ビッグデータブームの裏側で進むサーバ業界の技術革新 ――富士通SPARC M10編:特集:業務革新を支える最新サーバテクノロジを追う(1)(4/4 ページ)
データベースを高速化する仕掛け
さらに、SPARC M10にはデータベース系の処理を高速化するための仕掛けが用意されている。SPARC64チップそのものがベクトル演算を得意とすることは多くの読者が知っていることだろう。スーパーコンピュータ「京」に代表されるように物理シミュレーションなど「類似の計算を大量に実行」する際に高いパフォーマンスを出す。この並列演算処理性能を、ビジネスデータの処理に活用しようというのが、SPARC M10およびSPARC 64 Xの興味深いところだ。
また、計算処理以外でも大量データ処理では頻繁に行われるメモリコピーやメモリコンペアでもハードウェアによる並列処理が自動的に活用される。この場合、プログラムがOSのシステムコールを使っていれば、OSが自動でハードウェアの並列処理エンジンに処理を渡す仕掛けなので、ユーザープログラムやミドルウェア側は新サーバに移行するだけでも性能が向上する。さらに、ソフトウェア側がこのプロセッサに最適化されていれば、パフォーマンス向上を狙える。既に富士通のデータベース製品であるSymfowareとOracle DatabaseでSPARC64 Xの機能への対応を予定している。
SPARC M10が目指す世界と業務の世界でのビッグデータ分析はどう結び付くか
ここまでで、SPARC M10の技術的なトピックを見てきた。さて、これが本稿冒頭で示した企業システムにおいてどのようなインパクトを持つのかを、あらためて整理してみよう。
富士通がSPARC M10を発表した際に示したこの絵を見てほしい。
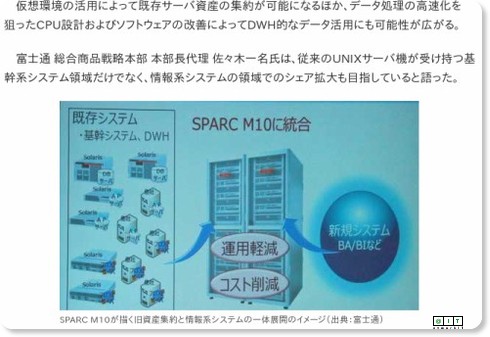
いかにもSPARC M10は「UNIXサーバ」としてリリースされたものだが、既存のUNIXサーバをただ速くする、というためだけのものではない。SPARC64 Xという、高い性能を持つCPUを得たことで、業務系システムの集約だけでなく、高速な処理性能を生かした情報系システムの集約までをも狙っている製品であることが分かる。
つまり、既存の基幹系業務システムをSPARC M10上に効率的に集約し、集約した既存資産の中に含まれるデータを、新規に、高い並列処理能力をもったこのサーバ機の中でリアルタイム分析処理に役立てていこうとしているのだ。この仕掛けを詳細に図示するとしたら下図のようになるだろう。
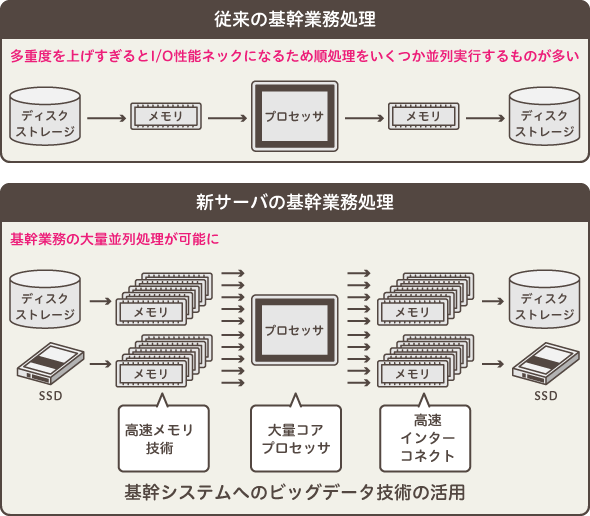
既存資産が持つ実績データの分析では、大量データに対する繰り返しの処理など、負荷が高いものが多い。高い負荷の処理を、高速なインプット/アウトプットが可能なメモリ上に置くことは、システム設計上、非常にリスクが高いといわれてきた。
SPARC M10がこの無謀に見える取り組みを進める理由には、常識を覆す仕掛けがある。それこそが「Software On Chip」である。本稿で一部並列処理高速化の取り組みについて言及してきたが、次回、より詳細な技術情報に触れていこう。次回は、富士通におけるSPARC64チップ開発の歴史から、京で培ったノウハウの具現化、Software on Chipを中心により深い技術背景を追っていく。
「京(けい)」:「京」は理化学研究所の登録商標です。京は日本のスーパーコンピュータの中核システムとして、理化学研究所と富士通が共同開発した、世界最高レベルの性能を有するスーパーコンピュータです。
最新のサーバテクノロジの動向を特集
データプラットフォームにおける技術革新には目覚ましいものがあります。「特集:業務革新を支える最新サーバテクノロジ」では、最新のサーバテクノロジ、データプラットフォームの動向を媒体横断で網羅しています。

関連記事
 第10世代SPARC64を搭載したSPARC M10はシステム集約とビジネススピード向上に寄与する
第10世代SPARC64を搭載したSPARC M10はシステム集約とビジネススピード向上に寄与する
次世代SPARCプロセッサ搭載機がいよいよ市場に投入される。旧資産の集約と高速なデータ処理を実現するための「ソフトウェアとハードウェアの融合」、DWH的な情報分析向けの機能強化がポイントだ。 「書き込みが最大20倍高速化」、SPARCベースのエンジニアドシステム
「書き込みが最大20倍高速化」、SPARCベースのエンジニアドシステム
SPARCの性能とSolarisの仮想化技術の合わせ技で、複数DBを統合しながら処理高速化も実現するエンジニアドシステムが登場した。 一から知るSystem Center 2012と仮想化管理 Virtual Machine Manager:第1回 System Center 2012の概要
一から知るSystem Center 2012と仮想化管理 Virtual Machine Manager:第1回 System Center 2012の概要
仮想化や展開、稼働監視、データ保護、マルウェア対策など幅広く管理するマイクロソフト製ツールSystem Center 2012の概要を解説する。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。