Hadoopシステムのエンドユーザーコンピューティングをマイクロソフトが考えると? Parallel Datawarehouseのアプローチ
マイクロソフトがMPP型DWHソリューションを考えると? Apache Hadoopベースの非構造データを取り込むことを前提としたSQL Serverのビッグデータ対応はエンドユーザーコンピューティングを意識した内容に。
2013年3月21日、日本マイクロソフトは「ビッグデータ戦略記者説明会」を開催、事例とともに、製品ロードマップを公開した。
 日本マイクロソフト エンタープライズソリューション営業本部 本部長 藤井一弘氏
日本マイクロソフト エンタープライズソリューション営業本部 本部長 藤井一弘氏最初に登壇した日本マイクロソフト エンタープライズソリューション営業本部 本部長 藤井一弘氏は、市場ではデータマイニングによるマーケティング戦略の高度化や、M2Mデータの活用、テレマティクスの活用といった、ビッグデータ活用ニーズがあるものの、「自社データ資産が正確でないケースが少なくないことや、データ分析スキルのある人材が不足していることが、ビッグデータ活用の障壁になっている」と語り、既存システムは業務部門が十分に使いこなせるものになっていないと指摘した。
企業におけるビッグデータ活用は、需給計画立案のための予測分析や市場動向の分析などさまざまな領域で適用できる。その際重要となるのは、市場動向や財務状況など、判断材料となる情報の鮮度がどれだけ高いかという点にある。
 日本マイクロソフト 業務執行役員 サーバープラットフォームビジネス本部 本部長 梅田成二氏
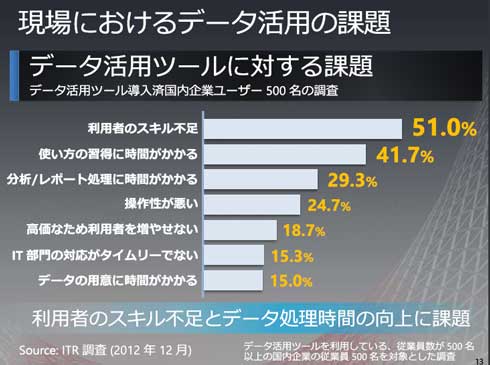
日本マイクロソフト 業務執行役員 サーバープラットフォームビジネス本部 本部長 梅田成二氏日本マイクロソフト 業務執行役員 サーバープラットフォームビジネス本部 本部長 梅田成二氏は、企業におけるデータ活用の調査資料を基に、多くの企業で事業状況の確認などにおけるデータ利用の多くが月次にとどまっている状況を指摘する。日次やほぼリアルタイムでの動向確認ができている企業はごくわずかだ。また、レポーティングや帳票を越えてマイニングや分析といった形でデータを活用できている企業が3割程度でしかない。梅田氏は、データ活用が進んでいない要因として、利用者のスキル不足やツールそのものの操作性の悪さを挙げる。
「いくらHadoopなどのビッグデータ活用ソリューションがあっても、エンドユーザーが使いこなせなければ意味がない。“全社員データサイエンティスト化”を実現する必要がある」(梅田氏)
もはやRDBだけではないSQL Serverのラインアップ拡充
マイクロソフトでは、現段階でSQL Server製品ラインアップを3つ用意している。バッチ処理などのOLTP系の処理を高速化するためにストレージI/Oを高速化する「SSD Appliance」、1つのメモリを複数のCPUが共有する「対称型マルチプロセッシング(Symmetrical Multi Processing:SMP)」型データウェアハウス「Fast Track Data Warehouse」、そして、新たに発表された「超並列プロセッシング(Massively Parallel Processing:MPP)」型*データウェアハウス「Parallel Data Warehouse(PDW)」だ。PDWは2013年5月にも出荷を開始する予定。現段階では、ハードウェアベンダとして日本ヒューレット・パッカード、デルが、SIにはNTTデータ、NEC、野村総合研究所、アバナードが名を連ねている。
* MPP型 シェア―ド・ナッシング型とも呼ばれる。SMPがメモリ共有を行うのに対して、CPUとメモリ、ディスクが1対1になっているため、一般的にボトルネックが発生しにくくスケールアウトしやすいとされる。
 日本マイクロソフト サーバープラットフォームビジネス本部 アプリケーションプラットフォーム製品部 部長 斎藤泰行氏
日本マイクロソフト サーバープラットフォームビジネス本部 アプリケーションプラットフォーム製品部 部長 斎藤泰行氏PDWは、MPP型であることもポイントだが、Apache Hadoopとの連携が大きな特徴となる。
通常、Apache Hadoop側のデータをデータストアに転送する際は、一般的にはApache Sqoopを使うが、日本マイクロソフト サーバープラットフォームビジネス本部 アプリケーションプラットフォーム製品部 部長 斎藤泰行氏によると「Sqoopによるデータ転送がシステムのボトルネックになっている。PDWであれば、Hadoopのデータノードに対して、PDWの各コンピュートノードが並列にデータ転送を実施できることから高いパフォーマンスを得られる」という。
PDWは、HadoopシステムのファイルシステムであるHDFS上にあるデータを、仮想的な「外部表」として定義、この外部表に対してSQLで問い合わせを実行できる仕組み(PolyBase)を持っており(関連サイト)、データノードとコンピュータノードがn対nで並列に処理を行う。これにより、Hadoopシステムが保持する非構造データと、通常のデータベース側で持つ構造化データとを意識することなく、同一のインターフェイス上で操作できるようになるという。
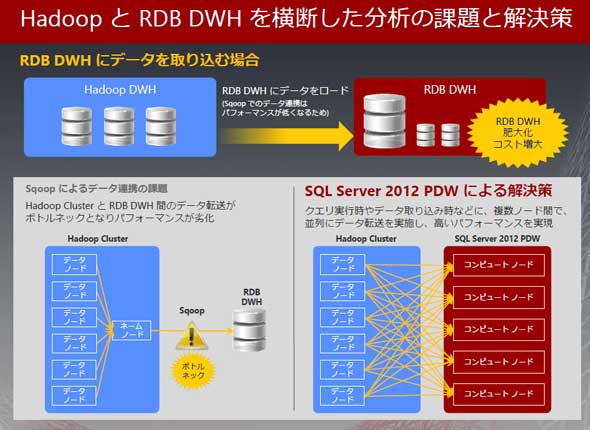
また、PDWは、Windows Serverの仮想化機構であるHyper-Vのテクノロジも使っており「管理ノードなど、負荷の高くないものを仮想化して集約すればコスト削減効果も高い」(斎藤氏)としている。
Hadoopシステムに対してSQLクエリが可能になるソリューションは既に、HiveやImparaなどが存在するが(関連記事1、関連記事2)、これらと比較して、PDWの利点は、他のSQL Serverの機能を組み合わせられる点にある。SQL Serverが持つ多次元分析や、Power Viewによるエンドユーザーコンピューティング環境が使えるのはもちろん、業務部門で根強く支持されているExcelなどのOffice製品群もフロントエンドとして利用できる。
具体的な言及はなかったが、ベースアーキテクチャにHyper-Vを使っていることを考えると、将来的にはPDWのWindows Azure上での展開という方向性も考えられそうだ。Hadoop系ソリューションを提供する企業やホスティング事業者との提携なども今後、発表できる見込みだという。
SSD Applianceについては、2012年12月17日の発表段階では6社が参加していたが、その後、日本アイ・ビー・エム、日立製作所、富士通がそれぞれ製品ラインアップを発表、現在9社の製品から選択ができるようになっており、採用事例も徐々に公開されつつある状況だ。
「エイチ・アイ・エスにおける採用事例では、短期立ち上げや、高負荷となるキャンペーン期間のトランザクションへの対応が証明できた」(斎藤氏)
マイクロソフトのビッグデータ関連製品のロードマップは以下の通り。このうち、HadoopディストリビューションをWindows Azure環境に乗せる「HDInsight Service」については関連記事も参照してほしい。インメモリデータベースを搭載するとされる次期SQL Server(開発コードネーム「Hekaton」、図中のSQL Server vNext)については@ITでも紹介している(関連記事1、関連記事2)。
 ビッグデータ活用に関連するプロダクトのロードマップ
ビッグデータ活用に関連するプロダクトのロードマップマイクロソフトでは、ビッグデータ活用支援施策として、Oracle系システムからの移行アセスメントサービスなどを実施している。また、2012年度から、業種・業態別の組織の他に、ビッグデータ関連ソリューション専門の営業部門を立ち上げ、既に50人体制の営業チームを抱えているという。
関連記事
 課題はデータ管理コスト、DBaaS市場が盛り上がる?
課題はデータ管理コスト、DBaaS市場が盛り上がる?
アイ・ティ・アールによる市場調査では、DWH、DBMSアプライアンス市場の拡大が明確に表れた。今後はDBaaS市場も活性化するという分析も。 100万件以上の口座情報をSQL Server 2008で――セブン銀行
100万件以上の口座情報をSQL Server 2008で――セブン銀行
セブン銀行の100万件の口座情報はSQL Server 2008で処理。旧システムと比較して80%のデータ圧縮を実現、バッチ処理を高速化して、今後の顧客拡大、取引増に備える。 Database Watch(2013年1月版):Redshiftがもたらすデータ分析環境の新時代/私的2012年の業界まとめ
Database Watch(2013年1月版):Redshiftがもたらすデータ分析環境の新時代/私的2012年の業界まとめ
2012年末に発表されたAmazon Redshift。ついにデータウェアハウスも格安のWebサービスの1つとして選択できるようになった。今月はRedshiftをウォッチ! SQL Server SSD Appliance、まずは6社から一斉に提供開始
SQL Server SSD Appliance、まずは6社から一斉に提供開始
SQL Server 2012のSSDアプライアンス提供がスタート。組み合わせは6社製品から選択できる
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。