Play 2.x偐傜MySQL偵愙懕偟偰Anorm偱CRUD憖嶌偡傞偵偼丗Scala亄Play 2.0偱Web傾僾儕奐敪擖栧乮7乯乮2/3 儁乕僕乯
Evolutions偱DB偺娗棟
丂僠乕儉偱奐敪傪峴偭偰偄傞偲偒丄DB僗僉乕儅偺曄峏偱嬯楯偟偨偙偲偑偁傞偺偱偼側偄偱偟傚偆偐丅
丂DB傪曄峏偟偨偗偳丄偦傟傪抦傜側偄懠偺儊儞僶乕偺娐嫬偲晄惍崌偑惗偠偰偟傑偭偨傝偡傞偙偲傕偁傞偺偱丄奺儊儞僶乮傑偨偼暋悢偺儅僔儞乯偱DB僗僉乕儅傪摑堦偡傞偙偲偼廳梫偱偡丅
丂Play偼RDBMS偺僗僉乕儅曊楌傪捛愓偡傞曽朄傪帩偭偰偍傝丄忋婰偺傛偆側働乕僗偱桳梡偱偡丅偙偺復偱偼Evolutions傪巊梡偟偰DB僗僉乕儅傪峏怴偟偰傒傑偟傚偆丅
Evolution僗僋儕僾僩偲偼
丂Evolutions偼丄乽Evolution僗僋儕僾僩乿傪巊梡偡傞偙偲偱丄DB偺曄峏傪捛愓偟傑偡丅偙偺僗僋儕僾僩偼堦掕偺儖乕儖偵廬偭偰SQL傪婰弎偡傞僼傽僀儖偱偡丅僨僼僅儖僩偺DB偵懳偟偰Evolution僗僋儕僾僩傪幚峴偟偨偄応崌丄conf/evolutions/default僨傿儗僋僩儕偵僗僋儕僾僩傪曐懚偟傑偡丅
丂僗僋儕僾僩僼傽僀儖偵晅偗傞柤慜偼寛傔傜傟偰偍傝丄嵟弶偺僗僋儕僾僩偼1.sql丄2斣栚偺僗僋儕僾僩偼2.sql偲偄偆傆偆偵丄悢抣傪弴斣偵晅偗偰偄偐側偗傟偽側傝傑偣傫丅
丂僗僋儕僾僩僼傽僀儖偺撪梕偼丄師偺傛偆偵側偭偰偄傑偡丅
# --- !Ups create table foo ( id int(10) not null auto_increment, name varchar(100), primary key(id)); alter table bar add newColumn varchar(10); # --- !Downs drop table foo; alter table bar drop newColumn;
丂Evolution僗僋儕僾僩偼2偮偺晹暘偱峔惉偝傟偰偄傑偡丅乽# --- !Ups乿偲彂偄偰偁傞晹暘偐傜偼丄僗僉乕儅偺曄峏撪梕傪婰弎偟傑偡丅乽# --- !Downs乿偲彂偄偰偁傞晹暘偐傜偼丄Ups晹暘偺曄峏傪尦偵栠偡偨傔偺婰弎偟傑偡丅
丂Ups傕Downs傕丄忋婰偺傛偆偵僐儊儞僩偱嬫愗傜側偗傟偽偄偗傑偣傫丅
丂傑偨丄師偺忦審傪枮偨偡応崌丄Evolution愝掕偑帺摦偱桳岠壔偝傟傑偡丅
- DB愝掕偑乽conf/application.conf乿偱峴傢傟偰偄傞
- Evolution僗僋儕僾僩偑強掕偺僨傿儗僋僩儕偵懚嵼偡傞
丂傕偟Evolution傪柍岠壔偟偨偄応崌丄conf/application.conf偱丄壓婰愝掕傪捛壛偟偰偔偩偝偄丅
evolutionplugin=disabled
丂奐敪儌乕僪偱偼丄Evolution偑桳岠壔偝傟偰偄傞偲偒丄僗僉乕儅偺忬懺偼儕僋僄僗僩偛偲偵僠僃僢僋偝傟傑偡丅偦偺嵺偵僗僉乕儅偑嵟怴忬懺偱側偄偲敾抐偝傟偨応崌丄SQL傪幚峴偟偰僗僉乕儅傪峏怴偝偣傞傛偆偵懀偡儁乕僕偑僽儔僂僓偵昞帵偝傟傑偡丅
仸杮斣儌乕僪偺応崌丄傾僾儕働乕僔儑儞婲摦慜偵僗僉乕儅偑僠僃僢僋偝傟傑偡
Evolutions偱僨乕僞儀乕僗傪嶌惉
丂偱偼丄Evolutions傪巊梡偟偰丄僗僉乕儅偺峏怴傪偟偰傒傑偟傚偆丅傑偢偼儐乕僓乕忣曬傪娗棟偡傞僥乕僽儖傪嶌惉偟傑偡丅conf/evolutions/default僨傿儗僋僩儕偵丄乽1.sql乿偲偄偆柤慜偱師偺傛偆側僼傽僀儖傪抲偒傑偟傚偆丅
# --- !Ups create table User ( id int(10) not null auto_increment, name varchar(100), email varchar(100), password varchar(100), createDate timestamp default current_timestamp(), primary key(id)); # --- !Downs drop table User;
丂Play僐儞僜乕儖偱傾僾儕傪婲摦偟丄乽http://localhost:9000乿偵傾僋僙僗偟偰傒傑偟傚偆丅師偺傛偆側丄Evolution僗僋儕僾僩傪幚峴偡傞傛偆偵懀偡儁乕僕偑昞帵偝傟傑偡丅
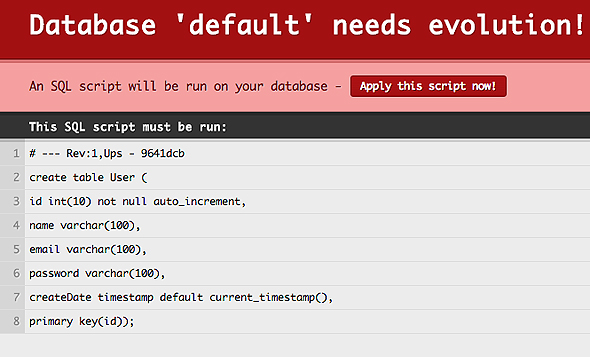 Evolution僗僋儕僾僩夋柺
Evolution僗僋儕僾僩夋柺丂乽Apply this script now!乿偲婰弎偝傟偨儃僞儞傪墴偡偲丄1.sql偺撪梕偑幚峴偝傟偰僗僉乕儅偑嵟怴忬懺偵側傝傑偡丅mysql偺僐儞僜乕儖偱妋擣偟偰傒傞偲丄User僥乕僽儖偑嶌惉偝傟偰偄傞偺偑暘偐傝傑偡丅
丂側偍丄乽play_evolutions乿偲偄偆柤慜偺僥乕僽儖傕嶌惉偝傟偰偄傑偡丅偙傟偼Evolutions偑僗僉乕儅傪娗棟偡傞偨傔偵巊梡偡傞僥乕僽儖偱偡丅
丂懕偗偰丄儐乕僓乕偑億僗僩偟偨僨乕僞傪娗棟偡傞僥乕僽儖傪嶌惉偟傑偡丅2.sql傪師偺撪梕偱嶌惉偟丄conf/evolutions/default僨傿儗僋僩儕偵抲偒傑偟傚偆丅
# --- !Ups create table Post ( id int(10) not null auto_increment, userId int(10) not null, title varchar(100) not null, body text, createDate timestamp default current_timestamp(), primary key(id), foreign key(userId) references USer(id) ); # --- !Downs drop table Post;
丂乽http://localhost:9000乿偵傾僋僙僗偡傞偲丄愭傎偳偲摨偠偔Evolution僗僋儕僾僩偺幚峴傪懀偡儁乕僕偑昞帵偝傟傞偺偱丄僗僋儕僾僩傪幚峴偟傑偟傚偆丅User僥乕僽儖偲Post僥乕僽儖偑偱偒偨傜丄弨旛偼姰椆偱偡丅
丂偙偺復偱傗偭偰偒偨傛偆偵丄Evolutions婡擻傪巊梡偡傞偙偲偱丄僗僉乕儅偺忬懺傪庤寉偵摨婜偝偣傞偙偲偑偱偒傑偡丅Evolutions偵偮偄偰偺徻嵶偼丄岞幃僒僀僩偺乽Documentation: Evolutions 乗 Playframework乿偱傕妋擣壜擻偱偡丅
Play Scala偱偺DB傾僋僙僗
丂Play2偱偼丄DB偵傾僋僙僗偡傞偨傔偺曽朄偼摿偵寛傑偭偰偄傑偣傫丅僶儞僪儖偝傟偰偄傞乽Anorm乿偲偄偆儔僀僽儔儕傪巊梡偟偨傝丄乽Slick乿側偳偺僒乕僪僷乕僥傿惢儔僀僽儔儕傪巊梡偡傞偙偲傕偱偒傑偡乮Play2-Java偱偼丄乽EBean乿偲偄偆ORM偺巊梡偑壜擻偱偡乯丅
丂杮復偱偼丄Anorm傪巊梡偟偰丄Play2偱偺DB傾僋僙僗傪峴偭偰傒傑偟傚偆丅
Play Scala偵偍偗傞僨乕僞僜乕僗傗僐僱僋僔儑儞傪庢摼
丂傑偢偼丄Play偱DB傾僋僙僗傪巊梡偡傞曽朄偵偮偄偰夝愢偟傑偡丅DB傾僋僙僗傪偡傞偵偼丄play.api.db僷僢働乕僕偺DB僋儔僗傪巊梡偟偰僨乕僞僜乕僗傗僐僱僋僔儑儞傪庢摼偟傑偡丅
import play.api.db._ 丒 丒 丒 //僨乕僞僜乕僗庢摼 val ds = DB.getDataSource() //僐僱僋僔儑儞庢摼 val con = DB.getConnection()
丂忋婰庤朄偱僨乕僞僜乕僗傗僐僱僋僔儑儞傪庢摼偱偒傑偡偑丄巊偄廔傢偭偨屻偼帺暘偱close()娭悢傪屇傃弌偡昁梫偑偁傝傑偡丅側偺偱丄壓婰偺傛偆側婰弎傪梡偄偰DB偵傾僋僙僗偡傞偺偑悇彠偝傟偰偄傑偡丅
//default僨乕僞儀乕僗偵傾僋僙僗
DB.withConnection { implicit conn =>
// DB傾僋僙僗張棟
}
丂僽儘僢僋撪偺張棟傪敳偗傞偲丄Connection偲偲傕偵Statement丄ResultSet傕close偝傟傑偡丅傑偨丄default埲奜偺DB傪巜掕偟偨偄応崌丄withConnection偺戞1堷悢偱巜掕偟傑偡丅
丂偝傜偵丄withTransaction娭悢傪巊梡偡傞偙偲偱丄僽儘僢僋偺張棟傪1偮偺僩儔儞僓僋僔儑儞偲偝偣傞偙偲偑偱偒傑偡丅
DB.withTransaction { implicit conn =>
// 偙偺僽儘僢僋偺張棟偼1偮偺僩儔儞僓僋僔儑儞偲側傝傑偡
}
丂偝偰丄僐僱僋僔儑儞偺埖偄曽偼暘偐偭偨偺偱丄Anorm偵偮偄偰夝愢傪偟傑偟傚偆丅
Anorm偲偼
丂Anorm傪巊梡偡傞偲丄SQL傪偦偺傑傑巊梡偟偰DB偵傾僋僙僗偱偒傑偡丅偝傜偵丄寢壥僨乕僞傪僷乕僗偡傞偨傔偺婡擻傕帩偭偰偄傑偡丅偙偺愢柧偐傜暘偐傞傛偆偵丄Anorm偼ORM偱偼偁傝傑偣傫丅DB偵傾僋僙僗偡傞偨傔偵DSL偼堦愗昁梫側偔丄SQL傪偦偺傑傑巊梡偟傑偡丅
丂傑偨丄Anorm偼JDBC僨乕僞傪Scala偺僨乕僞峔憿傊曄姺偡傞偨傔偺API傪採嫙偟偰偔傟傑偡丅
丂Anorm偼婛懚偺DB儔僀僽儔儕偲斾妑偡傞偲丄偪傚偭偲庢偭晅偒偵偔偄晹暘偑偁傞偐傕偟傟傑偣傫偑丄Anorm偺API傪Scala偐傜巊梡偡傞偙偲偱丄SQL偺幚峴傗庢摼偟偨僨乕僞僙僢僩偺僷乕僗張棟傪僔儞僾儖偐偮廮擃偵婰弎壜擻偱偡丅
丂師儁乕僕偱偼丄婎杮揑側Anorm偺巊梡曽朄傪尒偰傒傑偟傚偆丅
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅