綱引きに蛇口当てゲーム?! 楽しく学ぶベイズフィルターの仕組み:スパム対策の基本技術解説(2/4 ページ)
メールの特徴抽出——単語の詰まった袋をモデルとして
コンピュータ上でスパム判定を行うためには、まず、判断の材料になるメールの特徴を取り出さなくてはなりません。
あるメールがスパムであるか否かを判断するのに必要な特徴とはなんでしょう。特徴には、メールの長さや、言語、配送元の国、HTMLメールの有無などさまざまな要素を盛り込めますが、多くのスパムフィルターでは、単語などトークンの出現頻度をメールの特徴としています。このように、文書を語の並びを無視して単語の詰まった1つの袋としてモデル化したものを“bag-of-words”といいます。
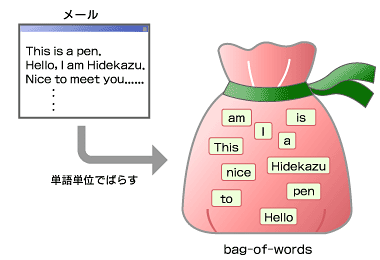 図2 単語が詰まった袋、bug-of-words
図2 単語が詰まった袋、bug-of-words基本理論:ベイズの定理とその解釈
まずは、ベイズの定理を用いたスパムの確率計算の式を書き下してみます。
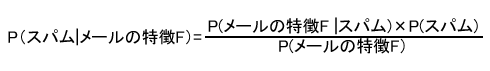
- メールの特徴Fは、bag-of-wordsを用いると、今注目しているメールに現われる単語の集まりになります。
- P(スパム)は、あるメールがスパムである確率です。そのメールの特徴Fを観察する前の確率を表しているため、事前確率と呼びます。P(スパム)の値には、例えば、いままでに手元に届いたメールのうち、スパムであったメールの割合を用いたり、事前に何も情報がない場合は、五分五分でスパムが届くとして、2分の1にしたりします。
- P(スパム|メールの特徴F)は、あるメールの特徴Fを見たときに、そのメールがスパムである確率で、事後確率と呼びます。
- P(メールの特徴F|スパム)は、スパムにメールの特徴Fが現れる確率です。メールの特徴Fを持つメールがスパムである尤も(もっとも)らしさを表す尺度で、メールの特徴Fのスパムにおける尤度(ゆうど)と呼びます。
- P(メールの特徴F)は、スパムと非スパムを合わせた全メール中に、メールの特徴Fを持ったメールが出現する確率です。
これはもとをただせばただの条件付き確率の式ですが、さまざまな解釈ができます。1つの見方は、メールがスパムである確率P(スパム)は、届いたメールの特徴Fを観察することにより、より正確な値P(スパム|メールの特徴F)へと改善されるという見方です。

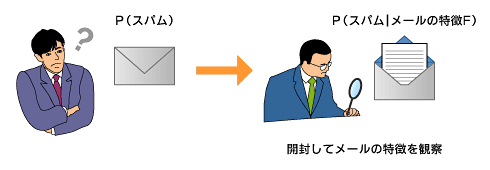 図3 開封してメールの特徴を観察することで、より正確なスパムらしさを算出できる
図3 開封してメールの特徴を観察することで、より正確なスパムらしさを算出できる ベイズの定理を「直感的に」解釈する
計算式が出てきたところで、ベイズの定理を直感的に解釈してみましょう。式の分子に注目してください。特徴Fを持つメールがスパムである確率P(スパム|メールの特徴F)が大きくなるのは次の2つのケースです。
- メール全体でスパムの占める割合が増えるとき( つまり、P(スパム)の増加)
- 特徴Fを持つスパムの割合が増えるとき(つまり、P(メールの特徴F|スパム)の増加)
特徴Fを持つスパムの割合が増えれば、特徴Fを観察したときに、そのメールがスパムである割合も増えます。
ところで、なぜベイズの定理を利用するのでしょうか。特徴Fを持つメールがスパムである確率を求める場合、通常であれば世界中のメール群から同じ特徴Fを持つメールがスパム、非スパムである確率を計算しなければなりません。あなたのメールボックスに世界中のメールが転送されてくるなら話は別ですが、これはどう考えても現実的でありません。
そこでベイズの定理を用いると、それよりは現実的に計算できそうな式が出てくるというわけです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。