Mapインターフェイスの実装クラスの違いを知る:JavaTips 〜Javaプログラミング編
JavaのコアAPIに含まれるjava.util.Mapインターフェイスは、キーと値とのマッピングを表すデータ構造のためのインターフェイスです。同パッケージに含まれるListインターフェイスとともに、Javaプログラミングでは非常によく使われるインターフェイスといえるでしょう。
コアAPIには、このMapインタフェース実装クラスがいくつも用意されています。マップというデータ構造は、常にキーを通して値へのアクセスを行うものです。そのため、キーが許容する値やその格納方法などが、個々の実装を特徴付けるポイントになります。
マップの利用頻度は非常に多いだけに、コアAPIで使えるマップの種類を確認しておくのは、効果的なプログラミングへとつながります。ここでは、java.utilパッケージに含まれる5つのMap実装クラス、Hashtable、HashMap、TreeMap、IdentityHashMap、WeakHashMapを取り上げ、それぞれの特徴を解説します。
Hashtableクラス
Javaの1.0より存在する、もっとも古いクラスです。Java 2と呼ばれるようになるJava1.2から、コアAPIにコレクション・フレームワークが導入され、Javaでデータ構造を扱うためのクラス群が刷新されました。Hashtable以外のMap実装クラスはそのときより導入されたものですが、Hashtableは主にJava 2以前のコードとの下位互換性を保つために残されました。
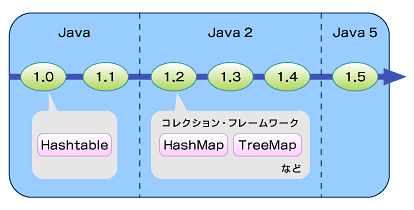
コレクション・フレームワークで導入された新しいクラスとの大きな違いは、同期化の処理が実装されているという点です。つまり、マルチスレッド環境において、複数のスレッドから同時に操作されても、データの整合性を保つことができます。これはメリットにも思えますが、反面1つのスレッドからしか使われないことが分かっている場合でも同期化を行うため、パフォーマンスが低下します。この問題を回避するため、新しいコレクション・フレームワークからは、基本的には同期化は実装せず、必要に応じて同期化ラッパーを追加する(後述)ような形の設計方針になりました。
Hashtableは、同期をとることのほかに、キーや値にnull値を許容しないのも特徴です。ここで取り上げる他のクラスはすべて、null値を許容します。それ以外の点については、次のHashMapクラスと同等です。
HashMapクラス
もっとも一般的なMap実装クラスです。キー、値ともにnull値を許容します。また、このクラスは同期化されていません。そのため、マルチスレッド環境で利用するには、コレクションのためのユーティリティ・クラスjava.util.Collectionsを使って、
Map syncMap = Collections.synchronizedMap(new HashMap(...));
|
というように同期化ラッパーを追加する必要があります。
さらに、このクラスは格納されているキーの順序について何の保証もしません。そのため、キーの順序が重要な場合には、このクラス単体で解決しようとすることはできません。一見、期待通りに並んで見えることもありますが、あくまで偶然と考えなければなりません。
TreeMapクラス
HashMapと同様、キーと値にnull値を許容します。また、同じく同期化されていませんので、マルチスレッド環境下で利用するときは、HashMapと同様の方法で同期化ラッパーを追加します。
このクラスの特徴は、キーがソートされて格納されるという点です。デフォルトのキーの順序は「自然順序付け」、つまり、java.lang.ComparableインタフェースのcompareToメソッドによって定義される順序となります。この順序については、引数にComparatorオブジェクトをとるコンストラクタを用いることで、独自に定義することが可能です。
IdentityHashMapクラス
このクラスも、キーと値にnull値を許容し、同期化は行われません。同期化するには、HashMapと同様に同期化ラッパーを用います。また、TreeMapとは違いキーの順序は保証されません。つまり、これらの点については、HashMapと同じ性質を持ちます。
HashMapとの違いは、名前が示すように、キーの同一性の判定方法にあります。HashMapでは、キーのequalsメソッドを用いて2つのキーが同一かどうかを判定します。一方、このIdentityHashMapでは、キーのオブジェクト同士を「==」演算子を用いて比較します。つまり、2つのオブジェクトが表す値が同じでも、オブジェクトそのものが別であると同一とは見なされません。
例えば、以下のようなプログラムを見てください。
Map map = new IdentityHashMap(); |
HashMapであれば、2回のputメソッド呼び出しでは同一のキーへ値をマップしたことになるので、最初の値が2番目の値で上書きされ、最後のgetメソッドの結果は、「2番目」が返ります。しかし、IdentityHashMapでは、上のオブジェクトi1、i2は別物と見なされますので、2番目のputメソッドで値が上書きされることなく、最後の結果は「1番目」が返されるのです。
WeakHashMapクラス
今回紹介する最後のクラスです。このクラスは、基本的にはHashMapと同じ性質を持ちます。つまり、キーと値にnull値を許容し、同期化が行われません。また、キーの順序も保証されません。
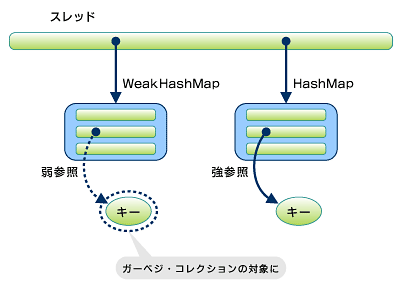
このクラスがHashMapと異なる特徴は、名前が示すように、キーが「弱参照」によって格納されているという点です。そのため、このマップ以外のどこからもキーが参照されなくなると、ガーベジ・コレクションの対象となります。ここで取り上げたその他のMap実装クラスでは、キーは通常の「強参照」によって格納されています。そのため、その他のクラスでは、キーはマップに保持されている限りガーベジ・コレクタに回収されることはありません。
まとめ
以上をまとめると、次の表のようになります。
| 同期化 | null値 | 順序 | 同一性 | キーへの参照 | ||
|---|---|---|---|---|---|---|
| Hashtable | ○ | × | × | equalsメソッド | 強参照 | |
| HashMap | × | ○ | × | equalsメソッド | 強参照 | |
| TreeMap | × | ○ | ○ | equalsメソッド | 強参照 | |
| IdentityHashMap | × | ○ | × | ==演算子 | 強参照 | |
| WeakHashMap | × | ○ | × | equalsメソッド | 弱参照 | |
使い分けとしては、基本的にはHashMapを使い、マッピングの順序が重要な局面でTreeMapを使う、ということになります。マルチスレッド環境では、すでに同期化されているHashtableを使うこともできますが、Hashtableは基本的に下位互換性のために残されているクラスです。従って、新しいクラスに同期化ラッパーを追加する方法をお勧めします。同期化ラッパーを用いた方が、コード中にマルチスレッド環境への配慮があることを明示できることも、新しいクラスをお勧めする理由の1つです。
IdentityHashMapやWeakHashMapは、その特徴からして、適用範囲は特殊な用途に限られます。IdentityHashMapならば、オブジェクトが表す値は同じ(つまりequalsメソッドでの比較結果がtrue)だが、それが生成されたタイミングなどによって区別しなければならないようなものを、キーとして扱う必要がある場合などです。WeakHashMapであれば、マッピングには登録されていても、プログラム中で利用されなくなったオブジェクトはガーベジ・コレクタによって回収されて欲しいような場合です。例えば、プログラム中で生きているすべてのオブジェクトを登録するための、システムのレジストリのような用途には、このクラスは最適です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。