Eclipseのエディタ(正確にはJFaceのテキストエディタ・フレームワーク)ではエディタで編集するドキュメントの内容をorg.eclipse.jface.text.IDocumentという抽象的なオブジェクトとして扱います。IDocumentオブジェクトはドキュメントプロバイダによって提供されます。今回のサンプルではXMLDocumentProviderがドキュメントプロバイダに当たります。
リスト3
public class XMLDocumentProvider extends FileDocumentProvider {
protected IDocument createDocument(Object element)
throws CoreException {
IDocument document = super.createDocument(element);
if (document != null) {
IDocumentPartitioner partitioner =
new FastPartitioner(
new XMLPartitionScanner(), ……(1)
new String[] {
XMLPartitionScanner.XML_TAG,
XMLPartitionScanner.XML_COMMENT });
partitioner.connect(document);
document.setDocumentPartitioner(partitioner);
}
return document;
}
} |
|
ポイントとなるのは(1)でセットしているXMLPartitionScannerです。パーティションスキャナはドキュメントを意味的な区域に分割(パーティショニング)します。パーティショニングされた区域はそれぞれにシンタックスハイライトやコードアシストといった機能を設定することが可能です。Javaエディタを例にすると、Javadoc部分ではJavadocタグのアシスト、Javaコード部分ではJavaコードのアシスト、というようにコンテクストに応じた機能を提供することができます。
XMLPartitionScannerではコメント(XML_COMMENT)、タグ(XML_TAG)およびそれ以外の3つのパーティションに分割します。ではXMLPartitionScannerのソースコードを見てみましょう。
リスト4
public final static String XML_DEFAULT = "__xml_default";
public final static String XML_COMMENT = "__xml_comment";
public final static String XML_TAG = "__xml_tag";
public XMLPartitionScanner() {
IToken xmlComment = new Token(XML_COMMENT);
IToken tag = new Token(XML_TAG);
IPredicateRule[] rules = new IPredicateRule[2];
rules[0] = }
new MultiLineRule("<!--", "-->", xmlComment); ……(1)
rules[1] = new TagRule(tag); ……(2)
setPredicateRules(rules);
}
} |
|
ご覧のとおり、XMLPartitionScannerはRuleBasedPartitionScannerを継承して実装されています。XMLやプログラムのソースコードなど、ルールに基づいたドキュメントをパーティショニングする場合はorg.eclipse.jface.text.rules.RuleBasedPartitionScannerを使用できます。
(1)ではコメント区域のルールをorg.eclipse.jface.text.rules.MultiLineRuleとして定義しています。MultiLineRuleは開始文字列と終了文字列を指定してマッチする部分をパーティションとするルールです。また、(2)ではタグ区域のルールをTagRuleとして定義しています。タグ区域に関してもコメント区域と同じようにnew MultiLineTule("<",">",token)でよさそうな気がしますが、これだとコメントやXML宣言にもマッチしてしまいますのでTagRuleはリスト5のようにMultiLineRuleを継承して独自にマッチングの判定を行うようになっています。
リスト5
public class TagRule extends MultiLineRule {
public TagRule(IToken token) {
super("<", ">", token);
}
protected boolean sequenceDetected(
ICharacterScanner scanner,
char[] sequence,
boolean eofAllowed) {
int c = scanner.read();
if (sequence[0] == '<') {
if (c == '?') { // <の次の文字が?だったらマッチしない
// processing instruction - abort
scanner.unread();
return false;
}
if (c == '!') { // <の次の文字が!だったらマッチしない
scanner.unread();
// comment - abort
return false;
}
} else if (sequence[0] == '>') {
scanner.unread();
}
return super.sequenceDetected(scanner, sequence, eofAllowed);
}
} |
|
これらによってXMLドキュメントは図5のようなパーティションに分割されます。
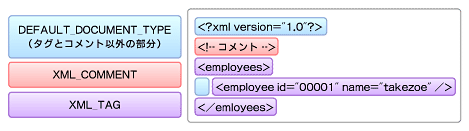 図5 分割後のパーティション
図5 分割後のパーティション SourceViewerConfigurationはエディタの動作をカスタマイズするためのエントリポイントになります。自動生成されたサンプルではXMLConfigurationというorg.eclipse.jface.text.source.SourceViewerConfigurationを継承したクラスが使用されています。このようにSourceViewerConfigurationの各メソッドをオーバーライドすることで、以下のようなエディタの動作をカスタマイズすることができます。
- コードアシスト(入力補完)
- シンタックスハイライト(強調表示)
- ダブルクリック時の動作
- オートインデントの挙動
- ソースコードフォーマッタ(ソースの整形機能)
テンプレートで作成したXMLエディタはコードアシストやソースコードのフォーマットといった機能は備えていません。今回はシンタックスハイライトとダブルクリック時の動作、特にシンタックスハイライトの実装方法について詳しく見ていくことにします(コードアシストの実装については今後の連載で触れる予定です)。
リスト6
public class XMLConfiguration extends SourceViewerConfiguration {
private XMLDoubleClickStrategy doubleClickStrategy;
private XMLTagScanner tagScanner;
private XMLScanner scanner;
private ColorManager colorManager;
public XMLConfiguration(ColorManager colorManager) {
this.colorManager = colorManager;
}
public String[] getConfiguredContentTypes(
ISourceViewer sourceViewer) { ……(1)
return new String[] {
IDocument.DEFAULT_CONTENT_TYPE,
XMLPartitionScanner.XML_COMMENT,
XMLPartitionScanner.XML_TAG };
}
public ITextDoubleClickStrategy getDoubleClickStrategy(
ISourceViewer sourceViewer,
String contentType) { ……(2)
if (doubleClickStrategy == null)
doubleClickStrategy = new XMLDoubleClickStrategy();
return doubleClickStrategy;
}
protected XMLScanner getXMLScanner() {
if (scanner == null) {
scanner = new XMLScanner(colorManager);
scanner.setDefaultReturnToken(
new Token(
new TextAttribute(
colorManager.getColor(IXMLColorConstants.DEFAULT))));
}
return scanner;
}
protected XMLTagScanner getXMLTagScanner() {
if (tagScanner == null) {
tagScanner = new XMLTagScanner(colorManager);
tagScanner.setDefaultReturnToken(
new Token(
new TextAttribute(
colorManager.getColor(IXMLColorConstants.TAG))));
}
return tagScanner;
}
public IPresentationReconciler getPresentationReconciler(
ISourceViewer sourceViewer) { ……(3)
PresentationReconciler reconciler =
new PresentationReconciler();
DefaultDamagerRepairer dr =
new DefaultDamagerRepairer(getXMLTagScanner());
reconciler.setDamager(dr, XMLPartitionScanner.XML_TAG);
reconciler.setRepairer(dr, XMLPartitionScanner.XML_TAG);
dr = new DefaultDamagerRepairer(getXMLScanner());
reconciler.setDamager(dr, IDocument.DEFAULT_CONTENT_TYPE);
reconciler.setRepairer(dr, IDocument.DEFAULT_CONTENT_TYPE);
NonRuleBasedDamagerRepairer ndr =
new NonRuleBasedDamagerRepairer(
new TextAttribute(
colorManager.getColor(IXMLColorConstants.XML_COMMENT)));
reconciler.setDamager(ndr, XMLPartitionScanner.XML_COMMENT);
reconciler.setRepairer(ndr, XMLPartitionScanner.XML_COMMENT);
return reconciler;
}
}
|
|
(1)のgetConfiguredContentType()メソッドでは、エディタがサポートするパーティションのタイプを返すよう実装します。また、(2)のgetDoubleClickStrategy()メソッドではダブルクリック時の動作を決定するorg.eclipse.jface.text.ITextDoubleClickStrategyの実装クラスを返却します。XMLDoubleClickStrategyの実装については本稿では深く触れませんが、ダブルクリックされた位置に応じてダブルクオートで囲まれた区域、もしくは単語を検出して範囲選択を行う実装になっています。そして(3)のgetPresentationReconciler()メソッドでエディタのプレゼンテーション(シンタックスハイライト)に関する設定を行います。
シンタックスハイライトはorg.eclipse.jface.text.presentation.PresentationReconcilerに対してパーティションごとにダメージャとリペアラを設定することで実現しています。PresentationReconcilerはテキストの変更を検出するとまずダメージャを呼び出しダメージ(テキストのプレゼンテーションを更新しなければならない範囲)を算出します。次にリペアラにダメージを通知し、新しいプレゼンテーションを取得します。
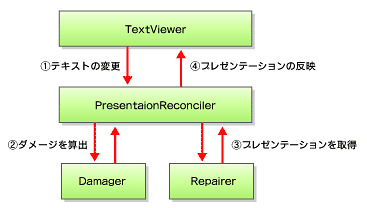 図6 テキスト変更時の処理の流れ
図6 テキスト変更時の処理の流れ 今回の例ではXML_TAG区域、DEFAULT_CONTENT_TYPE区域にはそれぞれXMLTagScanner、XMLScannerがセットされたorg.eclipse.jface.text.rules.DefaultDamagerRepairerが設定されています。XMLTagScannerの実装はリスト7のようになっています。
リスト7
public class XMLTagScanner extends RuleBasedScanner {
public XMLTagScanner(ColorManager manager) {
IToken string =
new Token(
new TextAttribute(
manager.getColor(IXMLColorConstants.STRING)));
IRule[] rules = new IRule[3];
// Add rule for double quotes
rules[0] = new SingleLineRule("\"", "\"", string, '\\');
// Add a rule for single quotes
rules[1] = new SingleLineRule("'", "'", string, '\\');
// Add generic whitespace rule.
rules[2] = new WhitespaceRule(new XMLWhitespaceDetector());
setRules(rules);
}
} |
|
これはXML_TAG区域においてダブルクオートもしくはシングルクオートで囲まれた領域をIXMLColorConstants.STRINGで定義された色でハイライトします。
XMLScannerの実装も類似しています。こちらはDEFAULT_CONTENT_TYPE区域において<?と?>で囲まれた領域をIXMLColorConstants.PROC_INSTRで定義された色でハイライトします。
リスト8
public class XMLScanner extends RuleBasedScanner {
public XMLScanner(ColorManager manager) {
IToken procInstr =
new Token(
new TextAttribute(
manager.getColor(IXMLColorConstants.PROC_INSTR)));
IRule[] rules = new IRule[2];
//Add rule for processing instructions
rules[0] = new SingleLineRule("<?", "?>", procInstr);
// Add generic whitespace rule.
rules[1] = new WhitespaceRule(new XMLWhitespaceDetector());
setRules(rules);
}
} |
|
パーティション内でルールにマッチしなかった部分についてはsetDefaultReturnToken()で指定されたトークンが適用されます。また、XML_COMMENT区域はそれ以上分割する必要はありませんのでNonRuleBasedDamagerRepairerによって区域全体をIXMLColorConstants.XML_COMMENTで定義された色でハイライトします。
テキストエディタの実装には多くのトピックがありますが、特に重要なのは今回重点的に解説したパーティショニングです。本稿で解説したとおり、シンタックスハイライトはパーティショニングされた区域に対して設定を行いますし、コードアシスト機能もパーティションごとにアシストプロセッサを設定することで実現します。本連載では今後、テキストエディタに関するより詳細なトピックにも触れていく予定ですのでご期待ください。
次回はEclipseのプリファレンスAPIを使用して、プラグインの各種設定を保存、読み込みを行う方法について解説したいと思います。




