Eclipseで作る! DBを使った実践的なJavaバッチ:Javaバッチ処理は本当に業務で“使える”の?(3)(2/3 ページ)
「チャンク」? 「コレクタ」?? 「ワーカ」???
ジョブBean定義ファイルに「ひな型ファイル」をインポートします。ひな型ファイルの説明は前回説明したとおり、バッチ処理において想定される処理形態に必要なBean定義の記述をまとめたものです。インポートするひな型ファイルを切り替えることによって、フレームワークの動きを切り替え可能です。
今回は、「DB to DB」の処理なので「一定件数ごとにコミット」を行う「チャンク別トランザクション」モデルのひな型をインポートします。「チャンク」とは入力データを一定個数分まとめたもので、フレームワークが制御するトランザクション単位となるものです。
ここで重要なことは、トランザクションはフレームワークにて一括で制御されているため業務開発者がトランザクションの制御を意識する必要がないということです。チャンクは対象データ取得処理(「コレクタ」と呼ぶこともあります)の際に作成され、業務処理(「ワーカ」と呼ぶこともあります)に渡されます。業務処理はチャンクに含まれるデータ1件ごとにビジネスロジックを起動しますが、トランザクションはチャンク単位を基本として制御されます。
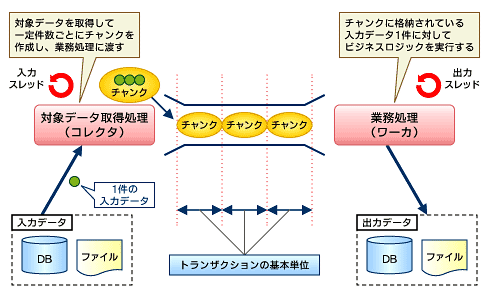 図4 TERAバッチにおけるチャンクの考え方
図4 TERAバッチにおけるチャンクの考え方先ほど作成したジョブBean定義ファイルの<beans></beans>ネスト内に以下の定義を追加します。
<!-- トランザクションモデル別Bean定義ファイルの --><import resource="classpath:template/ChunkTransactionBean.xml"/> <!--SqlMapConfig--> <bean id="sqlMapConfigFileName" class="java.lang.String"> <constructor-arg value="sample/UC0002/UC0002_sqlMapConfig.xml"/> </bean> |
チャンクを作成する入力データ件数はデフォルトでは20件です。今回は説明を割愛しますが、この件数を変更することもできます。詳細はSourceForgeから取得できるTERAバッチの機能説明書をご覧ください。
また、チャンク単位でトランザクションを切らずに業務処理の最初にトランザクションを開始し、最後にトランザクションを終了する処理モデル(単一トランザクションモデル)も提供されています。
ジョブコンテキストの作成
「ジョブコンテキスト」とは、ジョブの前処理、主処理、後処理、といったそれぞれの処理の間で持ち回る情報を格納したクラスで、「jp.terasoluna.fw.batch.openapi.JobContext」を継承して作成します。
今回は、主処理で処理件数のカウントアップを行い、後処理で処理件数の出力を行うために利用します。「source」フォルダ配下に「jp.terasoluna.batch.sample.uc0002.JB0001JobContext.java」を以下のとおり作成します。
package jp.terasoluna.batch.sample.uc0002; |
上記のとおり、値だけではなく、簡単な処理を定義することもできます。
また、ジョブBean定義ファイルに上記で作成したジョブコンテキストを利用する定義を追加します。以下の定義を<beans></beans>ネスト内に追記してください。
<!--ジョブコンテキスト--> |
対象データ取得処理はコーディングレスです
前回、「対象データ取得処理はコーディングレス」と述べましたが、これはDBからデータを取得する場合でも同様です。
業務開発者は簡単な設定ファイルの記述、業務入力クラスを作成するだけで、対象リソースからのレコード読み取り、業務入力クラス(JavaBean)への値詰め替え、ビジネスロジックの呼び出しができます。では、これから業務入力クラスの実装と、対象データ取得処理の設定を行っていきます。
業務入力クラスを作成
まず、業務入力クラスを作成します。「source」フォルダ配下に、「jp.terasoluna.batch.sample.uc0002.JB0001nyukinData.java」を以下のとおり作成します。
package jp.terasoluna.batch.sample.uc0002; |
上記のとおり、ファイルを入出力する処理と異なり、DBを利用する処理の場合はアノテーションの記述は必要ありません。これは、DBから取得した1レコードのそれぞれのフィールドの値を、iBATISが自動的にO/Rマッピングしているためです。マッピング情報については、iBATIS定義ファイルの中に記述することになります。
編集部注:アノテーションについて詳しく知りたい読者は、記事「J2SE 5.0「Tiger」で何が変わるか?」を、O/Rマッピングについては、「O/Rマッピングの役割とメリット」を、それぞれご参照ください。
対象データ取得処理の設定
では、次に対象データ取得処理の設定をしていきます。
まず、対象データ取得時に使用するSQLを「UC0002_sqlMap.xml」に定義します。<sqlMap></sqlMap>のネスト内に、以下のSQL文の定義を追加します。
<!-- 対象データ取得処理 --> |
<select></select>のネストの中にselect文を記述します。idはそのsqlMapファイル内でSQL文を一意に識別するもので、任意に付与できます。今回は「getNyukinData」としました。resultClassには、SQL実行結果1件の情報を格納する業務入力クラスを完全修飾名で指定します。
DBのカラム名とJavaのフィールド名が一致した場合、自動的にSQL実行結果がJavaフィールドにマッピングされます。もし、カラム名とフィールド名が一致しなかった場合でも、「AS句」を利用することで対応可能です。
次に、ジョブBean定義ファイルに対象データ取得処理の定義を追加します。利用するコレクタの定義を、先ほど追加したジョブコンテキストの定義の下に追加します。
<!--コレクタ定義--> |
今回は、DBからの読み込みなので、「対象データ取得処理(コレクタ)」として「IBatisDbChunkCollector」を利用します。Property要素のvalue属性に利用するSQL文を指定します。指定方法は、「<namespace>.<id>」なので、「UC0002.getNyukinData」となります。name属性の「sql」は、TERAバッチが定義している属性であるため、変更してはいけません。
以上で、入力処理(対象データ取得処理)の実装は完了です。
いよいよ次ページは、SpringのDIを使ったビジネスロジックを実装し、Eclipse上で実際に動かしてみます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。