WindowsでInternet Explorerを使って文字コードを変換する:Tech TIPS
Windows環境では、シフトJIS以外にもさまざまな文字コードが利用されている。しかしWindows標準のコマンドやツールはシフトJIS以外の文字コードを正しく扱えないこともある。そこでInternet Explorerを利用すると、手軽に文字コードを変換して別のファイルに保存できる。
対象ソフトウェア:Windows XP/Windows Vista/Windows 7/Windows 8/Windows 8.1/Windows Server 2003/Windows Server 2008/Windows Server 2008 R2/Windows Server 2012/Windows Server 2012 R2、Internet Explorer 6/7/8/9/10/11
解説
コンピューターで使われる文字コード体系にはさまざまなものがある。Windowsで使われる文字コードとしては、MS-DOSの時代から「シフトJIS」コードがほぼ標準であった。だが、UNIX/LinuxやMac、スマートフォン/タブレット、そしてインターネット環境などでは、その他の文字コードも多く使われている。
また日本語だけでなく、世界中の言語もコンピューターで統一的に取り扱うために、現在のWindows OSでは、内部的には「Unicode」を使って処理を行っている。そして外部との入出力時に他の文字コードと相互に変換を行っている。
日本語に限っていえば、現在のWindows環境では以下のような文字コード形式がよく使われている。
| 文字コード名 | 意味 |
|---|---|
| ANSI | アルファベットの英数字記号文字を含む、7bitの基本的な文字コード。他の文字コードでも、英数字部分の文字コードはこのANSI文字コードをベースにしているものがほとんどである。ASCIIコードとも呼ばれる |
| シフトJIS | MS-DOSの時代から日本で広く使われてきた文字コード。漢字文字コードとして、「JISコード」表をべースにして変形させたもの(シフトしたもの)を利用して、ANSI文字と共存させているのでこう呼ばれる。PC環境では一般的な日本語文字コード |
| EUC | 初期の日本語対応UNIX環境で広く使われていた日本語文字コード。シフトJISとは異なる方法でANSI文字と漢字文字を共存させている。現在のUNIX/LinuxではUnicode/UTFを使っているものが多い |
| JISコード | ANSI文字コードと漢字文字コードを、「エスケープシーケンス」と呼ばれる特別な文字シーケンスで切り替えながら共存させている文字コード。従来、インターネット電子メールはこの文字コードで送受信されることが多かったが、代わりにUTF-8がよく使われるようになってきている |
| Unicode | 世界中の文字を16bitもしくは32bitの固定長の文字コードで統合的に扱うために作られた文字コード。文字の種類によらずコード長が一定しているので、プログラムから扱いやすく、OSやアプリケーションの内部コードとして使われることが多い。ただし次のUTF-16と同義に使われる場合も多い。Windows OSも内部ではこのUnicodeを利用している |
| UTF | Unicodeをベースにして、実際にファイルに格納したり、通信を行う場合のバイトデータの並べ方などを規定したもの。UTF-7とかUTF-8、UTF-16、UTF-32などがある。UTF-16では、バイトオーダーの違いにより、リトルエンディアン形式とビッグエンディアン形式などの違いがある。特にUTF-8は、シフトJISやJISコードに代わってよく使われるようになってきている |
| 日本語のWindows OS環境でよく使われる文字コード | |
これら文字コードの違いは、通常のユーザーは気にする必要はない。だが場合によっては、文字コードの違いによって正しく処理ができないといったケースもある。
例えば、Windows OSのコマンドプロンプト上で使われる各種の標準コマンドでは、シフトJIS以外の文字コードで書かれたテキストを処理できないものが多い(コマンドによってはシフトJISとUnicodeの両方が使えるものもある)。またメモ帳では、「JISコード」や「EUCコード」で書かれたテキストファイルを開くと文字化けしてしまう。
このような場合は、アプリケーションが理解できる形に、あらかじめ文字コードを変換しておくことが望ましい。本稿では、何かツールを用意することなく、Windows OS標準装備のInternet Explorer(以下IE)を利用して手軽に文字コードを変換する方法を紹介する。その他の方法については、次の記事を参照していただきたい。
操作方法
ファイルに含まれる文字のコード(漢字の文字コード)を変換するには、Internet Explorer(以下IE)を使うのが簡単でよい。操作方法としては、単にIEで対象ファイルを開き、別の文字コードを指定してテキスト形式で保存するだけである。これだけで別の文字コードに変換できる。
●まずIEで対象のファイルを正しい文字コードで表示させる
文字コードを変換するには、まず任意の文字コードで記述されたファイルを、「〜.txt」というファイル名に変更する。そしてこれを、起動したIEのウィンドウへドラッグ&ドロップする。
この時点でIEの画面には、対象ファイル内に記述されたテキストが正しく表示されているはずである(その場合は「正しく表示されたら別のファイルに保存する」へ進んでいただきたい)。だが、この段階で文字化けが生じることもしばしばある。
IEではファイルやWebページ中で使われている文字コードを自動的に判別して、正しい文字コードで表示する機能を持っている。しかし、文字コードを判別するための情報が少なかったり、判別不可能な文字ばかりが使われていると、文字コードの判別に失敗して文字化けが生じることがある。
このような場合は、ユーザーが手動で「正しい」文字コードを指定すればよい。どの文字コードなのか分からない場合は、以下の画面のポップアップメニューで各文字コードを1つずつ選択して、文字化けが解消されるまで試してみよう。
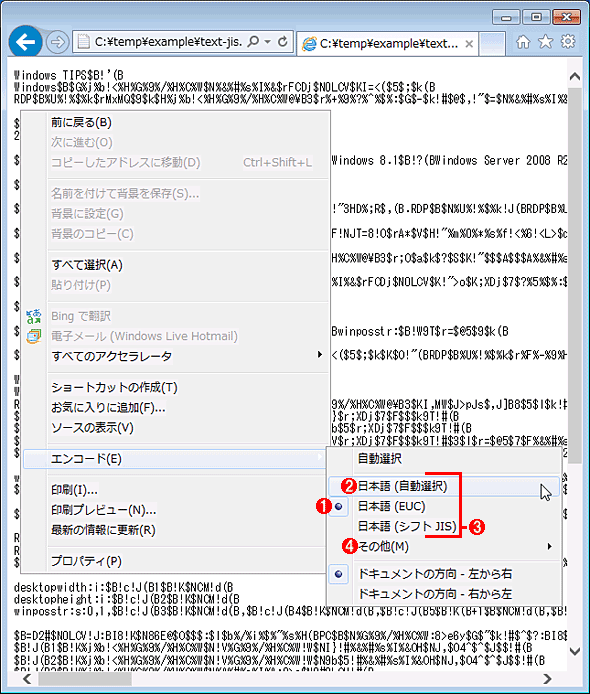 IEで表示中のテキストの文字化けを直す
IEで表示中のテキストの文字化けを直す表示されている文字が化けている場合は、ユーザーが文字コードを明示的に指定することにより、強制的に正しい文字コードで表示できる。文字コードを指定してファイルを保存するためには、あらかじめ正しく表示させておかなければならない。文字コードを変更するには、ウィンドウ上で右クリックしてポップアップメニューから[エンコード]を選ぶか、[Alt]キーを押して表示されるメニューバーから[表示]−[エンコード]を選択する。
(1)現在のエンコーディング形式がこのようにマーク付きで表示される。これが望みの文字コードでない場合は、他の文字コードを選択できる。ただしJISコードの場合は[日本語 (JIS)]という項目が淡色表示されるが、[日本語 (JIS)]を選択することはできない。代わりに[日本語 (自動選択)]を選択する。
(2)[日本語 (自動選択)]は、文字コードを自動的に判別させる場合、およびJISコードを選択したい場合に使用する。
(3)すでに何度か使った文字コードの場合はここに表示されているので、素早く選択できる。
(4)あまり使ったことのない文字コードの場合は、[その他]を選択すると、(日本語以外も含む)全てのエンコーディング形式がサブメニューとして表示される。
●正しく表示されたら別のファイルに保存する
IEの画面上で正しく文字が表示されれば、別の文字コード形式で別のファイルに保存できる。
別のファイルへ保存するには、[Alt]キーを押して表示されるメニューバーから[ファイル]−[名前を付けて保存する]を選択する(IE9以降では[Ctrl]+[S]キーを押してもよい)。すると次のような画面が表示されるので、[エンコード]で文字コードを選択して保存する。
現在の表示内容がWebページの場合は、[ファイルの種類]を[テキスト ファイル]にすることにより、テキスト文字部分のみをテキストファイルとして保存できる。
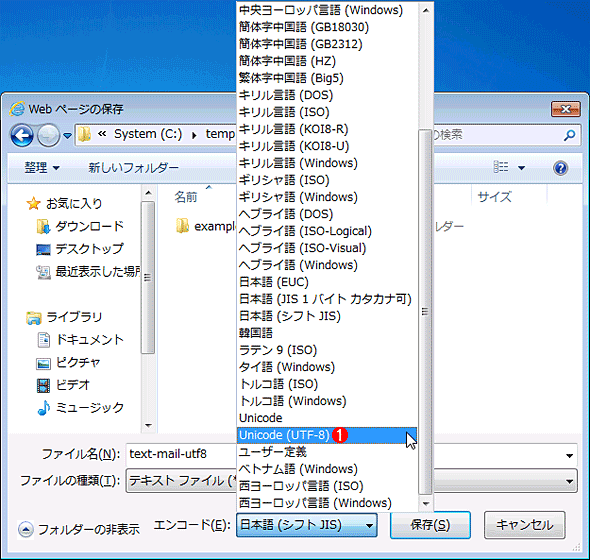 保存時の文字コードを選択する
保存時の文字コードを選択する保存時に文字コードを指定することにより、元のテキストファイルの文字コードとは異なる形式の文字コードで保存できる。
(1)保存時の文字コードを選択する。日本語の場合に指定できる文字コードの名称については、次の表を参照していただきたい。
このメニューで選択できるのは、日本語では以下のものだけである。
| 選択できる文字コードの名称 | 意味 |
|---|---|
| Unicode | 16bitのリトルエンディアンのUTF-16(16bit Unicode)*1 |
| Unicode (UTF-8) | UTF-8(8bit Unicode)*1 |
| 日本語 (EUC) | EUCコード |
| 日本語 (JIS 1 バイト カタカナ可) | JISコード |
| 日本語 (シフト JIS) | シフトJISコード |
| IEで保存できる文字コードの種類(日本語関連のみ) *1 IE8以前では、ファイルの先頭にBOM(Byte Order Mark)と呼ばれる、Unicodeの特別なデータが先頭に書き込まれない。 | |
●IE8以前でUnicodeを選択した場合は「バイトオーダーマーク(BOM)」に注意
IE8以前の場合、上記の手順で「Unicode」「Unicode (UTF-8)」を選んで保存すると、ファイルの先頭にUnicodeの「BOM(Byte Order Mark)」コードが書き込まれない。IE9以降では正常に書き込まれる。
BOMとは、バイトオーダーを識別するための特別なデータだ。特にUnicode(UTF-16)の場合、ファイルの先頭にこのBOMを記入しておくことで、バイトオーダーを正確に判定できる。BOMが存在しないと、アプリケーションによっては正しくUnicodeファイルを読み込むことができない場合がある。
このような場合は、IEで保存するのではなく、IEの画面上でテキストを選択・コピーしてからメモ帳に貼り付け、そこであらためてUnicodeで保存するなどの操作を行えばよい。メモ帳がUnicodeで保存する場合は、必ずBOMが書き込まれるからである。
■更新履歴
【2014/10/29】Windows Vista以降のWindows OS、およびInternet Explorer 6〜11に対応しました。
【2004/02/28】初版公開(対象ソフトウェアはWindows 2000/XP/Server 2003)。
■この記事と関連性の高い別の記事
- WindowsでUnicode文字を簡単に入力したり、Unicodeの文字コード番号を調べたりする方法(TIPS)
- nkfツールで文字コードを変換する(Windows編)(TIPS)
- メールの文字コードを理解する(TIPS)
- WindowsからiPhone/iPod touch/Macに送ってはいけない文字とは?(TIPS)
- Windowsでバイナリファイルの内容をメモ帳(notepad)で確認する(TIPS)
- テキスト・ファイルの行末コードを変更する(TIPS)
- ファイルの文字コードを変換する(TIPS)
- スクリプトレット・コンポーネントでリソース情報を定義する(TIPS)
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。