複数の表からデータを取り出して表示させる(1):Webブラウザで気軽に学ぶ実践SQL講座(7)
今回は、SQLの中でも特に重要な構文である「結合」について解説します。一言で結合といっても、いろいろなやり方があります。まずは、比較的単純な方法から解説します(編集部)
別々の表から関係するデータを取り出す
今回と次回の2回に分けて、SQLの中でも、最も重要な構文の1つである結合について説明します。「結合って難しそう」というイメージをお持ちの方も多いかもしれませんが、1つ1つの構文はそれほど複雑ではありません。整理して覚えましょう。
本連載で使っている「apex.oracle.com」の環境には「EMP」「DEPT」という複数の表があります。これは、リレーショナルデータベース(RDB)では一般的なことです。RDBでは、データを格納するストレージ領域を効率良く使うため、「正規化」というルールに従って、データを格納する表を複数に分割するように設計します。分割された複数の表から、関係するデータを取り出すことを「結合」と呼びます。
結合構文を考える前に共通列を考える
前述のように、RDBでは、それぞれ関係するデータを複数の表に分割して格納します。データ同士が「関係」しているわけですから、その関係は表にも定義しなければなりません。データ同士の関係は、データベースを設計するときに定義します。
例えば、「EMP(社員表)」と「DEPT(部門表)」はそれぞれ、従業員と部門の情報を格納していますが、これら2つの表には「従業員はいずれかの部門に所属する」「部門は従業員から構成される」という関係があります。2つの表の関係を定義しているのは、両方の表に共通して存在する「DEPTNO」という列です。
例えば、社員の所属部門を調べるとしましょう。この場合はまず、EMP表で社員名から該当するDEPTNOを調べます。DEPTNOが分かったら、DEPT表を調べればDEPTNOから部門が分かります。
結合構文を使うときは、取り出すデータの関係を考え、共通列がどれかを見極める必要があります。図1はEMP表とDEPT表の関係を示したものです。先に述べたように、どちらの表にも存在するDEPTNO列が共通列になり、2つの表を関係付けています。

結合構文を使いこなすための3つのポイント
結合構文を使いこなすには、次に挙げる3つのポイントを押さえる必要があります。
1つ目はJOINキーワードです。検索対象のデータを格納している表を複数指定するときに必要になるキーワードです。3つ以上の表を指定することも可能です。
2つ目は結合条件の指定です。先に示したように、お互い関係する表は、それぞれ共通列を持っています。結合構文では、この共通列を正しく指定しなければなりません。
3つ目は、列名の前に表名を指定することです。結合構文では、複数の表から、取得したいデータを格納した列を指定することになります。そのため、指定した列がどの表に存在するかを指定する必要があります。列名の前に表名を指定する表記を、表修飾と呼びます。
表修飾は省略できることもありますが、あいまいさを排除するために、指定できるところではすべて指定することをお勧めします。コーディングルール統一の面から考えても、すべて指定した方がよいでしょう。
以上のポイントを押さえて、典型的な結合の構文をまとめると以下のようになります。
SELECT 表1.列名, 表2.列名… FROM 表1 JOIN 表2 ……
構文の末尾にある「結合条件」は、共通列を指定する方法と考えてください。結合条件を指定するには、複数の方法があります。それぞれの方法を試しながら、特徴を確認していきましょう。
共通列の存在を前提とするNATURAL JOIN句
前述の通り、結合対象となるそれぞれの表には共通列があるはずです。NATURAL JOIN句では、FROM句で指定した結合対象表に存在する同じ名前の列が、自動的に結合条件となります。構文は以下の通りです。
SELECT 表1.列名, 表2.列名, 共通列… FROM 表1 NATURAL JOIN 表2 ……
SELECT句の「表1.列名」「表2.列名」のように、列名の前に指定してあるのが表修飾です。ただし、共通列の前には、表修飾の記述がないことに注意してください。NATURAL JOIN句を使うときは、両方の表に同じ名前の列があることが前提となるため、共通列には表修飾を付けないのです。
例えば、EMP表とDEPT表を結合し、社員名と社員が所属する部門名を表示するには、以下のようなSQL文を実行します。
SELECT emp.ename, deptno, dept.dname FROM emp NATURAL JOIN dept;
実行結果は図2の通りです。
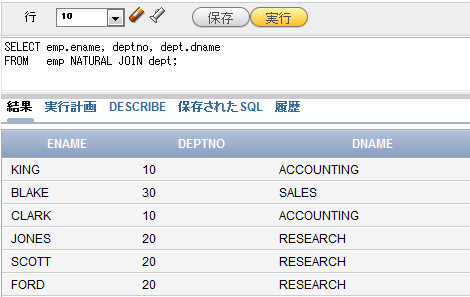 図2 NATURAL JOIN句を使って、EMP表とDEPT表を結合し、データを取り出した例
図2 NATURAL JOIN句を使って、EMP表とDEPT表を結合し、データを取り出した例この例では、結合対象の表それぞれに共通列が1セット(DEPTNO列)しか存在しないため、DEPTNOだけでデータを結合しています。共通列となる列(同じ名前の列)がほかにも存在することもありますので注意してください。共通列が複数ある場合は、結合にすべての共通列が関係するので、期待通りの結果にならないことがあります。
例えば、EMP表とDEPT表に、「DEPTNO」以外にも「COMMENT(コメント)」という共通列が存在する場合、部門が同じで、かつコメントが同じデータしか結合しません。
USING句で共通列を指定する
USINGというキーワードを使って結合列を指定する方法もあります。USING句で共通列を指定することによって、複数の表を、指定した列で結合することができます。構文は以下の通りになります。
SELECT 表1.列名, 表2.列名, 共通列… FROM 表1 JOIN 表2 USING (共通列) ……
NATURAL JOIN句を使うときと同じく、USING句を使うときは、両方の表に同じ列があり、それが共通列となることが前提となるため、SELECT句やUSING句で共通列を記述するときは、表修飾を付けません。
USING句を使って、EMP表とDEPT表を結合し、社員名と社員が所属する部門名を表示するには、以下のようなSQL文を実行します。
SELECT emp.ename, deptno, dept.dname FROM emp JOIN dept USING (deptno);
実行すると図3のようになります。結果だけを見ると、図2と同じになります。
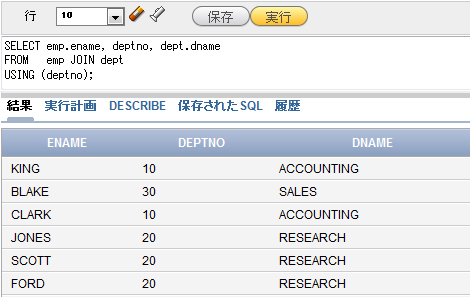 図3 USING句を使って、EMP表とDEPT表を結合し、データを取り出した例
図3 USING句を使って、EMP表とDEPT表を結合し、データを取り出した例今回使用している2つの表には、共通列が「DEPTNO」しかないため、結果は図2でお見せしたNATURAL JOIN句を使ったものと同じになります。NATURAL JOIN句を使う場合と比較すると、USING句を使うと結合列が明確になり、SQL文を読む人にとって分かりやすいというメリットがあります。
ここまで、結合構文の手始めとして、NATURAL JOIN句とUSING句という2つの構文を紹介しました。しかし、表の列名や結合条件によっては、NATURAL JOIN句やUSING句が使えない場合があります。
表を設計するときは、表の関係を定義するための共通列を、同じ名前でそろえることが普通です。しかし、同じ意味を持つ列であったとしても「顧客住所」「送り先住所」「送り元住所」のように、あえて異なる列名を使う場合もあります。このような場合は、NATURAL JOIN句やUSING句は使えません。
ON句を使えば異なる名前の列を共通列にできる
結合構文の中でも、最も多くの場面で使えるのがON句です。ON句は、先に説明したNATURAL JOIN句やUSING句のように制限がなく、さまざまな結合条件を指定できるため、最も柔軟な結合構文と言えます。構文は以下の通りです。
SELECT 表1.列名, 表2.列名, 表1.共通列… FROM 表1 JOIN 表2 ON 表1.共通列 = 表2.共通列 ……
ON句を使うときは、結合するそれぞれの表にある共通列をすべて列挙して等号(=)でつなぐことで、共通列を明示的に指定します。共通列に使う列名が表によって異なる場合でも、これなら問題なく結合できます。また、NATURAL JOIN句やUSING句を使うときと異なり、共通列にも表修飾を付ける必要があることに注意してください。
それでは、ON句を使ったSQL文を実行してみましょう。
SELECT emp.ename, dept.deptno, dept.dname FROM emp JOIN dept ON emp.deptno=dept.deptno;
実行結果は図4の通りです。結果だけを見ると、上記の図2、図3と同様になります。
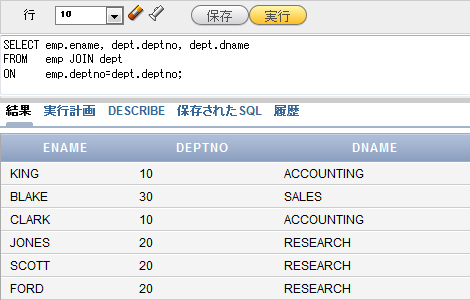 図4 ON句を使って、EMP表とDEPT表を結合し、データを取り出した例
図4 ON句を使って、EMP表とDEPT表を結合し、データを取り出した例表別名を利用して表記をシンプルにする
結合構文では、複数の表から列データを取得するため、SELECT句の列名の前に表名を指定します。先に説明した表修飾です。
今回の例では「EMP」や「DEPT」のように表名が短いため、それほど気にならないかもしれません。しかし、表名が長い、列が多いといった場合は、表名の指定が煩雑になり、SQL文も読みにくくなってしまいます。
そこで、結合時には表に別名(表別名)を付け、シンプルに表記することが一般的です。表別名は、FROM句で、表名の後にスペースを空けて指定します。構文は以下の通りです。
SELECT 表別名1.列名, 表別名2.列名, 表別名1.共通列… FROM 表1 表別名1 JOIN 表2 表別名2 ON 表別名1.共通列 = 表別名2.共通列 ……
例えば、図4でお見せしたON句でEMP表とDEPT表を結合するSQL文を、表別名を使って書き換えてみましょう。EMP表に「e」、DEPT表に「d」という表別名を付けます。
SELECT e.ename, d.deptno, d.dname FROM emp e JOIN dept d ON e.deptno=d.deptno;
実行結果は図5の通りです。
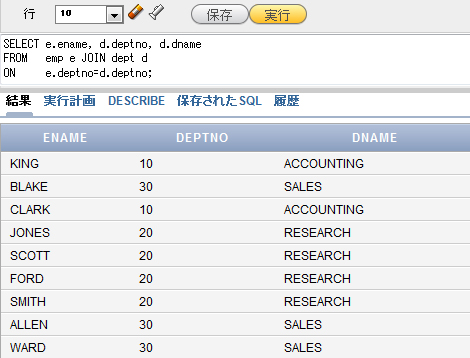 図5 表別名を使って結合のSQL文を書き換え、実行した例
図5 表別名を使って結合のSQL文を書き換え、実行した例表別名を使用するときは、1つ注意しなければならない点があります。SQL文の中で表別名を指定したら、そのSQL文では表名ではなく表別名で表を指定しなければならないのです。
例えば、EMP表に対して表別名「e」を指定したにもかかわらず、以下のSQL文のようにSELECT句で本来の表名である「EMP」を指定すると、エラーになります。
SELECT emp.ename, d.deptno, d.dname FROM emp e JOIN dept d ON e.deptno=d.deptno;
実行すると図6のようなエラーメッセージが現れます。
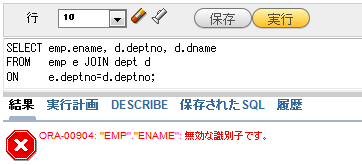 図6 表別名を使っているSQL文の中で、表の実名を使ってしまうとエラーになる
図6 表別名を使っているSQL文の中で、表の実名を使ってしまうとエラーになる今回は、結合の中でも比較的シンプルな、2つの表のデータを結合するための方法を解説しました。次回は、「自己結合」「内部結合」「外部結合」といった、やや複雑な結合方法について解説します。
コラム---表の結合順序
こんな質問を受けることがあります。「結合構文のFROM句で複数の表名を指定するとき、指定する表の順序を変えると、内部処理や処理性能に違いが現れるのでしょうか?」
基本的には、そんなことはありません。今回のコラムでは、結合時の内部動作について少し解説しましょう。
Oracle Databaseで結合構文を実行すると、Oracle Databaseは自動的に以下に挙げる2つのポイントを評価し、最適な実行計画を立てます。
1つ目は結合順序です。3つ以上の表を結合する場合、最初に結合する表のペアを選択し、その後、その結果に結合する表を選択します。Oracle Databaseは、次のステップに渡す行をなるべく少なくするように、結合順序を自動的に決定します。
2つ目は結合方法です。Oracle Databaseは、「ハッシュ結合」「ネステッドループ結合」「ソート/マージ結合」の3種類から、最適な結合法を自動的に決定します。
ハッシュ結合とは、ハッシュ関数を利用した結合方法です。ハッシュ結合ではまず、一方の表(行数が少ない表)の結合対象列値をハッシュ関数にかけて、メモリ上にその結果の表を作ります。次に、もう一方の表の列値も同じくハッシュ関数にかけ、結果表と比較します。ハッシュ結合に利用するハッシュ関数の計算コストは一般に低いため、少ない計算コストで高速に結合を完了させることができます。
ネステッドループ結合は、「一方の表(表A)から行を1つ取り出し、もう一方の表(表B)のデータと比較する」という処理を繰り返し、結合していく方法です。すべての結合結果を得るには、表Aの行数の分だけ、表Bのデータすべてを繰り返し検索する必要があります。この方法は、表の一部分を結合する場合に有効です。
ソート/マージ結合は、結合対象表をソートして、比較しながら結合していく方法です。結合前にデータがソート済みであれば、高速に処理できます。この方法は、比較的大きな表を結合する場合に有効です。
Oracle Databaseは、SQL文を実行するときに、上記のような結合順序やその方法を自動的に評価し、最適な実行計画を立てるのです。しかし、この評価にはコストがかかります(どの結合方法が最適か、人間が考えても時間がかかりますよね)。結合する表の数が多くなればなるほど、解析に時間がかかったり、まれに、解析しても最適な実行計画が立てられないことがあります。「複雑なSQL文を実行しようとすると、最適な実行計画が選択されないことがある」という問題は、このために起こるのです。
このような観点からも、1つのSQL文の中であまり多くの表を結合しなくても済むように表を設計したり、SQL文をなるべくシンプルに書くように心がけることをお勧めします。
筆者紹介

日本オラクル オラクルダイレクト所属。
須々木尚子(すすき なおこ)
オンラインセミナーの講師や、お客様への提案、案件の支援などを担当。著書に「Oracle SQLクイズ」(翔泳社)があります。
- SQLでデータを操作する(副問合せを利用したINSERT/相関UPDATE/MERGE)
- SQLでデータを操作するときの文法(INSERT/UPDATE/DELETE)
- 高度な副問合せの構文
- 副問合せを使った複雑な条件指定
- データをグループ化して表示してみよう(2)
- データをグループ化して表示してみよう(1)
- 複数の表からデータを取り出して表示させる(2)
- 複数の表からデータを取り出して表示させる(1)
- SQL関数を使って面倒な処理を簡単に済ませる
- SELECT文で取り出したデータを加工して表示する
- 複数の条件を指定してSELECT文を実行する
- まずはここから! 基本的なSELECT文から始めよう
- SQL実行環境を準備しよう
- SQLとはどういう言語か
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。