潜入! 北陸StarBED技術センター:これが世界最大規模のテストベッドの全貌だ(1/3 ページ)
Interop Tokyoの「クラウドコンピューティングコンペティション」やWASForum主催の「Hardening Zero/One」など、超ハードなコンピューティング環境を陰で支える北陸StarBED技術センター。企業の実証実験空間としても積極的に利用される同センターは、世界最大規模のエミュレーション環境を誇る最先端施設だった。
1110台のサーバが支えるテストベッド環境
降りるバス停を間違え、雪に埋もれながら歩きさまようこと40分。研究員の宮地利幸氏に車でサルベージされ、ようやく北陸StarBED技術センターにたどり着いた。そこは、未来を先取りする技術や設備が整えられた“すごい”ところだった(写真1、2)。

 写真1●北陸StarBED技術センター。左側が事務室と会議室、右奥にはサーバルームや研究員室などがある(左)。写真2●センター入口。新しいサーバ搬入作業で工事の方々の長靴が並んでいた(右)
写真1●北陸StarBED技術センター。左側が事務室と会議室、右奥にはサーバルームや研究員室などがある(左)。写真2●センター入口。新しいサーバ搬入作業で工事の方々の長靴が並んでいた(右)独立行政法人 情報通信研究機構(NICT)のテストベッド研究開発を担う北陸StarBED技術センターは、大規模で複雑なネットワークシステムのシミュレーション基盤として、2002年に開所した。
当時は「TAO北陸IT研究開発支援センター」と呼ばれていた同センターには512台のPCサーバが設置され、インターネットとブロードバンド環境の普及に先んじたエミュレーションのためのプロジェクト、「StarBED」(スターベッド)が始動した(図1)。
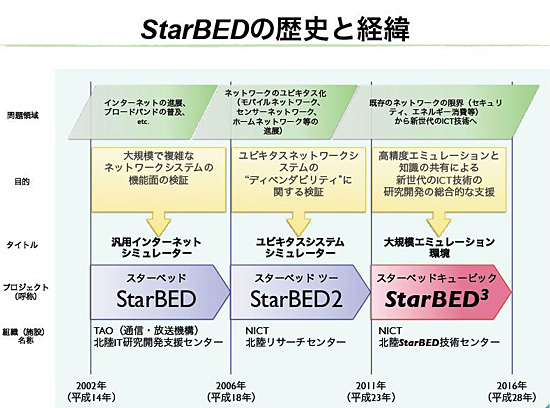 図1●StarBEDの歴史
図1●StarBEDの歴史当初は、北陸先端科学技術大学院大学の先生や学生が研究に利用しており、公募で有償貸出する場合は、運用サポートとして別途技術員が付く形を取っていた。ただし、技術員が提供するのはあくまでも一般的な運用サポートのみで、利用者は管理者権限を使って自由に環境に触れていた。かくして基盤は“無法地帯化”し、「他ユーザーの設定を誤って変更した」「管理サーバをリブートした」といったトラブルが続出するようになった。
2006年、ネット接続可能な端末が急増し、モバイルネットワークやスマートホームを含むユビキタス環境への対応が急務となる中で、第2期「StarBED2」(スターベッド・ツー)が開始した。サーバも168台が追加され、膨大な計算処理の負荷に耐え得る、より可用性に優れた基盤が整った。
これと併せてセンターの名称は「北陸リサーチセンター」に改定。“無法地帯化”への対処も含め、NICTの研究機関として人員を配置、運用体制が整えられ始めた。
独自開発の実験支援システム「SpringOS」が導入されたのも、この時期だ。SpringOSは、異なるサーバやネットワーク機器の設定を共通コマンドで実行するためのインターフェイスだ。その内容は、電源のオン・オフからネットワークの構成変更まで多岐に渡る。
StarBEDの運用は、クラウドのデータセンター管理に近いものがある。ただし、StarBEDの場合は、商用データセンターとは異なり利用者が自由に設定を変更できる。それに対応するインターフェイスの開発は、非常に複雑で難しい。「現在のIaaS/HaaSでStarBEDのような柔軟性が求められるようになったら、SpringOSはそのベースとして活かされるかもしれない」。同センター長の三輪信介氏は期待を込めてそう述べる。
 写真3●北陸StarBED技術センター センター長の三輪信介氏
写真3●北陸StarBED技術センター センター長の三輪信介氏2011年、旧サーバの廃棄や新規入れ替えを経て、サーバは合計1110台となった。100万台規模でのエミュレーションテストが可能な世界最大基盤「StarBED3」(スターベッド・キュービック)の誕生だ。名称も「北陸StarBED技術センター」になり、NICTのテストベッド研究開発推進センターの1つとして生まれ変わった。
現在は、次世代ネットワーク開発のためのテストベッド「JGN-X」と相互連携しながら、NICTが掲げる次世代ICTシステムの構築に向けた技術・研究開発、企業の技術検証、運用技術者の人材育成などをサポートしている。
「大規模環境でエミュレーションできること」の意味
テストベッドへのアプローチは、大きく分けて2つある。1つは、新しい技術を検証するために、その技術を使ったテストベッドを構築するというアプローチ。もう1つは、新しいソフトウェアなどの技術検証や研究開発を行う基盤としてテストベッドを構築、社会貢献するというアプローチ。StarBEDが採用しているのは後者だ。
製品開発では、事前の動作検証が大変重要となる。特に大規模なネットワーク環境には、サーバ数台レベルの検証環境だけでは洗い出せない問題が潜んでいるという。
同センターを利用する企業の1つに、ある国内大手ディスプレイメーカーがある。同社はX線写真の読影システムを開発している。このシステムの肝は、レントゲン写真をどのディスプレイ画面に表示しても濃淡が変わらないよう自動調整することだ。濃淡が変わってしまえば、別の病気に誤診断される恐れがある。
例えば、濃淡が調整されないというエラーが100分の1の確率で起こるとする。このとき、数十台レベルで実験してもエラーは発生しないが、数百台規模になれば100台に1台がエラーを起こすことになる。100台のディスプレイというのは決して多い数ではなく、1つの病院内だけでも十分あり得る数だ。系列病院をネットワークでつなげば、あっという間に数百台に達する。
「小規模環境では発生頻度の低い現象も、大規模環境になった途端、頻発し始める。大規模でエミュレーションしなければ見えてこない問題は非常に多い。そこにStarBEDの意義がある」(三輪氏)
StarBEDを利用するには、共同研究または研究委託の契約を行ってから、プロジェクト利用申請書を提出する。StarBED3からは、NICTのプロジェクトに加わったこともあり、NICTのミッションである新世代ネットワークの構築または活用に関わる申請が比較的優先されやすくなった。
とはいうものの、「次世代ネットワークに必要な運用技術の知見は、多くの利用があってこそ蓄積できるので、なるべく全部を受け入れられるよう、時期をずらすなどして対応している」と三輪氏は明かす。
このほか、同センターは人材育成・教育利用に関わる案件にも積極的に取り組んでいる。最近であれば、Interop Tokyoのクラウドコンピューティングコンペティションや、WASForum主催のHardening Zero/Oneが記憶に新しい。
クラウドコンでは、参加者が新たな利用者になるケースもあった。「非常にマニアックな使い方をしてフィードバックしてくれるので、StarBEDの運用やエミュレーション技術の向上にも良い影響があった」。独りよがりのシステム開発になっていないか、いつも不安があると話す同センターの研究員、宮地利幸氏は、こうしたフィードバックがあって改善できることが何よりうれしいと笑う。
 写真4●北陸StarBED技術センター 研究員の宮地利幸氏
写真4●北陸StarBED技術センター 研究員の宮地利幸氏現在、StarBED3では階層型ロケータ自動割当プロトコル「HANA」の大規模実証実験が行われている。近年、AS間で交換される経路情報は増加し続けており、スマートホーム推進でネットワーク接続型の家電製品が増えれば、エンドノードはますます増大する。このまま行けば、経路表が抱える情報は莫大な数になり、障害時の経路特定と迂回に時間がかかる可能性も出てくる。
そこで開発されたのが、HANAだ。同システムは、ISPやエンドノードに固有のアドレス空間を割り当てるのではなく、階層構造にひも付いたアドレスを割り当てていく。そうすることで、経路情報は最小化され、エンド数に振り回されない効率的なルーティングが実現する。現在は標準化に向けた実用性の検証がStarBED3で行われている(図2)。
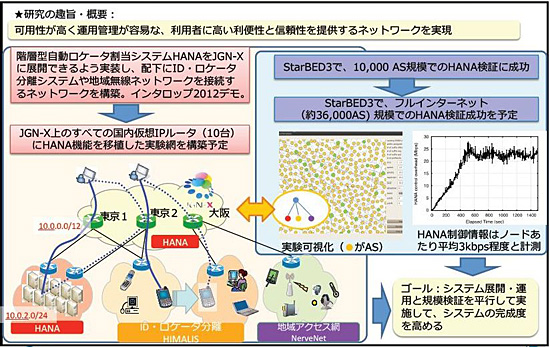 図2●階層型ロケータ自動割当プロトコル「HANA」
図2●階層型ロケータ自動割当プロトコル「HANA」すでに1万ASでの検証は完了し、今は3万6000ASでの大規模検証が行われている。実は、1万ASの実験では、第1回目が失敗に終わっている。原因は、ソフトウェアの設計ミスで大規模環境への対応ができていなかったからと三輪氏は明かす。
「例えば経路割り当ての通信を考えたとき、私たちの中には全体で何となく同期してうまくいくようなイメージがある。しかし、大規模環境ではそうならない。1つの経路を通過するごとに、0.1ミリ秒のタイムラグが発生する場合、1万ASでは1秒のずれになる。これは同期を含む他の動作に影響を与え得る、大きなずれだ」。同実験を通して、大規模実験の重要性を改めて感じたと、三輪氏は振り返る。
HANAの検証が完了したら、新世代ICTシステムの検証環境を構築し、StarBEDのテストベッドとして利用できるようにするという。最終目標を目指し、今まさに実験が進められている。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。