Hadoopの現実解「バッチ処理」の常識をAsakusaで体得:ビッグデータ処理の常識をJavaで身につける(7)(3/4 ページ)
8ステップで行うAsakusaFWを使ったバッチの実装
今回作る簡単なバッチ処理は、WindGateを使用して、CSV形式のファイルを入出力とします。
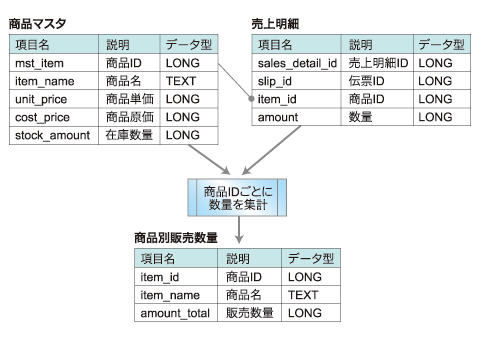 例題:2つのCSVファイル(商品マスタ、売上明細)を使用して、商品別販売数量を算出してみましょう
例題:2つのCSVファイル(商品マスタ、売上明細)を使用して、商品別販売数量を算出してみましょうこんな簡単な例なら、「SQLで集計してしまえばすぐできるじゃないか」と思われたかたも多いと思います。実は、AsakusaFWは、そう思われた方に向いています。AsakusaFWでは、このようなテーブルの結合や集計処理は、DDLのViewや、DMDLの結合モデルや集計モデルで定義できてしまいます。
今回は、下記のフローで示すように、まず「商品マスタ」「売上明細」の結合モデルを作成して、その結合モデルを集計するバッチを作成してみます。
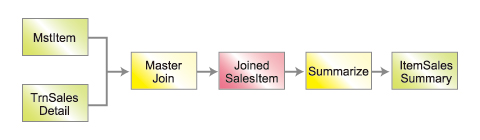
下記の手順で実装していきます。
- 入力データモデルの定義
- 結合モデルの定義
- MasterJoin演算子を使用したOperator DSLの記述
- 単純集計モデルの定義
- Summarize演算子を使用したOperator DSLの記述■
- Expoerter/Importerの記述
- ジョブフローの記述
- バッチの記述
【1】入力データモデルの定義
プロジェクトの「src/main/dmdl」の下に、任意の名称で拡張子を「.dmdl」としたファイルを作成して、「商品マスタ」と「売上明細」をDMDLで定義します。下記の例では、定義ファイルの名前を「models.dmdl」としています。
"商品マスタ"
@windgate.csv(has_header = TRUE)
mst_item = {
"商品ID"
@windgate.csv.field(name = "ITEM_ID")
item_id : LONG;
"商品名"
@windgate.csv.field(name = "ITEM_NAME")
item_name : TEXT;
"商品単価"
@windgate.csv.field(name = "UNIT_PRICE")
unit_price : LONG;
"商品原価"
@windgate.csv.field(name = "COST_PRICE")
cost_price : LONG;
"在庫数量"
@windgate.csv.field(name = "STOCK_AMOUNT")
stock_amount : LONG;
};
"売上明細"
@windgate.csv(has_header = TRUE)
trn_sales_detail = {
"売上明細ID"
@windgate.csv.field(name = "SALES_DETAIL_ID")
sales_detail_id : LONG;
"伝票ID"
@windgate.csv.field(name = "SLIP_ID")
slip_id : LONG;
"商品ID"
@windgate.csv.field(name = "ITEM_ID")
item_id : LONG;
"数量"
@windgate.csv.field(name = "AMOUNT")
amount : LONG;
};| 項目名 | 説明 | データ型 |
|---|---|---|
| sales_detail_id | 売上明細ID | LONG |
| amount_total | 販売数量 | LONG |
| item_id | 商品ID | LONG |
| item_name | 商品名 | TEXT |
DMDLでは、定義済みのデータモデルを組み合わせて新しいモデルを作成できます。結合モデルは、下記のように定義します。
1 "売上伝票+商品マスタ"
2 joined joined_sales_item
3 = trn_sales_detail -> {
4 sales_detail_id -> sales_detail_id;
5 amount -> amount;
6 item_id -> item_id;
7 } % item_id
8 + mst_item -> {
9 item_id -> item_id;
10 item_name -> item_name;
11 } % item_id;
- 2行目:joined 新しいモデル=既存のモデル1+既存のモデル2
- 3〜6行目:売上伝票から取り出したい項目を指定
- 4行目:プロパティマッピング右辺が新しいモデルでの呼び名
- 8〜10行目:商品マスタから取り出したい項目を指定
- 7・11行目:結合キーを指定
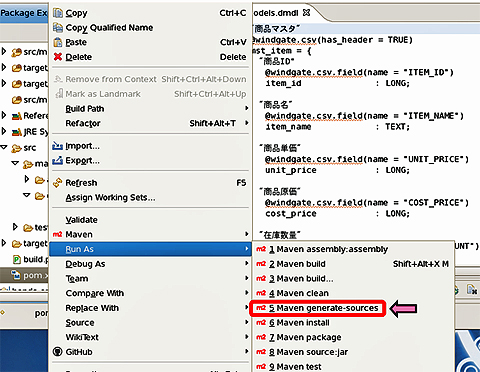
models.dmdlに上記の結合モデルを追記して、データモデルクラスを生成してみましょう。pom.xmlを右クリックして、[Run As]→[Maven generate-source]を実行してください。
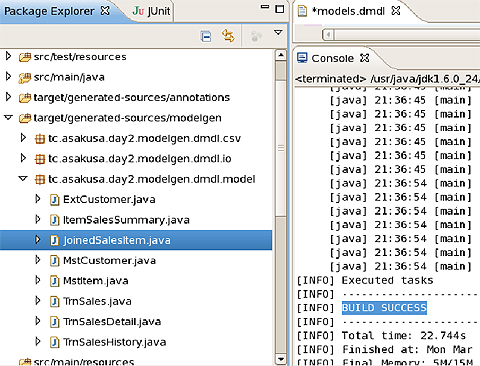
コンソールに「BUILD SUCCESS」と表示されたら、「target/generated-sources/modelgen」の下にデータモデルクラスや入出力ドライバが生成されています。先ほど定義したJoindSalesItemのデータモデルクラスが生成されているか確認してみましょう。
【3】マスタ結合演算子を使ったOperatorの記述
マスタ結合演算子は、抽象メソッドとして宣言し、引数と戻り値にデータモデルを指定するだけでメソッド本体の実装は不要です。
【4】単純集計モデルの定義
【2】で作成した結合モデル「joined_sales_item」を基に商品ごとに販売数量を集計するモデルを定義してみましょう。
| 集約関数 | 性質 |
|---|---|
| any | グループ化した中のいずれか1つの値を利用(注1) |
| sum | グループ化した中の値の合計を利用(注2) |
| max | グループ化した中の最大値を利用 |
| min | グループ化した中の最小値を利用 |
| count | グループ化した中の個数を利用 |
| 表2 | |
"商品毎の販売数量"
@windgate.csv(has_header = TRUE)
summarized item_sales_summary = joined_sales_item => {
@windgate.csv.field(name = "商品ID")
any item_id -> item_id ; // 表2の注1
@windgate.csv.field(name = "商品名")
any item_name -> item_name ; // 表2の注1
@windgate.csv.field(name = "販売数量")
sum amount -> amount_total; // 表2の注2
} % item_id ; // グループ化キー(ここで指定した項目単位で集計を行う)
models.dmdlに上記の単純集計モデルを追記して、データモデルクラスを生成してみましょう。pom.xmlを右クリックして、[Run As]→[Maven generate-source]を実行してください。
【5】単純集計演算子を使ったOperatorの記述
結合演算子を記述する際に作成したItemSalesSummaryOperatorクラスに単純集計演算子のメソッドを追加します。単純集計演算子も結合演算子と同様、抽象メソッドとして宣言し、引数と戻り値にデータモデルを指定するだけでメソッド本体の実装は不要です。
ここまでできたら、OperatorFactoryクラス及び、OperatorImplクラスを生成するために、もう一度、[Maven generate-source]を実行してください。コンソールに「BUILD SUCCESS」と表示されたら、「target/generated-sources/annotations」の下に「〜Factory」クラスと「〜Impl」クラスが生成されていることを確認してください。

【6】Expoerter/Importerの記述
Importerは、ジョブの入力ファイルの定義、Exporterは、ジョブの出力ファイルの定義です。Exporter/Importerは、JobFlowのパッケージに記述します。
さて、ここで1つ疑問になると思いますが、入出力ファイルは、いったいどこにあるのでしょうか?
getPath()メソッドで、どこからかの相対パスを返すようになっていますが、親のディレクトリがどこにあるのか、分かりません。getPath()に絶対パスを記載しても動作はするのですが、開発環境と本番環境でデータの格納場所が異なったりすると面倒です。
親ディレクトリは、WindGateの設定ファイル「$ASAKUSA_HOME/windgate/profile/asakusa.propertiesのresource.local.basePath」で指定できます。デフォルト値は、「/tmp/windgate-${USER}」になっているので、開発環境の場合は、cronにテストデータを削除されてしまわないように、「/tmp」「/var」以外に変更しておいた方が無難だと思います。
## Core
core.maxProcesses=4
## Resources
# Local File System
resource.local=com.asakusafw.windgate.stream.file.FileResourceProvider
resource.local.basePath=/tmp/windgate-${USER}
# JDBC
#resource.jdbc=com.asakusafw.windgate.jdbc.JdbcResourceProvider
#resource.jdbc.driver=org.postgresql.Driver
:
:
:次ページでは、いよいよジョブフローの定義を行います。ビルドしてデプロイして実行してみましょう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。