データをグループ化して表示してみよう(1):Webブラウザで気軽に学ぶ実践SQL講座(9)
前回は、SQLの複雑な自己結合や外部結合について説明しました。今回はグループ関数を使った集計結果について説明します。グループ関数を使うと、行毎ではなく、表全体のデータを集計した結果を求めることができます(編集部)
グループ関数とは
連載第5回では「単一行関数」を紹介しました。単一行関数を使うと、数値データを四捨五入したり、文字データから特定の文字列を取り出したりして表示することができます。単一行関数は、名前の通り、行ごとにデータを加工して表示する関数です。例えば、20人の社員情報が入っているEMP表に対して単一行関数を使うと(給与を四捨五入するなど)、20行の結果が表示されます。
一方、社員単位ではなく、社員全員や部門ごとの合計給与や平均給与を求めたい場合には、グループ関数を使用します。グループ関数を使うと、1つ1つの行ではなく、表全体のデータを集計した結果を求めることができます。
代表的なグループ関数には、以下のようなものがあります。
| グループ関数 | 説明 |
|---|---|
| MAX | 対象列のデータのうち、最大値を戻す |
| MIN | 対象列のデータのうち、最小値を戻す |
| AVG | 対象列のデータの、平均値を戻す 数値データ型に対してのみ使用可能 |
| SUM | 対象列のデータの、合計値を戻す 数値データ型に対してのみ使用可能 |
| COUNT | 問合せによって戻された行の数を戻す |
| 表1 | |
グループ関数の使い方は、単一行関数の使い方と同じです。集計処理をしたい列の前に、関数を指定します。
SELECT 関数(列名), 関数(列名), … FROM 表名 ・・・
EMP表の確認
今回も、EMP表を使って考えてみましょう。グループ関数を使った集計結果を確認するために、EMP表の全てのデータを以下に示します。以降の実行結果と比べてみてください。
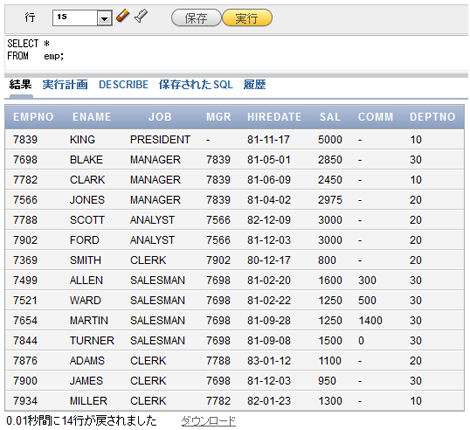 図1 EMP表の全てのデータ
図1 EMP表の全てのデータグループ関数を使ってみよう
それでは、表1のグループ関数を使って、EMP表の全社員の給与から、最大値、最小値、平均値、合計を求めてみましょう。
SELECT MAX(sal), MIN(sal), TRUNC(AVG(sal)), SUM(sal) FROM emp;
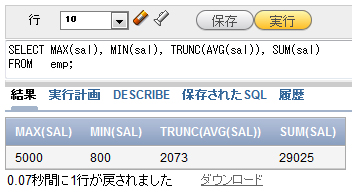 図2 全社員の給与の最大値、最小値、平均値、および合計を表示
図2 全社員の給与の最大値、最小値、平均値、および合計を表示図2の実行例では、平均値を求めるAVG関数の結果が小数になるため、単一行関数TRUNC(切り捨て)を使って小数以下を切り捨てています。このように、単一行関数とグループ関数は組み合わせて使うことができます。AVG関数とSUM関数は数値データに対してしか使うことができませんが、MAX関数とMIN関数は、文字データや日付データに対しても使うことができます。
次の例では、社員名、および入社日に対してMAX関数とMIN関数を使用しています。それぞれ昇順に並べた場合の最小値と最大値が表示されています。
SELECT MAX(ename), MIN(ename), MAX(hiredate), MIN(hiredate) FROM emp;
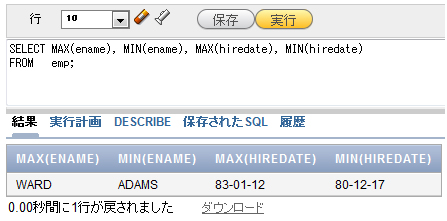 図3 全社員の社員名および入社日の最大および最小を表示
図3 全社員の社員名および入社日の最大および最小を表示データ件数を数えてみよう
COUNT関数を使うと、データが何行あるかを数えることができます。次の例では、EMP表の総行数、ENAME列に格納されたデータの行数、COMM(歩合給)列に格納されたデータの行数を検索しています。
SELECT COUNT(*), COUNT(ename), COUNT(comm) FROM emp;
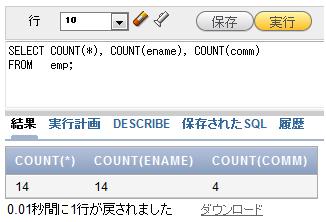 図4 全社員の総数、ENAME列の総行数、COMM列の総行数を表示
図4 全社員の総数、ENAME列の総行数、COMM列の総行数を表示図4の実行結果で、COMM列の件数が4であることに注意してください。図1と照らし合わせて確認すると、COMM列には値が4つしか格納されておらず、残りがNULL(データが格納されていないフィールド)であることが分かります。COUNT関数では、NULL値を省いて行数を数えます。また、WHERE句で条件を指定すると、条件に該当する行数を数えることができます。
データをグループ化してみよう
ここまでの例では、社員表全体を1つのグループとして、社員全体の中から給与の最大値や最小値、行数などを集計しました。しかし、部門や職種単位で集計結果を出したいケースもあるでしょう。このような場合には、GROUP BY句を使用します。
SELECT グループ化する列名, 関数(列名), … FROM 表名 GROUP BY グループ化する列名 ・・・
それでは、GROUP BY句を使って部門ごとにグループ化し、部門ごとの社員数と平均給与を調べてみましょう。以下のようなSQL文を書くと、部門ごとにグループ化した集計結果を表示することができます。次の例では、結果を見やすいように、部門番号でデータを並べ替えて表示しています。また、「社員数」「平均給与」という列別名を付けて表示しています。
SELECT deptno, COUNT(empno) AS "社員数", TRUNC(AVG(sal)) AS "平均給与" FROM emp GROUP BY deptno ORDER BY deptno;
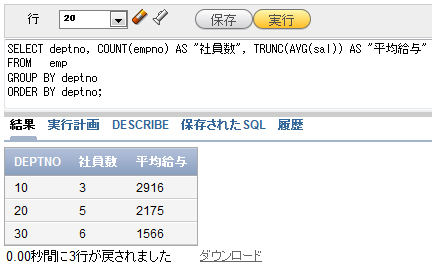 図5 部門ごとに社員数と平均給与を表示
図5 部門ごとに社員数と平均給与を表示GROUP BY句に複数の列を指定すると、複数の列を使ってさらに細かくグループ化することもできます。次の例では、GROUP BY句にdeptno列と、job列を指定しています。このように指定すると、最初に指定したdeptno(部門番号)でグループ化し、部門が同じ人をさらにjob(職種)でグループ化することができます。
SELECT deptno, job, COUNT(empno) AS "社員数", TRUNC(AVG(sal)) AS "平均給与" FROM emp GROUP BY deptno, job ORDER BY deptno, job;
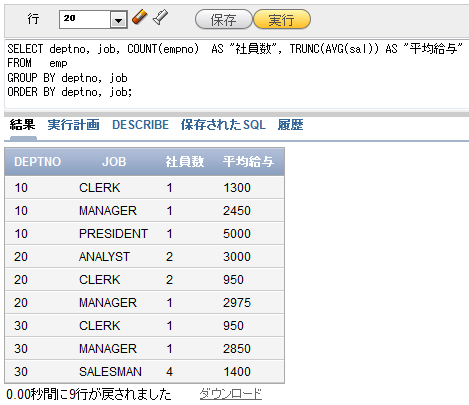 図6 部門内の職種ごとに社員数と平均給与を表示
図6 部門内の職種ごとに社員数と平均給与を表示図6の結果を見ると、部門20にはANALYST、CLERK、MANAGERという3つの職種があり、職種ANALYSTとCLERKの社員は2名、職種MANAGERの社員が1名いることが分かります。また、職種ごとの平均給与も表示されています。
特定のグループだけを検索してみよう
グループ化した結果に条件を付けて、特定のグループだけを表示することもできます。例えば、図6の結果のうち、社員が2人以上いるグループだけを表示したい場合には、どのように指定すればよいでしょうか。
「条件を付けて結果を絞り込む」ためのキーワードと言えば、真っ先に思いつくのはWHERE句ですよね。しかしWHERE句は、1行1行のデータに対して条件を指定するキーワードであるため、グループ化した結果に対して使うことができません。そのため、以下のようにWHERE句でグループ化した列を指定すると、エラーになります。
SELECT deptno, COUNT(empno) AS "社員数", TRUNC(AVG(sal)) AS "平均給与" FROM emp WHERE COUNT(empno)>=2 GROUP BY deptno, job ORDER BY deptno, job;
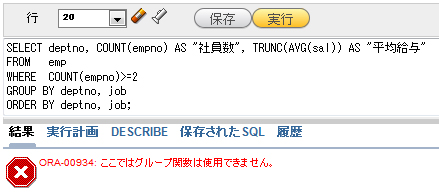 図7 グループ関数を使った列にWHERE句を使用するとエラーになる
図7 グループ関数を使った列にWHERE句を使用するとエラーになるそこで、グループ化した結果に対して条件を付けて、特定のグループだけを検索する場合には、WHERE句ではなく、HAVING句を使用します。
SELECT グループ化する列名, 関数(列名), … FROM 表名 GROUP BY グループ化する列名 HAVING グループ化した結果に対する条件 ・・・
例えば、社員が2人以上いるグループだけを表示したい場合には、以下のように指定します。
SELECT deptno, COUNT(empno) AS "社員数", TRUNC(AVG(sal)) AS "平均給与" FROM emp GROUP BY deptno, job HAVING COUNT(empno)>=2 ORDER BY deptno, job;
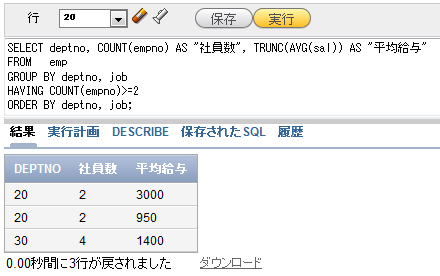 図8 部門内の職種でグループ化し、社員が2人以上いるグループだけを表示
図8 部門内の職種でグループ化し、社員が2人以上いるグループだけを表示コラム---職種は何種類?
COUNT関数を使うと、データの個数を数えることができますが、データが「何種類あるか」を数えるにはどのようにすればよいでしょうか。
例えばEMP表の職種(job)列には以下のようなデータが入っています。
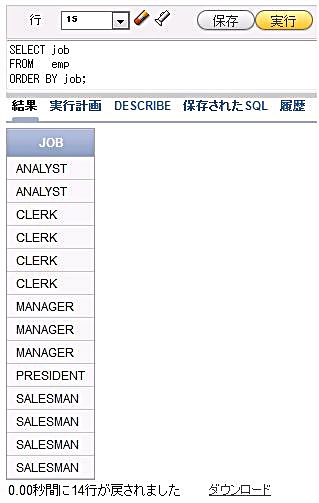 図9
図9では、職種は何種類あるのでしょうか。job列の種類を数えるには、重複しているデータを排除した後で、データの個数を数えれば良さそうです。このような場合には、重複を排除するためのキーワードDISTINCTを使用します。DISTINCTキーワードは、SELECT句の列名の前に指定します。
SELECT DISTINCT job FROM emp;
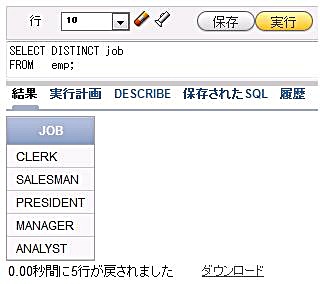 図10
図10それでは、COUNT関数とDISTINCTキーワードを組み合わせて、職種が何種類あるかを数えてみましょう。
SELECT COUNT(DISTINCT job) FROM emp;
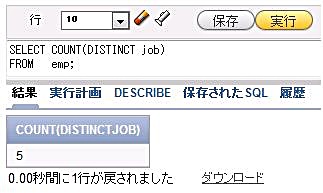 図11
図11今回ご紹介したCOUNTやDISTINCTを使ってデータを「数える」方法は便利ですが、検索対象の全てのデータにアクセスをしてデータを集計する動作となるため対象のデータ量が多くなると、大量の読み込みが発生することを覚えておいてください。
例えば、「条件に合うデータがあるかないか」を調べるためにCOUNT(*)を何度も使うのは効率的ではありません。そのような場合には、次回以降で紹介するEXIST条件などを使用するとよいでしょう。
筆者紹介

日本オラクル オラクルダイレクト所属。
須々木尚子(すすき なおこ)
オンラインセミナーの講師や、お客様への提案、案件の支援などを担当。著書に「Oracle SQLクイズ」(翔泳社)があります。
- SQLでデータを操作する(副問合せを利用したINSERT/相関UPDATE/MERGE)
- SQLでデータを操作するときの文法(INSERT/UPDATE/DELETE)
- 高度な副問合せの構文
- 副問合せを使った複雑な条件指定
- データをグループ化して表示してみよう(2)
- データをグループ化して表示してみよう(1)
- 複数の表からデータを取り出して表示させる(2)
- 複数の表からデータを取り出して表示させる(1)
- SQL関数を使って面倒な処理を簡単に済ませる
- SELECT文で取り出したデータを加工して表示する
- 複数の条件を指定してSELECT文を実行する
- まずはここから! 基本的なSELECT文から始めよう
- SQL実行環境を準備しよう
- SQLとはどういう言語か
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。