XMLと関連仕様に強くなるために 〜W3Cサイト徹底攻略法!〜:新入社員のためのXML入門講座(2)
シリーズ「新入社員のためのXML入門講座」では、XMLの基礎をさまざまな記事を通じて理解してもらう予定だ。第2回である本記事では、XMLや、その関連仕様の原典を読みこなすために、W3CのWebサイトを詳しく紹介していく。
XMLの基本的な仕様は「XML 1.0」として1998年に決まり、現在に至るまでほとんど変化していない。しかし、そのXML 1.0仕様を基にしたさまざまな技術、XMLのセキュリティや問い合わせ言語、Webサービスといったものが次々生まれ、急速に進化している。
こうした新しい技術の情報を収集するためには、仕様の原典に当たるのが最も確実。そして、XMLとそれに関連する技術を策定している団体がWorld Wide Web Consortium(W3C)であり、W3CのWebサイトには、現在策定中の仕様も含めて多くの仕様が公開されている。そこでこの記事では、W3Cのサイトから目的の情報をどうやって探し、読み取るのか。基本的なテクニックを紹介していこう。
XML仕様を決めているのがW3C
XMLとその関連仕様などを策定しているのがW3C。ダブル・サン・シーなどと呼ばれている。インターネットではさまざまな技術が使われているが、TCP/IPのような基本的なプロトコルは主にThe Internet Engineering Task Force(IETF)で決められており、W3Cの役割は、HTMLやHTTPそしてWebサービスといった上位層で使われる標準技術の策定にある。
W3Cのサイトでは、XMLやXHTMLやCSSなど、策定された技術の仕様書がすべて公開されている。つまりここが、Webの標準技術を利用する技術者にとっての公式情報サイトといえるのだ。それだけでなく、W3Cで検討中のすべての技術情報も掲載されているため、いまどのような技術の標準化が進んでいるのか、今後どの方面の標準化が進むのかといった動向も分かるようになっている。
技術的な問題で行き詰まったとき、顧客に新システムの導入を提案するときなどに、W3Cの仕様書や技術動向を直接参照できるエンジニアであれば、仕様の原典に当たって調査することができる。また今後の技術動向も正確に説明できる、よりスキルの高いエンジニアとして活躍することができるようになるのだ。
W3Cのサイトは、ほとんどが英語で書かれている。しかし、どの場所にどんな項目があるのか、基本的な知識があれば、W3Cサイトを渡り歩いて必要な内容を調べることは難しくない。この記事を頼りに、W3Cサイトを少しずつ攻略していってほしい。
では、W3CのサイトのURLを開いていこう。
W3Cの入り口をのぞいてみる
W3Cのサイトは軽くシンプルにまとめられている。ユーザーが必要な情報にたどり着きやすいように、ユーザーインターフェイスもよく考慮されており、コツさえつかめば効率良く情報を探すことができるようになっている。
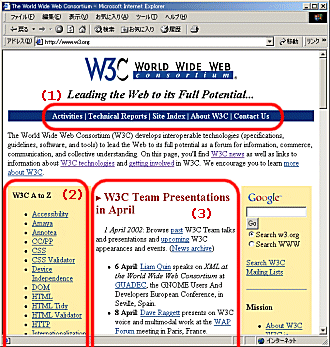
トップページを見ていこう。画面上部にW3Cのロゴ、その下にはあい色のメニューとW3Cの簡潔な紹介がある。さらにその下は3段組みになっており、左から、「W3C AtoZ」、最新ニュースのダイジェスト、検索やサイト紹介などに分かれている。そして画面下には本Webサイトそのものや著作権について明示されている。
(1) 画面上部のメニューバー
まずは画面上部を横に走るバーがあって、Activities、Technical Reports、Site Indexなどのメニューが並んでいる。
- Activities:活動組織
W3Cは大きく分けて5つの「ドメイン」(アーキテクチャ、ドキュメントフォーマット、インタラクション、技術と社会、Webアクセシビリティ・イニシティチブ)に技術を分類しており、それぞれのドメインで、さらに技術ごとに「アクティビティ」や「ワーキンググループ」を設けている。これらのドメインやアクティビティについてどういう体系になっているのか活動組織体系が示されている。 - Technical Reports:技術文書一覧
W3Cの活動の大きな役割として、インターネットに関する技術仕様の策定がある。それぞれの技術文書は関係者が集い、アクティビティやワーキンググループで仕様を考え、途中経過の文書を公表したり、メンバー内外でレビューしたりすることを繰り返して、仕様を固めていく。
そのほかにも、このメニューバーには次のようなメニューがある。
- Site Index:サイト案内
- About W3C:W3Cについて
- Contact Us:W3Cの連絡窓口
W3CのホストはアメリカのMIT/LCS(マサチューセッツ工科大学計算機科学研究所)、フランスのINRIA(フランス国立情報処理自動化研究所、日本の慶應義塾大学SFC研究所の3つの組織が担当している。それ以外にも各国には連絡先窓口となるところがあるようだ。

(2) W3C AtoZ:W3Cのトピック一覧
左側の列には、W3Cで策定している技術がアルファベット順で並んでいる。例えば、HTML、URI/URL、XHTMLなど、普段から親しみのある技術から、SOAP、Web Services、Device Independenceなど、注目を浴びている技術まで、この中に見ることができる。もちろん、XML、DOM、SVG、XML Queryなど、XML関連の技術もここに並んでいる。
W3Cのサイトから目的の情報を探す場合、この左側の縦に並んでいるメニューを一番使うことになるだろう。

(3)最新ニュースのダイジェスト
中央の列にはW3Cから発信されるニュースのダイジェストが表示されている。一番新しいニュースが一番上に表示されている。ここでは技術情報の更新ニュースが中心になるが、W3Cが主催するイベントやミーティングなども案内されることがある。この欄に表示されなくなったニュースは、画面下の「Past News」をクリックすればさかのぼって参照できる。
では、このトップページからXMLの仕様を探してみることにしよう。W3Cのトップページから、左側の列にあるW3C AtoZのトピックにある「XML」の項目をクリックする。
XMLアクティビティに関する総合情報
すると現れるのが、XMLのWebページ「Extensible Markup Language(XML)」だ。実は、このWebページはW3Cの中でXMLに関連する仕様全体を扱っている組織、「XMLアクティビティ」のページである。
W3Cで各技術を任されているアクティビティは、それぞれ自分のホームページを持ち、その技術に関するニュースや関連仕様へのリンク、参考資料などを紹介している。XMLアクティビティのこのページでも、XMLとその関連仕様の進ちょくや結果、開発者向けの各種情報へのリンクなどが集まっている。
XMLアクティビティの構成
XMLアクティビティは、XMLとその関連仕様を策定するために、アクティビティをさらに5つのワーキンググループに分けている。
1. XMLコーディネーション・グループ
各ワーキンググループの調整、進ちょく管理、問題管理などを行う
2. XMLコア・ワーキンググループ
XML文法、XML名前空間、XML Information Setなど、XML仕様の根幹にかかわる部分を担当する
3. XML Linkingワーキンググループ
XPointer、XLink、XML Baseなど、XMLに関するハイパーリンクを担当する
4. XML Queryワーキンググループ
XML問い合わせ言語XML Queryを担当する
5. XML Schemaワーキンググループ
DTDに代わるスキーマ言語、XML Schemaを担当する
ちなみに、XMLのアクティビティ・リードを担当しているのはLiam Quin氏だ。また、Webサービスなど、XMLに関連していても独立したアクティビティとなっているものもある(ただし、あるアクティビティが別のドキュメントではワーキンググループと呼ばれているなど、W3Cのサイトの中で、アクティビティやワーキンググループの呼称や位置付けはあまり厳密に統一されていないようだ)。

では画面を見ていこう。この画面にはW3Cのロゴが表示され、ロゴの右には「ARCHITECTURE domain」というロゴが表示されている。
これは、XMLアクティビティがW3Cの中のアーキテクチャ・ドメインに属していることを示している。アーキテクチャ・ドメインは、XMLのような構造化データを扱うXMLアクティビティのほかに、アプリケーション間通信の「Webサービス・アクティビティ」、リソースを示す「URIアクティビティ」、そのほか「HTTPアクティビティ」「DOMアクティビティ」など、World Wide Webの根幹をなす技術を担当するアクティビティが属している。
その下には「Extensible Markup Language」という文字が躍っているのが分かるだろう。
冒頭に主要な文書へのリンク
ページの最初の文章の中には、「XML 1.0」仕様書へのリンク(実際には、仕様書へのリンクが書かれた部分へのリンク)、XMLの特徴を簡潔に10項目で解説した「XML in 10 points」へのリンク、そしてXML関連仕様の中でも最も重要な「Namespaces(XML名前空間)」へのリンクが示されている(それぞれを、右の画面では赤い四角と緑の四角で囲った)。
関連仕様へのリンク
その下には、「Nearby」に続いてXML関連仕様が列挙されている。上の画面では文字が小さくて読みにくいかもしれないが、「XML Protocol」「XML Schema」「XML Query」「XLink、XPointer」など、XMLを理解するうえで重要な各種仕様が並んでいる。
策定中の関連仕様
さて、それに続く最初の大きな見出しが「Working Drafts」だ。ここには、現在策定中のXML関連仕様の状況が示されている。画面に表示されているのは、「XML Inclusion(XInclude)」「XML Information Set」「XML Fragment Interchange」の3つ。Working Draftsについては後述するが、おおまかには策定中の仕様であることを意味している。
しかし、ここに策定中のすべての仕様が掲載されているわけではない。あくまでも、主なものが載っているだけだ。
メーリングリストやコミュニティなど
その下の見出し「Developer Discussion」は、XMLに関する仕様策定について話し合うためのメーリングリストやニュースグループを案内している。
上の画面では紹介できていないが、このWebページのさらに下には、イベントや発行文書の履歴、各国語に翻訳した文書へのリンク(日本語もある)、XMLを実装したソフトウェアのリスト、推薦図書、参考資料といった項目についての紹介もある。
上に示した画面で赤い四角で囲った部分から、XML 1.0の仕様書へリンクをたどることができる。今度はそこをたどって、XML 1.0仕様のWebページを表示させてみよう。
XML 1.0:W3C技術文書の構造

このWebページ「Extensible Markup Language (XML) 1.0 (Second Edition)」が、XML 1.0の最新仕様を表したものだ。W3Cでは、こうした仕様書のことをひとまとめにTechnical Report(技術文書)と呼んでいる。
XML 1.0に限らず、さまざまな仕様を表した技術文書のWebページは、どのトピックでもだいたいインターフェイスが統一されている。
ロゴと更新日付
まず左上にはW3Cのロゴが表示されている。IETFと共同で開発した仕様であれば、IETFのロゴが入る場合などもある。
そして、タイトルには技術仕様の正式名称が大きな見出しになっている。タイトルは、ときどき仕様の策定途中でも変更されることがあるので注意しよう。この文書のタイトルは、「Extensible Markup Language(XML) 1.0 (Second Edition)」、つまり、XML 1.0第2版ということになる。
その下に「W3C Recommendation 6 October 2000」と記されているのは、2000年10月6日に、Recommendation(勧告)として発表されたことを示している。
勧告とは、仕様の策定が終了し、W3Cが正式な仕様として認めたということだ。実は、技術文書には以下に示すように、勧告に至る4つのステータスがある。
- 勧告(REC:Recommendations)
- 勧告案(PR:Proposed Recommendations)
- 勧告候補(CR:Candidate Recommendations)
- ドラフト(WD:Working Drafts)
多くの仕様はドラフトの段階でもまれ、勧告候補から勧告案へと進んでいき、最後に勧告となる。もちろん、勧告になった仕様も、その後バージョンアップされていくことになる。
さて、タイトルの下には、その文書の発行された日付などが記されている。ほかの技術文書で使われている項目なども併せて紹介しよう。
- This version=その文書が、更新過程のどの段階のバージョンかを示すURL
- Latest version=その仕様に関する最新バージョンの文書のURL。現在表示している文書が最新バージョンであった場合、参照している文書が同一でも、This versionとLatest versionのURLが異なる場合がある
- Previous version(s)=そのドキュメントの以前のバージョンを示すURL。初登場のドキュメントなら「N/A」
- Editors=そのドキュメントの編集者
- Authors=そのドキュメントの執筆者(XMLのこのドキュメントでは記述されていない)
- Contributors=そのドキュメントへの貢献者(XMLのこのドキュメントでは記述されていない)
仕様書の本文へ
そして、仕様書の本文へ入っていこう。ここからは本格的に英文を読んでいく必要があるが、文書構造はどの技術文書でもほぼ同一である。
- Abstract=その技術の概要。XML 1.0なら「XMLはSGMLのサブセットで……」などの説明がある
- Status of this Document=その文書の背景や、仕様に至る経緯などの説明
- Table of Contents=目次。通常、技術文書は1つのHTML文書として記述されているため、非常に多くの項目が用意されている
Table of Contentsが終われば、仕様の解説が始まる。ここからは仕様ごとにさまざまな解説が行われる部分だ。
XML 1.0の仕様書の読み方
あとは頑張って英文を読もう! という解説ではあまりにも不親切だと思うので、XML 1.0の仕様書の重要な部分を読みこなす手掛かりを紹介する。
XML 1.0の仕様書の中で、XML 1.0の文法を定義しているところは、BNFと呼ばれる式で表現されている。つまり、英語が分からなくても、式さえ読めるようになればある程度の仕様を把握することができるはずだ。
例えば、開始タグの定義と終了タグの定義は、次のようになっている。これを読み解いてみよう。
[40] STag ::= '<' Name (S Attribute)* S? '>' [42] ETag ::= '</' Name S? '>'
STagがスタートタグを表し、ETagが終了タグを表す。先頭に書かれた番号は、仕様書の中に現れる式を区別するための、順番を示す番号だ。
終了タグの方が簡単そうなので、こちらを先に考えてみよう。終了タグは、まず“</”がきて、それに続いて、Nameがきて、Sがきて、“>”がくる、と読める。Nameについては、この仕様書の別の場所で定義されている。
[5] Name ::= (Letter | '_' | ':') (NameChar)*
どうやら、Nameとは、Letterと“_”と“:”とNameCharでできていることが分かる。パイプ記号“|”は、orを表しているので、Letterもしくはアンダーラインかコロン。その後に続いてNameCharが続く、と読める。NameCharの後ろの“*”は、0回以上の繰り返しを表す。
LetterもNameCharも、さらにこの仕様書の別のところに定義されている。
[84] Letter ::= BaseChar | Ideographic [4] NameChar ::= Letter | Digit | '.' | '-' | '_' | ':' | CombiningChar | Extender
これらを併せて考えると、Nameとは、細かい定義は別にして、どうやら文字と数字を組み合わせたもののようだ。では、Sはどうだろう? Sについても定義がある。 実はSは「White Space」の定義、つまり空白を定義している。
[3] S ::= (#x20 | #x9 | #xD | #xA)+
これらを併せてて、もう一度ETagについて考えてみよう。
[42] ETag ::= '</' Name S? '>'
Sの後ろの“?”は、あってもなくてもよいものを示す。つまり、終了タグは、“</”で始まり、文字や数字を組み合わせた名前の後に空白がきて、“>”で終わるもの、ということになる。では、開始タグはどうだろう。
[40] STag ::= '<' Name (S Attribute)* S? '>'
Sの前の“*”は、0回以上の繰り返しを表す。終了タグを読み解いた方法を利用して根気よく理解をつみかさねていけば、概要を把握できるはずだ。
BNFの基本的な読み方は、「BNF記法入門(1) ─XML関連仕様を読むために─」で説明している。これを参考に、XMLの仕様の読解にチャレンジしてみてほしい(残念ながらこの連載は筆者の都合で休止しているのだが)。
W3Cサイトの攻略法、いかがだっただろうか。XML eXpert eXchangeフォーラムでは、W3C/XML Watchという連載で、W3Cで更新されたXML関連情報のダイジェストを毎月お知らせしている。XMLの情報収集にぜひ役立ててほしい。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。