XML SchemaでXML文書の妥当性を検証する:XMLテクニック集(8)(3/3 ページ)
実体参照を使わずに複数のXML文書を結合するには、XPathのdocument関数を使って外部のXMLファイルを取り込みます。この方法の利点は、取り込みの際にフィルタリング処理を加えられることです。
別稿「実体参照宣言を利用して、XML文書を分割管理する」では、分割されたXML文書をDTD(実体参照)を利用して結合する方法を紹介しました。XML文書を分割することによるメンテナンスのしやすさ、ドキュメントの再利用性といったメリットは、そちらでも述べたとおりです。
しかし、実体参照による結合は手軽ではあるものの、柔軟性という意味ではいまいちです。というのも、固定的に記述された実体参照はあくまで「静的な」記述であるため、必ず一度はすべてのデータを取り込まなければなりません。取り込みの際にある条件で抽出を行うような絞り込みはできないのです(表示時にはXSLTでフィルタリングを行うにせよ、それはあくまで一度は結合した後の処理です)。
しかし、本稿のテクニックを用いることで、より柔軟な分割データの処理が可能になります。まずは具体的なサンプルを見てみましょう。サンプルは、取り込むXML文書の一覧を示したインデックスXML(books.xml)、個別のデータ本体を記述したbookX.xml(Xは連番)、そして取り込んだデータを表示するためのXSLTスタイルシート(tabl.xsl)から構成されます。サンプルを試す場合には、books.xmlから起動できます。
[books.xml]
<?xml version="1.0" encoding="Shift_JIS" ?>
<?xml-stylesheet type="text/xsl" href="https://atmarkit.itmedia.co.jp/ait/articles/0312/10/table.xsl" ?>
<books name="書籍情報一覧">
<book href="https://atmarkit.itmedia.co.jp/ait/articles/0312/10/book1.xml" />
<book href="https://atmarkit.itmedia.co.jp/ait/articles/0312/10/book2.xml" />
<book href="https://atmarkit.itmedia.co.jp/ait/articles/0312/10/book3.xml" />
<book href="https://atmarkit.itmedia.co.jp/ait/articles/0312/10/book4.xml" />
<book href="https://atmarkit.itmedia.co.jp/ait/articles/0312/10/book5.xml" />
</books> |
[book1.xml](book2〜5.xmlは同様の構成であるため省略)
<?xml version="1.0" encoding="Shift_JIS" ?>
<book isbn="ISBN4-7981-0189-3">
<title>10日でおぼえるJSP/サーブレット入門教室</title>
<author>Y.Yamada</author>
<published>翔泳社</published>
<price>2800</price>
<publishDate>2002/05/17</publishDate>
<description>サーバサイド技術の雄「<keywd>JSP/サーブレット</keywd>」をJava初心者でもわかる10日間のセミナー形式で紹介。</description>
</book> |
[table.xsl]
<?xml version="1.0" encoding="Shift_JIS" ?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:template match="/">
<html>
<head>
<title><xsl:value-of select="books/@name" /></title>
</head>
<body >
<h1><xsl:value-of select="books/@name" /></h1>
<table border="1">
<tr>
<th>ISBNコード</th><th>書名</th><th>著者</th>
<th>出版社</th><th>価格</th><th>発刊日</th>
</tr>
<xsl:for-each select="document(books/book/@href)/book">
<xsl:sort select="published"
data-type="text" order="descending" />
<xsl:sort select="price"
data-type="text" order="ascending" />
<tr>
<td nowrap="nowrap">
<xsl:value-of
select="@isbn" /></td>
<td nowrap="nowrap">
<xsl:value-of
select="title" /></td>
<td nowrap="nowrap">
<xsl:value-of
select="author" /></td>
<td nowrap="nowrap">
<xsl:value-of
select="published" /></td>
<td nowrap="nowrap">
<xsl:value-of
select="price" /></td>
<td nowrap="nowrap">
<xsl:value-of
select="publishDate" /></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet> |
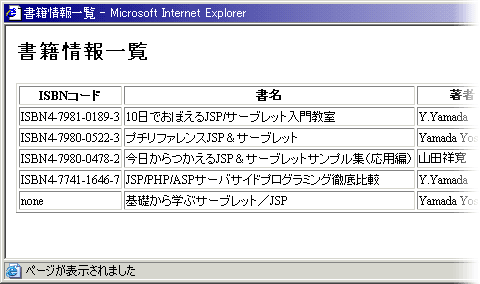 図 books1〜5.xmlの内容を一覧表示(クリックで拡大します)
図 books1〜5.xmlの内容を一覧表示(クリックで拡大します) ポイントとなるのは、以下の部分です。
<xsl:for-each select="document(books/book/@href)/book">
……略……
</xsl:for-each> |
document関数は、XPath関数の中でもノードセット関数に分類される関数の1つで、引数に指定されたパスに合致するノード値をキーに、外部のXML文書を呼び出します。つまり、ここでは<book>要素のhref属性(books.xml)に示されたbookX.xmlを順に呼び出し、その配下の<book>要素について繰り返し処理を行うことを意味します。
ここでは、books.xmlに書かれているものをすべて出力していますが、出力するものとしないものを分けて抽出することも可能です。この場合、books.xmlの各<book>要素にflag属性を追加し、出力したいものにtrue、出力したくないものにfalseと指定します。そのうえで、table.xslの<xsl:for-each>要素を以下のように書き換えます。
<xsl:for-each
select="document(books/book[@flag='true']/@href)/book"> |
すると、flag属性がtrueである文書のみが取り込まれ、一覧表示されます。flag属性がfalseであるものは取り込みそのものが行われませんから、flag属性がfalseである文書が多くなったとしても、処理パフォーマンスが低下することはありません。
Copyright © ITmedia, Inc. All Rights Reserved.





