データへの最短ルートを確保せよ!:データベースエンジニアへの道(5)(2/4 ページ)
テーブルのデータ構成・取得レコード件数に着目しよう
テーブルのデータ構成と取得するレコード件数に着目して、どのようなアクセスパスが適切かを考えましょう。今回は単一のテーブルにアクセスする場合に限って、注意すべきポイントを解説します。
テーブル内のレコード件数の多少、取得件数の多少
レコード件数が多いテーブルから少量のレコード(7%程度)を取得する場合はインデックススキャンが向いていて、そうではない場合はフルスキャンが向いています。アクセスパスの改善というと、すぐにインデックスを使うことが頭に浮かびがちですが、フルスキャンの方が適することもあります。列の値分布に偏りがあるテーブルにアクセスする場合は、検索値によって取得件数が大きく異なるので注意してください。ここでは、フルスキャンを利用する方がよいケースを2つ紹介します。
(1)テーブル内のレコード件数が少ない場合
フルスキャンしたうえで検索結果をメモリに保持すると、SQLを発行する際のディスクアクセスがなくなり、検索速度が向上することがあります。プログラムが頻繁に利用する小規模なマスタテーブルなどでは、この方式を検討するとよいでしょう。
(2)テーブル内のレコード件数も取得件数も多い場合
フルスキャンを選択したうえでパラレルクエリ機能を利用すると、検索速度が向上することがあります。パラレルクエリ機能は、1つのテーブルを検索する作業を複数のプロセスで分担して行う機能のことです(図3)。バッチ処理によりテーブル内の大部分のレコードにアクセスする場合には、この方式を検討するとよいでしょう。
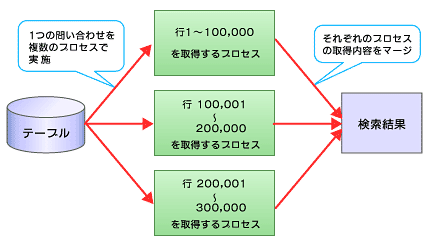 図3 パラレルクエリの動作
図3 パラレルクエリの動作カーディナリティの高低
カーディナリティとは列値の種類の多少を示す言葉です。性別には男/女の2種類しかないといったように、列値の種類が少ないことを「カーディナリティが低い」といいます。
カーディナリティが低い列を条件に検索する場合、検索件数が多くなりがちです。この場合、ビットマップインデックスという特殊なインデックスを用いるとよい場合があります。ビットマップインデックスは、通常のBツリーインデックスに比べデータサイズが小さく注2、さらにほかの列のビットマップインデックスと組み合わせた検索でも利用できます。
ただし、ビットマップインデックスは、テーブルに挿入・更新がある場合、インデックス全体がロックされてしまいます。また、メンテナンスに時間がかかることも多いです。従ってオンライン処理でテーブルに挿入・更新が頻繁にある場合には不向きです。
注2:ビットマップインデックスでは、インデックスのキー値をビット(0、1)列で表現し、ROW_IDも行数分は保存しないためサイズがコンパクトになる。
レコードの並び順
データがどのように整列されているか(ソート状況)は、最適なアクセスパスを見つけ出すうえで重要な要素です。ある列に作成されたインデックスを利用して範囲検索を行う場合、レコードがインデックス・キー値の順に並んでいると、ディスクアクセスの回数が減り、インデックスを利用する効果が向上します(図4)。
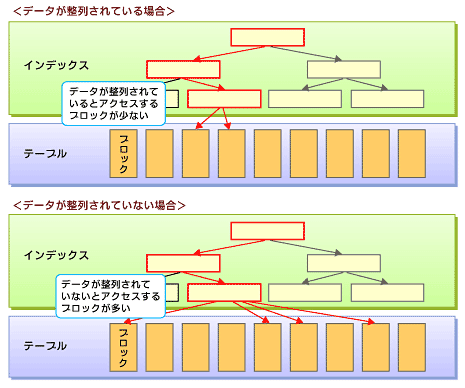 図4 データのソート状況によるアクセスパスの違い
図4 データのソート状況によるアクセスパスの違い図4から分かるようにインデックスのキー順にレコードが並んでいると、検索されるレコードの割合が多い場合(40%程度)でも、インデックスを利用するメリットが生まれます。索引構成表注3を利用したり、テーブルのレコード順序を再編成注4したりすると、図4の<データが整列されている場合>のようなアクセスパスが実現できます。そのテーブルにアクセスするSQL群がどのような検索条件を使用しているかをチェックして、最適なレコード順序を選んでください。
注3:索引構成表
Bツリーインデックスでリーフブロックにレコードデータそのものが格納されているテーブル。
注4:レコード順序を再編成
既存のテーブル内のレコードを特定の列でソートしたうえで別の領域にコピーすると、テーブル内のレコードを物理的に並べ替えることができる。
挿入の頻度
挿入頻度が高いテーブルにSQLを作成する場合は、挿入処理の影響を考慮してインデックスを設計する必要があります。ここでは2つポイントを紹介します。
(1)ビットマップインデックスを利用する場合
上述した内容と重なりますが、ビットマップインデックスの場合、レコードの挿入・更新時にインデックス全体がロックされてしまいます。従ってオンライン処理がレコードの挿入・更新を行う場合は、ビットマップインデックスの利用は避けるべきです。
(2)Bツリーインデックスキーが連番で作成される場合
あるテーブルのインデックスのキーが連番で作成されるケースを考えます。もしこのテーブルに頻繁に挿入が行われる場合、インデックスの同じリーフブロックにアクセスが集中し、パフォーマンスが劣化することがあります。この場合、キーの値を逆に保管する逆キーインデックスを利用すると、挿入のI/Oを分散できます。ただし、逆キーインデックスは範囲検索には利用されないので注意してください。
Point
- テーブル内のデータ構成・検索するデータ量とアクセスパス
- 大きなテーブルから少量のデータを検索する場合はインデックススキャンが有効
- フルスキャンを行う場合は、キャッシュやパラレルクエリ機能を利用するとアクセスパスが改善することがある
- 列値のカーディナリティが低い場合、ビットマップインデックスを用いるとアクセスパスが改善することがある
- レコードの並び順は、範囲検索時のアクセスパスに影響を与える
- 挿入の頻度が高い場合、インデックスにデータを挿入するI/Oがパフォーマンス劣化を招くことがあるので、インデックスを追加する場合は注意が必要
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。