いまさら聞けないKVSの常識をHbaseで身につける:ビッグデータ処理の常識をJavaで身につける(3)(2/3 ページ)
HadoopファミリのKVS「Hbase」とは
Hbaseとは、Hadoopの中核技術であるHDFS上に構築されたKVS形式の分散データベースです。
Hbaseを使うときの注意点は、Hbaseのバージョンに合ったHadoopを使用しなければなりません。HbaseとHadoopはバラバラにバージョンが変わるので、注意してください。
Hbaseは、RDBと同じようにテーブルを作成してカラムの中にデータを格納しますが、RDBとはちょっと違います。
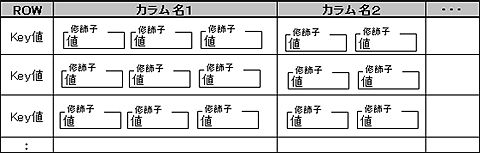
- Key値を格納するROWが自動的に作られる
- カラムは「カラムファミリ」と呼ばれる
- 「カラム名:修飾子」で指定するセルにデータを格納
- データ型はbyte[]だけ
- 履歴が一定数だけ保存される
テーブル構造でRDBと一番違うのは、カラムファミリです。カラムに対して1つのデータだけを格納するのではなく、「カラム名:修飾子」で指定するセルにデータを格納します。修飾子は後で自由に指定できるので、RDBを使っていてよくある「ALTER TABLEでカラムを追加する」ことは、あまりありません。
それから、Hadoopのファイルシステムである「HDFS」は、ファイルを置くたびにメモリ上で管理しているメタデータが増えるため、NameNodeのメモリサイズによって格納できるファイル数が決まってしまいます。そのため、大量の小さなファイルを格納するのが得意ではありません。
おわびと訂正のお知らせ
上記HDFSの説明について、「ブロックサイズがデフォルトで64Mbytesのため、たとえ数バイトのファイルを置いただけでも、HDDを64Mbytesも使用してしまいます。そのため、Hadoopの入力ファイルの置き場所としてHDFSを使った場合、多数の小さなファイルを置くのはHDDの利用効率が悪いです」と表記するなど、間違いがあり、修正しました。
内容について正確を期せずに混乱を招いた点、読者の皆様におわび申し上げます(2012年2月28日)。
しかしHbaseでは、格納先としてHDFSを使用しつつ、多数の小さなデータを効率よく格納できます。この特徴を生かし、Hadoopの入出力先としてHbaseを利用することで、Hadoopの不得手な部分を補完できます。
今回は、JavaのAPIを使って実際にアクセスしてみることで、Hbaseの構造や特徴の理解を深めていきます。まずは、Hbaseをスタンドアロンモードで動かし、Java APIからアクセスしてみます。
Hbaseをインストールして使ってみよう
Hbaseを分散モードで動かすには、分散モードで動作するHadoop上に構築する必要があります。ですが、単に動作確認するだけであれば、Hbaseのスタンドアロンモードで動かす方が簡単です。
Hbaseは、ダウンロードサイトからダウンロードしてインストールできます。ここでは、「hbase-0.92.0.tar.gz」を使いました。
JDKをインストールして環境変数「JAVA_HOME」を設定すると、以下のコマンドで起動できます。念のために、root以外の通常ユーザーで設定してください。
wget http://ftp.riken.jp/net/apache//hbase/hbase-0.92.0/hbase-0.92.0.tar.gz tar xvfz hbase-0.92.0.tar.gz # 解凍 export HBASE_HOME=$HOME/hbase-0.92.0 export PATH=$HBASE_HOME/bin:$PATH start-hbase.sh # 起動
以下のコマンドで停止します。
stop-hbase.sh # 停止
無事にHbaseが起動したら、Webブラウザで「http://localhost:60010/」にアクセスすると、動作状況が確認できます。
デフォルトでは、「/tmp/hbase-ユーザー名」の下にデータファイルを保存します。Hbaseを完全にリセットしたい場合には、Hbaseを停止してディレクトリごと削除してください。
また、大量のデータを登録する場合や、次回以降もデータを残しておきたい場合には、データファイルの保存場所を変更します。
<property>
<name>hadoop.tmp.dir</name>
<value>/home/ユーザー名/hdfs</value>
</property>
コラム「Windows+Cygwinで動かす方法」
普段の開発環境がWindowsであれば、HbaseもWindows上で動作できた方が開発&テストがしやすくなります。しかし、HbaseはLinux+JDKを前提に開発されているので、Windows+Cygwin+JDKではいろいろな問題が起こってしまいます。
もし、どうしてもWindows上で動かしたい場合には、Cygwin Terminalから改行コードの扱いを変更してから、Hbaseを実行すれば、スタンドアロンモードで起動できます。
$ set -o igncr $ export SHELLOPTS
また、ログオン名にスペースや日本語が入っている場合、以下の修正も行ってください。
# export HBASE_IDENT_STRING=$USER
export HBASE_IDENT_STRING=$HOSTNAME
それから、使用するCygwinのバージョンによっては、後で紹介する「hbase shell」や「hbase rest stasrt」がうまく動作しないので、利用に際しては注意が必要です。
シェルでHbaseの動作確認
Hbaseには、クライアントのシェル環境が標準で付いており、簡単に試せます。
$ hbase-0.92.0/bin/hbase shell
このシェルは、実はJRubyのインタプリタなので、Rubyで複雑な処理も記述できます。そこで、以下の処理を実行してみます。
- 「t1」というテーブルを作成
- 「data.csv」という4行のレコードを書いたファイルを読んで、「t1」に格納
name,address,email,age
namae1,adress1,email@email1,31
namae2,adress2,email@email2,32
namae3,adress3,email@email3,33
namae4,adress4,email@email4,34
1行目はタイトル行ですが、コードが複雑になってしまうので、今回は他の行と同じように扱います。
$ hbase-0.92.0/bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.92.0, r1231986, Mon Jan 16 13:16:35 UTC 2012
# テーブル作成
hbase(main):001:0> create 't1', 'csv'
0 row(s) in 2.2680 seconds
# ファイルを読み込む処理をRubyで記述
hbase(main):002:0> count = 0
=> 0
hbase(main):003:0> IO.foreach("data.csv") do |line|
hbase(main):004:1* line = line.gsub("\n", "")
hbase(main):005:1> count+=1
hbase(main):006:1> i = 0
hbase(main):007:1> for col in line.split(",")
hbase(main):008:2> put 't1', 'row-'+count.to_s, 'csv:'+(i+=1).to_s, col
hbase(main):009:2> end
hbase(main):010:1> end
0 row(s) in 0.1440 seconds
0 row(s) in 0.0040 seconds
:
インタプリタなので、最後の「end」を入力すると自動的に実行されます。ちゃんと入っているか確認してみます。
hbase(main):011:> count 't1'
5 row(s) in 0.0480 seconds
タイトル行も登録したので、5件と表示されています。中身についても確認してみます。
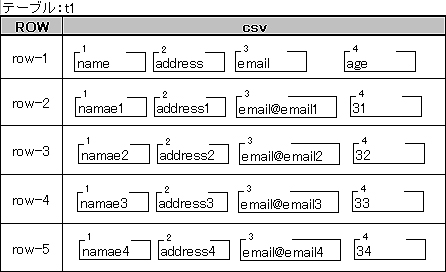
hbase(main):012:0> scan 't1'
ROW COLUMN+CELL
row-1 column=csv:1, timestamp=1329375338202, value=name
row-1 column=csv:2, timestamp=1329375338218, value=address
row-1 column=csv:3, timestamp=1329375338223, value=email
row-1 column=csv:4, timestamp=1329375338228, value=age
row-2 column=csv:1, timestamp=1329375338233, value=namae1
row-2 column=csv:2, timestamp=1329375338238, value=adress1
row-2 column=csv:3, timestamp=1329375338244, value=email@email1
row-2 column=csv:4, timestamp=1329375338249, value=31
row-3 column=csv:1, timestamp=1329375338254, value=namae2
:
5 row(s) in 0.0610 seconds
最初のROWがKey値です。カラムファミリ内のセルごとに出力されるので、1つのKey値に対して複数行が出力されます。
「column = 」は、カラムファミリ名+修飾子です。「timestamp = 」は、登録した標準時(1970年01月01日 00:00:00 GMT)からのミリ秒です。「value = 」がセルの中身です。値が「半角英数文字列」以外は正しく見えないので、最初は半角英数のみを入れると確認がしやすいです。
確認が終わったら、テーブルごと削除します。
hbase(main):013:0> disable 't1'
0 row(s) in 2.2700 seconds
hbase(main):014:0> drop 't1'
0 row(s) in 1.4700 seconds
注意:使用するJDKのバージョンによっては、50件以上を登録しようとすると、OutOfMemoryErrorが出ます。その場合には、シェル起動時のJavaのオプションを追加してください。
export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
export HBASE_OPTS="-Xss128k $HBASE_OPTS"
次ページでは、JavaプログラムからHbaseを操作します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。