査し、それに一致した表示エンコーディング方法を選択すればよい。
文字コードの種類(エンコーディング方法)は、ヘッダ中の「Content-Type:」フィールドに記録される。テキストのみのJISコードなら「Content-Type: text/plain; charset="ISO-2022-JP"」、UTF-8なら「Content-Type: text/plain; charset="UTF-8"」、英語メールなら「Content-Type: text/plain; charset="US-ASCII"」などとなる(「text/plain;」はテキスト形式を表す。HTML形式なら「text/html;」となる)。もしマルチパート・メール(複数のパートに分かれている、添付ファイルのあるメール、HTML形式のメールなど)なら、各パートごとにこのヘッダ情報が付けられている。
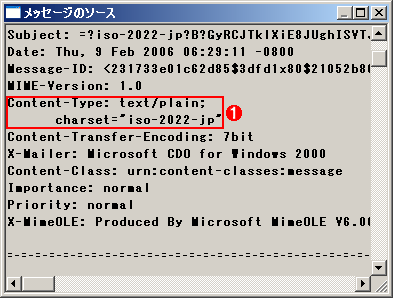 文字コードの確認
文字コードの確認メール中で使用されている文字コードは、メール・ヘッダのContent-Type:フィールドに記録されている。メール・ヘッダの情報を確認するには、関連記事のTIPSを参考にしていただきたい。Outlook Expressなら、メッセージを表示した状態でCtrl+F3キーを押すと、簡単にこの画面を表示させることができる。
(1)メール・ヘッダ中の文字コードの指定。メールによっては存在しない場合もあるし、マルチ・パートのメール(添付ファイルのあるメールやHTML形式のメールなどで使用されている)の場合は、パートごとにこのコード指定が存在している。
●表示文字コードの変更
メール・ソフトウェアでは、使用されている文字コードを自動的に判別し、適切なエンコーディング方法でメッセージの内容を表示するようになっている。だが、エンコーディングの指定情報が欠落していたり(スパム・メールや自動送信メールなどでは欠落していることが多い)、コードの指定が間違っている、コードが誤認識されてしまったなどのさまざま理由により、自動的な判定がうまくいかない場合がある。そんな場合は手動で表示コード指定を変更すれば、正しく表示できる可能性がある。一般的な日本語メールなら、「自動選択」「シフトJIS」「Unicode(UTF-8)」「Unicode(UTF-7)」あたりを試してみればよいだろう。
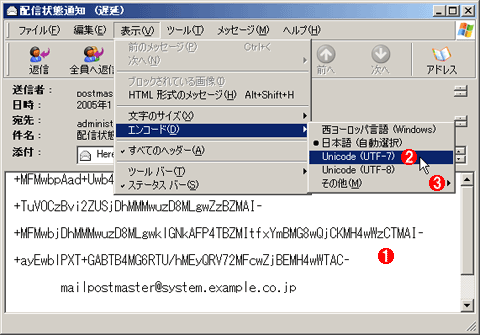 表示する文字コードの指定
表示する文字コードの指定これはOutlook Expressにおける表示文字コードの強制指定の方法。メール・メッセージが表示された状態で、[表示]メニューの[エンコード]で、適切なものを選択する。
(1)文字化けした状態のメール。表示文字コードの指定が正しくないと、このように文字化けしたように見える。これはUTF-7で送信された、サーバ・システムからの通知メールの例。
(2)文字コードの指定。正しく表示されない場合は、日本語関連の文字コードをいくつか試してみればよい。
(3)表示されている以外にも、さまざまな文字コードがこの下に用意されている。UTF-7やUTF-8は、最初はこの[その他]の下にあるが、1度使うと、 (2)のように、上に表示される。
■関連記事(Windows Server Insider)
- Outlook Expressでメール・メッセージのソース情報(ヘッダ情報)を表示する(TIPS)
- ファイルの文字コードを変換する(TIPS)
- Outlook 2002におけるメッセージ・エンコーディングの問題点(TIPS)
- 電子メールやニュース投稿で他人に迷惑をかけないためのOutlook Express設定法(TIPS)
■この記事と関連性の高い別の記事
- WindowsでInternet Explorerを使って文字コードを変換する(TIPS)
- nkfツールで文字コードを変換する(Windows編)(TIPS)
- WindowsからiPhone/iPod touch/Macに送ってはいけない文字とは?(TIPS)
- Windowsでバイナリファイルの内容をメモ帳(notepad)で確認する(TIPS)
- WindowsでUnicode文字を簡単に入力したり、Unicodeの文字コード番号を調べたりする方法(TIPS)
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。